论文精读3-1:GNN图结构介绍
原文链接:https://distill.pub/2021/gnn-intro/
1 引言
神经网络已适应利用图的结构和属性。我们探索构建图神经网络所需的组件——并激发它们背后的设计选择。
图就在我们身边;现实世界的对象通常是根据它们与其他事物的联系来定义的。一组对象以及它们之间的联系自然地表达为图形。十多年来,研究人员开发了对图数据进行操作的神经网络(称为图神经网络,或 GNN)。最近的发展提高了他们的能力和表达能力。我们开始看到抗菌药物发现等领域的实际应用,例如physics simulations(物理模拟)、fake news detection(假新闻检测)、traffic prediction(交通预测)和recommendation systems(推荐系统)。
本文探讨并解释了现代图神经网络。我们将这项工作分为四个部分。首先,我们看看哪种数据最自然地表达为图表,以及一些常见的示例。其次,我们探讨图表与其他类型数据的不同之处,以及使用图表时必须做出的一些专门选择。第三,我们构建了一个现代 GNN,从该领域历史性的建模创新开始,遍历模型的每个部分。我们逐渐从简单的实现转向最先进的 GNN模型。第四,也是最后,我们提供了一个 GNN的playground,您可以在其中尝试真实的任务和数据集,以对 GNN模型的每个组件如何对其做出的预测做出贡献建立更强烈的直觉。
2 什么是图
首先,让我们先确定什么是图表。图表示实体(节点)集合之间的关系(边)。
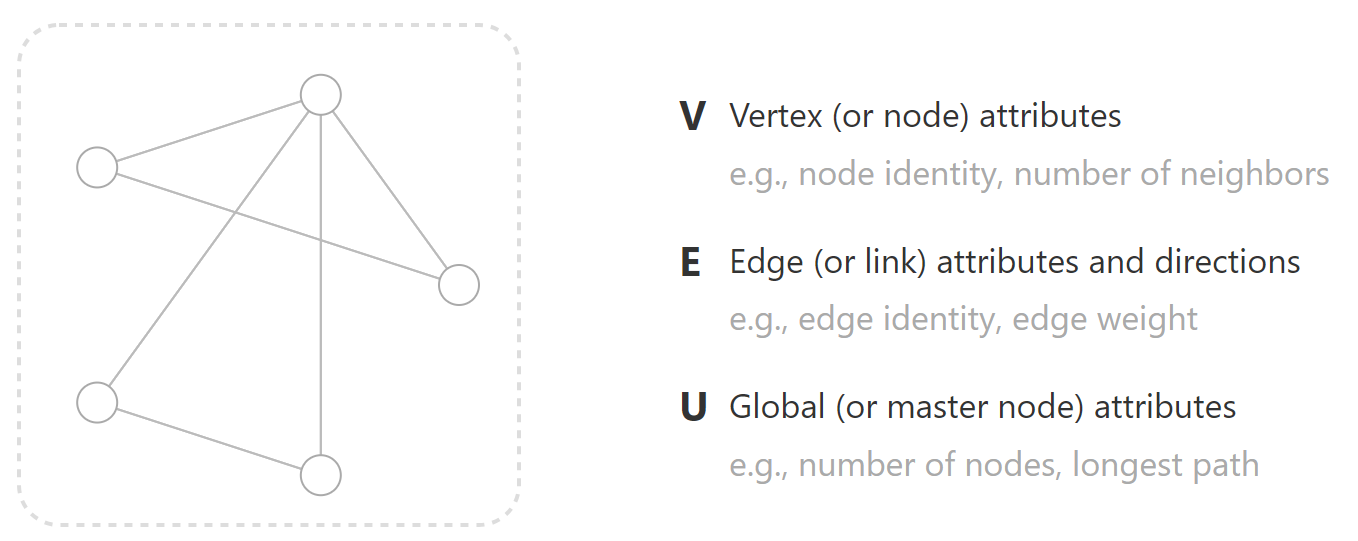
为了进一步描述每个节点、边或整个图,我们可以在图的每个部分中存储信息。
我们还可以通过将方向性与边(有向、无向)相关联来专门化图。

图是非常灵活的数据结构,如果现在这看起来很抽象,我们将在下一节中通过示例将其具体化。
