

读书记录4:人间失格
《人间失格》(又名《丧失为人的资格》)日本小说家太宰治创作的中篇小说,发表于1948年,是一部半自传体的小说。
1 前言在读这本书之前一直都知道这本书,读了之后才发现这是一个中篇小说,没有那么长,读完感触很深,其中生活中没有很多人那么关注你,所以你也没有必要去在意别人对你的评价。别人夸了你能怎么样,别人诋毁你又能怎么样,so what?
走自己的路,让别人说去吧。
2 经典语录
生而为人,对不起。
丑角本质上只是一层伪装,是为了自我保护而戴上的面具。
一有机会,人类可怕的真面目就会在愤怒中不经意地暴露出来。
在所谓人世间摸爬滚打至今,我唯一愿意视为真理的,就只有这一句话:一切都是会过去的。
我的不幸,恰恰在于我缺乏拒绝的能力。我害怕一旦拒绝别人,便会在彼此心里留下永远无法愈合的裂痕。
相互轻蔑却又彼此来往,并一起自我作贱,这就是也上所谓“朋友”的真面目。
相遇总是措不及防,离别都是蓄谋已久。我们要习惯身边的忽冷忽热,也要看淡那些渐行渐远。
每天面对同样的事情,不过度欢喜,自然就不会感到过度的悲哀。
我得死,我必须得死,活着便是罪恶的种子。
没有人在遭受别人责难与训斥时,还能愉快 ...
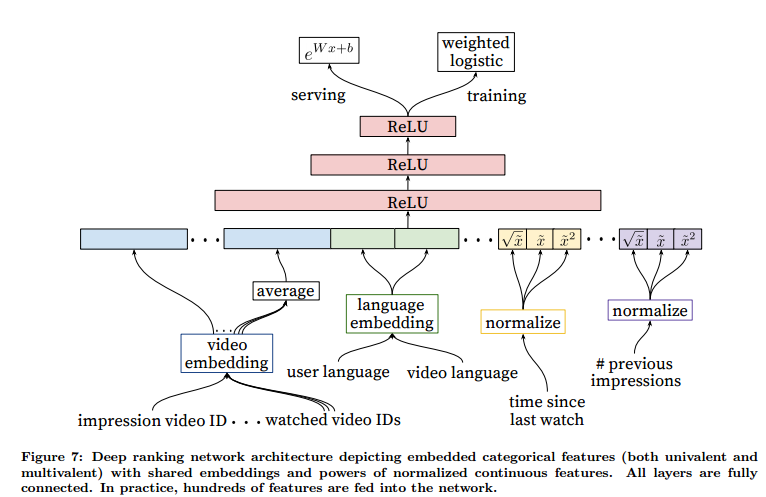
论文精读5:DNN for YouTube Rec
论文题目:Deep Neural Networks for YouTube Recommendations作者:Google发表时间:2016年
DNN for YouTube Rec
YouTube 代表存在规模最大、最复杂的工业推荐系统之一。在本文中,我们以顶层视角描述系统,并专注于深度学习带来的显着性能改进。本文根据经典的两阶段信息检索二分法进行分割:首先,我们详细介绍了深度召回模型,然后描述了单独的排序模型。我们还提供了从设计、迭代和维护大量具有巨大面向用户影响的推荐系统中获得的实际经验和见解。
1 介绍YouTube 是世界上最大的创作、分享和观看视频的平台。YouTube 的推荐系统负责帮助超过 10 亿用户从不断增多的视频库中找到自己感兴趣的内容。在本文中,我们将重点关注深度学习最近对 YouTube 视频推荐系统的巨大影响。图1展示了移动端YouTube在主页推荐视频的页面。
图 1:移动端YouTube在主页推荐视频的页面。
YouTube 的视频推荐遇到的困难主要有三个方面:
推荐的规模:许多现有的推荐算法被证明在小规模问题上工作良好,无法在我们的规 ...

Linux服务器使用clash配置VPN
之前配置过服务器的VPN,但是最近在一个新的服务器上重新配置的时候总是不成功。经过一番努力,最终成功配置VPN,特此记录。
1 下载 clash 安装包首先需要为服务器下载 clash 安装包,进入 Clash Releases 网站选择红色的两个其中之一进行下载。
如果服务器有界面,则可以直接使用服务器的浏览器进行下载。如果没有,则先使用自己的电脑下载后,传输到服务器中。
下载之后进行解压,得到文件 clash-linux-amd64-v3-v1.18.0。
1gunzip clash-linux-amd64-v3-v1.18.0.gz
使用 mv 命令将其重命名为 clash,方便之后使用。
1mv clash-linux-amd64-v3-v1.18.0 clash
之后增加 clash 程序执行的权限:
1chmod +x clash
此时还不能运行 clash,因为我们还少两个文件:
config.yaml:配置文件
Country.mmdb:包含 IP 地址到国家的映射,Clash 利用这个文件来识别用户的 IP 地址所在的国家或地区
接下来分别介绍如何获取这 ...