3 图结构以及应用
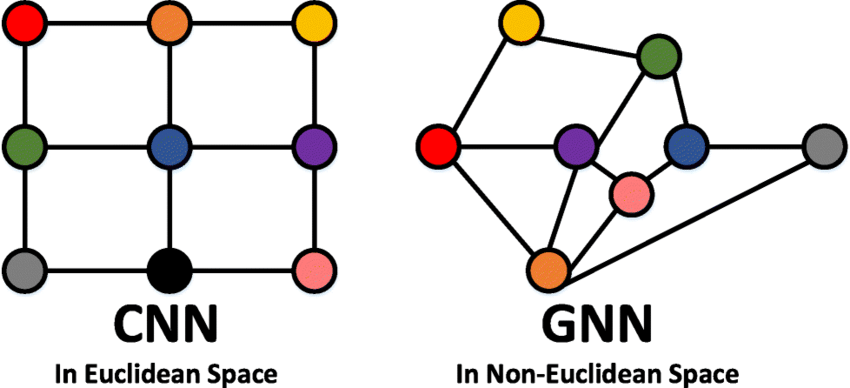
你可能已经熟悉某些类型的图形数据,例如社交网络。然而,图表是一种极其强大且通用的数据表示形式,我们将展示两种您可能认为无法建模为图的数据类型:图像和文本。虽然违反直觉,但人们可以通过将图像和文本视为图形来更多地了解图像和文本的对称性和结构,并建立一种直觉,这将有助于理解其他不太像网格的图形数据,我们将在稍后讨论。
3.1 图片作为图
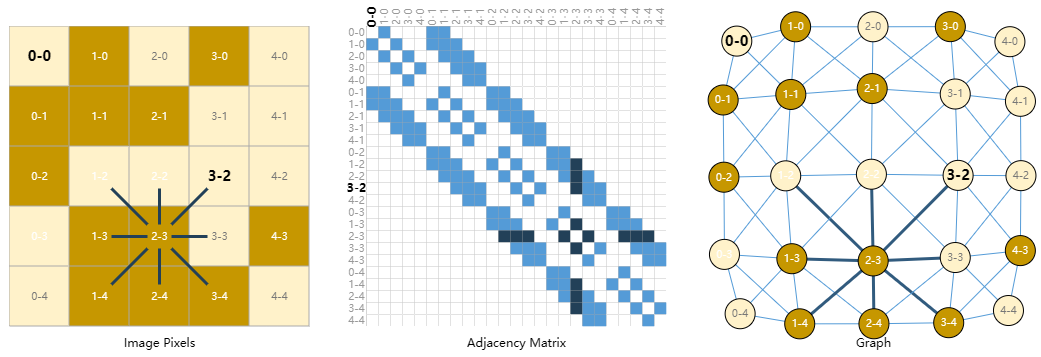
我们通常将图像视为具有图像通道的矩形网格,将它们表示为数组(例如,$244 \times 244 \times 3 $浮点数)。另一种将图像视为具有规则结构的图,其中每个像素代表一个节点,并通过边缘连接到相邻像素。每个非边界像素正好有 8 个邻居,每个节点存储的信息是表示该像素的 RGB值的 3 维向量。
可视化图的连通性的一种方法是通过其邻接矩阵。我们对节点进行排序,在本例中,每个节点是一个简单的$ 5 \times 5$笑脸图像中的 25 个像素,并填充一个矩阵$n_{nodes}×n_{nodes}$。如果两个节点共享一条边,则有一个条目。请注意,下面这三种表示形式都是同一数据的不同视图。
3.2 文本作为图
我们可以通过将索引与每个字符、单词或标记相关联,并将文本表示为这些索引的序列来数字化文本。这将创建一个简单的有向图,其中每个字符或索引都是一个节点,并通过边连接到其后面的节点。
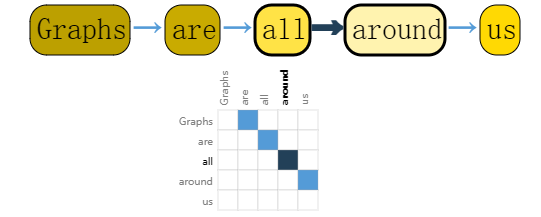
当然,在实践中,这通常不是文本和图像的编码方式:这些图形表示是多余的,因为所有图像和所有文本都将具有非常规则的结构。例如,图像的邻接矩阵具有带状结构,因为所有节点(像素)都连接在网格中。文本的邻接矩阵只是一条对角线,因为每个单词仅连接到前一个单词和下一个单词。
3.3 其他可以表示为图的数据
图表是描述您可能已经熟悉的数据的有用工具。让我们继续讨论结构更加异构的数据。在这些示例中,每个节点的邻居数量是可变的(与图像和文本的固定邻居大小相反)。除了图之外,这些数据很难以任何其他方式表达。
分子作为图
分子是物质的组成部分,由 3D空间中的原子和电子构成。所有粒子都相互作用,但是当一对原子彼此保持稳定的距离时,我们说它们共享共价键。不同的原子对和键具有不同的距离(例如单键、双键)。将这个 3D对象描述为图是一个非常方便且常见的抽象,其中节点是原子,边是共价键。
以下是两种常见的分子及其相关图。

(左)香茅醛分子的
3D表示(中)分子中键的邻接矩阵(右)分子的图形表示

(左)咖啡因分子的
3D表示(中)分子中键的邻接矩阵(右)分子的图形表示
社交网络作为图表
社交网络是研究人们、机构和组织集体行为模式的工具。我们可以通过将个体建模为节点并将他们的关系建模为边来构建表示人群的图。
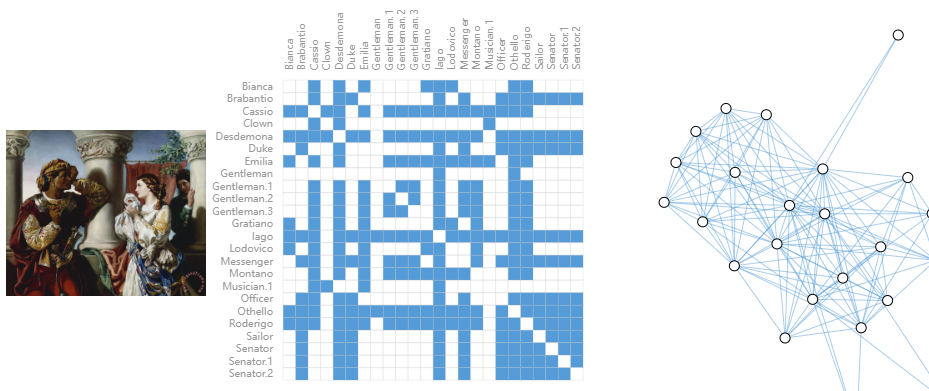
(左)戏剧《奥赛罗》中的场景图像。(中)剧中角色之间互动的邻接矩阵。 (右)这些交互的图形表示。
与图像和文本数据不同,社交网络不具有相同的邻接矩阵。

(左)空手道锦标赛的图片。(中)空手道俱乐部中人与人之间互动的邻接矩阵。(右)这些交互的图形表示。
引用作为图表
科学家在发表论文时经常引用其他科学家的工作。我们可以将这些引用网络可视化为一个图,其中每篇论文都是一个节点,每个有向边是一篇论文与另一篇论文之间的引用。此外,我们可以将每篇论文的信息添加到每个节点中,例如摘要的词嵌入。
其他例子