读书记录3:斯通纳
《斯通纳》是美国当代作家约翰·威廉姆斯创作的长篇小说,首次出版于1965年。
1 前言9月初的时候就读完了这本书,现在有时间写下读书感悟。这本书可以说是我的启蒙读物,在读这本书之前是没有读书的习惯,当时看这本书的时候感觉很有意思,里面有一些片段仿佛就是我的个人写照,一个人穷极一生,应该听从内心的召唤,活出自己的本色。
2 经典语录
爱不是最终目标而是一个过程,借助这个过程,一个人想去了解另一个人。
从长远看,各种东西,甚至让他领悟到这点的这份学问,都是徒劳和一场空,而且最终要消解成一片他们撼动不了的虚无。
我们最终还是属于这个世界,我们应该早知道这点。我相信我们是知道的,但我们得退出来一点,假装一点。
他发现自己有些迷茫,怀疑生活是否值得过下去,是否曾经有过生活。
斯通纳还非常年轻的时候,认为爱情就是一种身心的纯粹状态。
你必须牢记自己是什么人,你选择要成为什么人,记住你正在从事的东西的重要意义。
你对我的百般注解,构不成万分之一的我,却是一览无余的你。
感官突然被打开了,也就是诗突然找上了他,从此感受力都不一样了。
年纪更大些的时候,回首自己本科前两年,斯通纳仿佛感觉那段时光 ...

计算机岗位双选会调研感悟
1 前言东秦在 2024年10月25日 举办了秋季双选会,秋季双选会是一个为大学生提供就业机会的招聘活动,为应届生与用人单位进行面对面交流,了解职业发展方向和行业动态,并与企业达成就业意向。同时老师给我一个任务:对一部分企业针对我们学院(计算机与通信工程学院)的相关专业的招聘情况进行一下调研。
刚接到这个任务的时候我感觉这是一个很好的机会,想趁着这个机会了解一下现在计算机专业应届生的求职情况。从大概九点多开始,一直调研到下午一点,这个时间段也是双选会最火爆的一个时间段,人特别多,摩肩接踵,很多企业的摊位前排了很长的队伍。
当时在想,如果我也直接工作的话肯定也成为这十万大军中的一员,能明显感受到求职者对于找工作的热情。三年之后我也要找工作,我就在想,为什么不从现在就开始为找工作做准备呢?为什么大二的时候不确定自己以后是工作还是考研?如果工作的话为什么不早点准备呢?人这一辈子不论上多少年的学,总是要找一份工作的,我们上学的目的不就是为了找工作吗?
经过对大概20多家企业的调研和这个过程中自己的所见所闻,感受颇深,将这些感想写下,希望对自己的人生规划有帮助。
2 企业岗位需求在我调研的企 ...

WSS推荐系统学习笔记12:涨指标的方法2
1 提升多样性可以通过提升多样性来提高指标,包括排序多样、召回多样性和探索流量。
1.1 排序多样性1.1.1 精排多样性精排阶段,结合兴趣分数和多样性分数对物品 $i$ 排序。
$s_i$:兴趣分数,即融合点击率等多个预估目标
$d_i$:多样性分数,即物品 $i$ 与已经选中的物品的差异
根据加和 $s_i+d_i$ 对物品做排序。
常用 MMR、DPP 等方法计算多样性分数,精排使用滑动窗口,粗排不使用滑动窗口。因为精排决定最终的曝光,曝光页面上邻近的物品相似度应该小,所以计算精排多样性要使用滑动窗口。粗排要考虑整体的多样性,而非一个滑动窗口中的多样性。
除了多样性分数,精排还使用打散策略增加多样性。
类目:当前选中物品 $i$,之后 5 个位置不允许跟 $i$ 的二级类目相同
多模态:事先计算物品多模态内容向量表征,将全库物品聚为 1000 类;在精排阶段,如果当前选中物品 $i$,之后 10 个位置不允许跟 $i$ 同属一个聚类,因为一个聚类中的图片和文字相似,应该被打散
1.1.2 粗排多样性粗排给 5000 个物品打分,选出 500 个物品送入精排。提升粗排和精排 ...