在计算机视觉中,我们有时想要标记视觉场景中的对象。然后,我们可以通过将这些对象视为节点,并将它们的关系视为边来构建图。机器学习模型,编程代码和数学方程也可以表述为图,其中变量是节点,边是将这些变量作为输入和输出的操作。您可能会在其中一些上下文中看到术语“数据流图”。
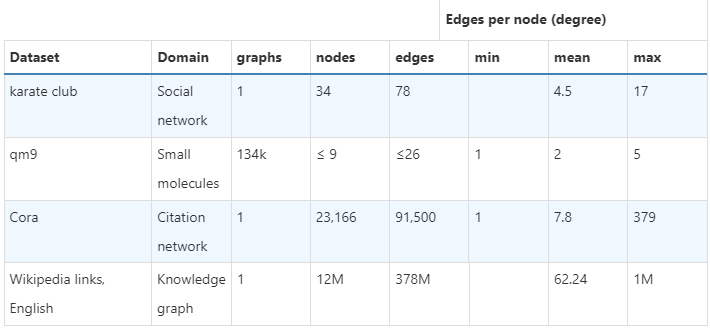
现实世界的图的结构在不同类型的数据之间可能有很大差异——有些图有很多节点,但它们之间的连接很少,反之亦然。图数据集在节点数、边数和节点连接性方面可能存在很大差异(在给定数据集内以及数据集之间)。
对现实世界中发现的图进行汇总统计。数字取决于特征化决策。更多有用的统计数据和图表可以在
KONECT中找到。
4 图结构化数据可以解决哪些类型的问题
我们已经描述了一些自然图表的示例,但是我们想要对这些数据执行什么任务?图上的预测任务一般分为三种类型:图级、节点级和边级。
在图级任务中,我们预测整个图的单个属性。对于节点级任务,我们预测图中每个节点的一些属性。对于边级任务,我们想要预测图中边的属性或存在。
对于上述三个级别的预测问题(图级、节点级和边级),我们将证明以下所有问题都可以使用单个模型类GNN来解决。但首先,让我们更详细地浏览一下三类图预测问题,并提供每一类的具体示例。
4.1 图层面任务
在图级任务中,我们的目标是预测整个图的属性。例如,对于用图表表示的分子,我们可能想要预测该分子闻起来像什么,或者它是否会与与疾病有关的受体结合。
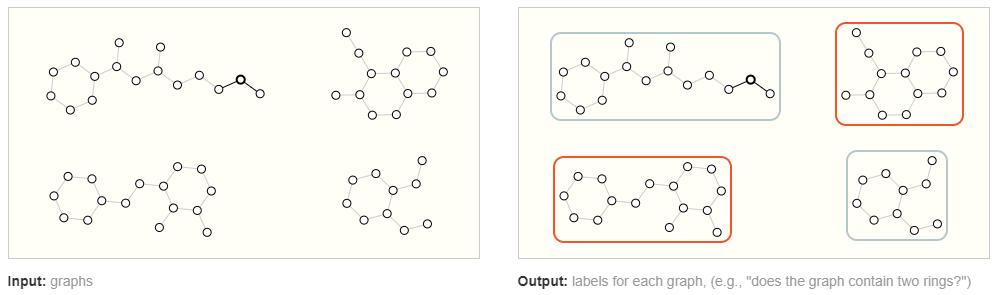
这类似于 MNIST和 CIFAR的图像分类问题,我们希望将标签与整个图像相关联。对于文本,类似的问题是情感分析,我们希望立即识别整个句子的情绪或情感。
4.2 顶点层面任务
节点级任务涉及预测图中每个节点的身份或角色。