WSS推荐系统学习笔记11:涨指标的方法1
1 概述1.1 推荐系统的评价指标日活用户数(DAU)和留存是最核⼼的指标,目前工业界最常用 LT7 和 LT30 衡量留存。
假设某用户今天($t_0$)登录 APP,未来 7 天($t_0 \sim t_6$)中有 4 天登录 APP,那么该用户今天($t_0$)的 LT7 等于 4。对于所有今天登录的用户,取 LT7 的平均就是整个 APP 今天的 LT7指标。LT30 的定义也是类似的,很显然有 $1 ≤ \operatorname{LT7} ≤ 7$ 和 $1 ≤ \operatorname{LT30} ≤ 30$。
像抖音小红书这样的推荐系统,算法工程师最重要的目标就是提升 LT。LT 的增长通常意味着用户体验提升(除非 LT 增长且 DAU下降)。假设 APP 禁止低活用户登录,则 DAU 下降,LT 增长。由于 LT 存在这种问题,所以如果模型或者策略的 LT 有所提升,还要看一下 DAU,要确保 DAU 不下降。
其他核⼼指标:用户使用时长、总阅读数(即总点击数)、总曝光数。这些指标的重要性低于 DAU 和留存。比如时长增长,LT 通常会增长。但是时长增长,阅读数、曝 ...

读书记录2:月亮与六便士
《月亮和六便士》是英国小说家威廉·萨默赛特·毛姆创作的长篇小说,成书于1919年。
1 前言在十月初的时候就读完了这本书,第一次了解到这本书是在高中,当时书店里有卖这本书,而且很火,但是自己一直没有读书的习惯,所以从来没看过。现在读完之后给我带来的感受是非常深刻的,一个人可以为自己的理想付出到什么地步,这是让我震惊的。而我的理想又是什么呢?不禁让我发问,最后看到毛姆对斯特里克兰在墙壁上作画的描写,感觉是这本书的高潮。
现在有时间写下此文,希望能一直激励我不断前进。希望我有一个自由的灵魂,随便飞到哪里都可以。
2 经典语录
满地都是六便士,他却抬头看见了月亮。
凡是他维护体面的,都被说成虚伪;凡是他铺陈渲染的,都被当作谎言;凡是对某些事保持沉默的,干脆被斥为背叛。
为了使灵魂安宁,一个人每天至少该做两件他不喜欢的事。
我们为自己荒诞不经的行为,蒙上一层体面的缄默,并不觉得虚伪。
同情心应该像一口油井;惯爱表现同情的人却让它喷涌而出,反而让不幸的人受不了。
文明人践行一种奇怪的才智:他们把短暂的生命浪费在烦琐的事务上。
卑鄙与高尚,邪恶与善良,仇恨与热爱, ...

WSS推荐系统学习笔记10:物品冷启动2
1 Look-Alike 人群扩散1.1 在互联网广告中的应用Look-Alike 起源于互联网广告。假设一个广告主是特斯拉,它们知道Tesla Model 3 典型用户有以下特点:
年龄 25~35
本科学历以上
关注科技数码
喜欢苹果电子产品
把具有上述特点的用户给圈起来,重点在这些用户中投放广告。满足所有条件的用户被称为种子用户,这样的用户数量不是很多。广告主想给一百万个人投放广告,但是我们只圈出几万人,该如何找到其他的目标用户?
可以用到 Look-Alike 人群扩散,对种子用户进行人群扩散找到 Look-Alike 用户,Look-Alike 是一个框架,如何进行扩散,有各种各样的方法。
最重要的问题在于如何计算两个用户的相似度,有一些简单的方法:
UserCF:两个用户有共同的兴趣点
Embedding:两个用户向量的cosine较大
1.2 用于新笔记召回在冷启动中,如果用户有点击、点赞、收藏、转发等行为,说明用户对笔记可能感兴趣。把有交互的用户作为新笔记的种子用户,如果一个用户和种子用户相似,可以把这个笔记推荐给他,用 Look-Alike 在相似用户中扩散 ...

WSS推荐系统学习笔记9:物品冷启动1
1 优化目标&评价指标UGC 比 PGC 更难,因为用户上传的内容质量良莠不齐,而且量很大,很难用人工去评判,很难让运营人员去调控。
为什么要特殊对待新笔记?因为新笔记刚刚那个发布,缺少与用户的交互,导致推荐的难度大、效果差。此外,扶持新发布、低曝光的笔记,可以增强作者发布意愿。
优化冷启的目标:
精准推荐:克服冷启的困难,把新笔记推荐给合适的用户,不引起用户反感。
激励发布:流量向低曝光新笔记倾斜,激励作者发布。
挖掘高潜:通过初期小流量的试探,找到高质量的笔记,给予流量倾斜。
冷启动的评价指标主要包含作者侧、用户侧和内容侧:
作者侧指标:发布渗透率、人均发布量。
用户侧指标:
新笔记指标:新笔记的点击率、交互率。
大盘指标:消费时长、日活、月活。
内容侧指标:高热笔记占比,可以反应出冷启是否能挖掘出优质笔记。
作者侧和用户侧指标是工业界通用的,技术比较好的大厂都会用这两类指标。内容侧指标只有少数几家在用。
冷启动的优化点为优化全链路(包括召回和排序)和流量调控(流量怎么在新物品、老物品中分配)。
1.1 作者侧指标作者侧指标主要有发布渗透率和人均发布量。
1.1 ...