节点级预测问题的一个典型例子是扎克的空手道俱乐部。该数据集是一个单一的社交网络图,由在政治分歧后宣誓效忠两个空手道俱乐部之一的个人组成。故事是这样的,Hi 先生(教练)和 John H(管理员)之间的不和在空手道俱乐部中造成了分裂。节点代表各个空手道练习者,边代表空手道之外这些成员之间的互动。预测问题是对给定成员在不和之后是否忠诚于 Mr. Hi 或 John H 进行分类。在这种情况下,节点与讲师或管理员之间的距离与该标签高度相关。
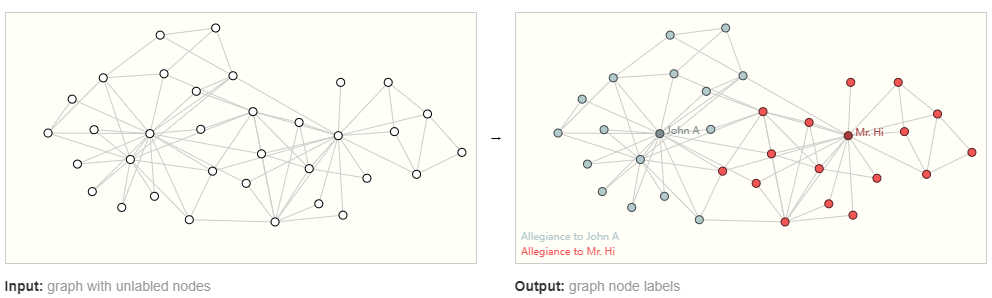
左边是问题的初始条件,右边是可能的解决方案,其中每个节点都根据联盟进行了分类。该数据集可用于其他图问题,例如无监督学习。
按照图像类比,节点级预测问题类似于图像分割,我们试图标记图像中每个像素的作用。对于文本,类似的任务是预测句子中每个单词的词性(例如名词、动词、副词等)。
4.3 边层面任务
图中剩下的预测问题是边缘预测。
边缘级推理的一个例子是图像场景理解。除了识别图像中的对象之外,深度学习模型还可用于预测它们之间的关系。我们可以将其表述为边缘级分类:给定代表图像中对象的节点,我们希望预测这些节点中的哪些共享边缘或该边缘的值是什么。如果我们希望发现实体之间的连接,我们可以考虑完全连接的图,并根据其预测值修剪边缘以得到稀疏图。
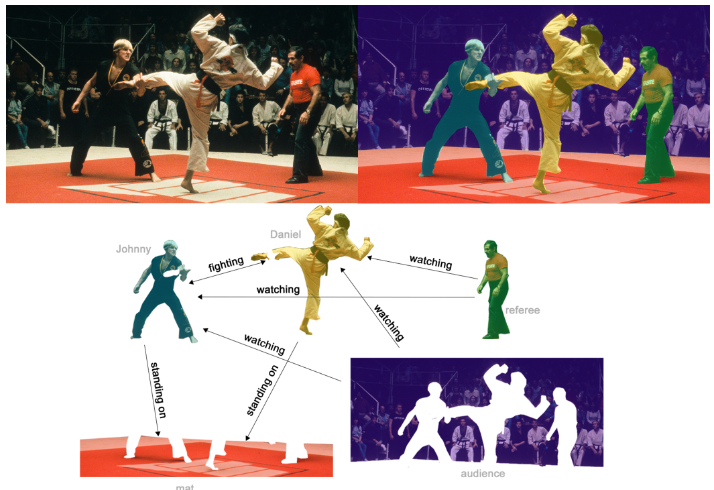
在上面的 (b) 中,原始图像 (a) 被分割为五个实体:每位拳手、裁判、观众和垫子。 (C) 显示了这些实体之间的关系。
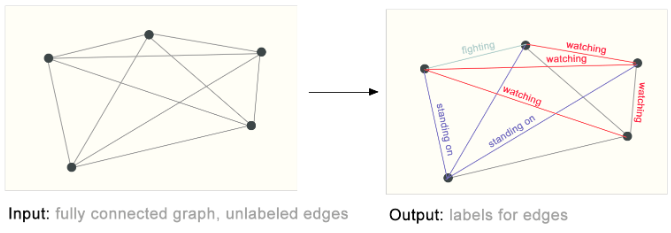
在左侧,有一个根据之前的视觉场景构建的初始图。右侧是当根据模型的输出修剪一些连接时该图可能的边缘标记。
5 在机器学习中使用图的挑战
那么,如何使用神经网络来解决这些不同的图形任务呢?第一步是考虑如何表示与神经网络兼容的图。
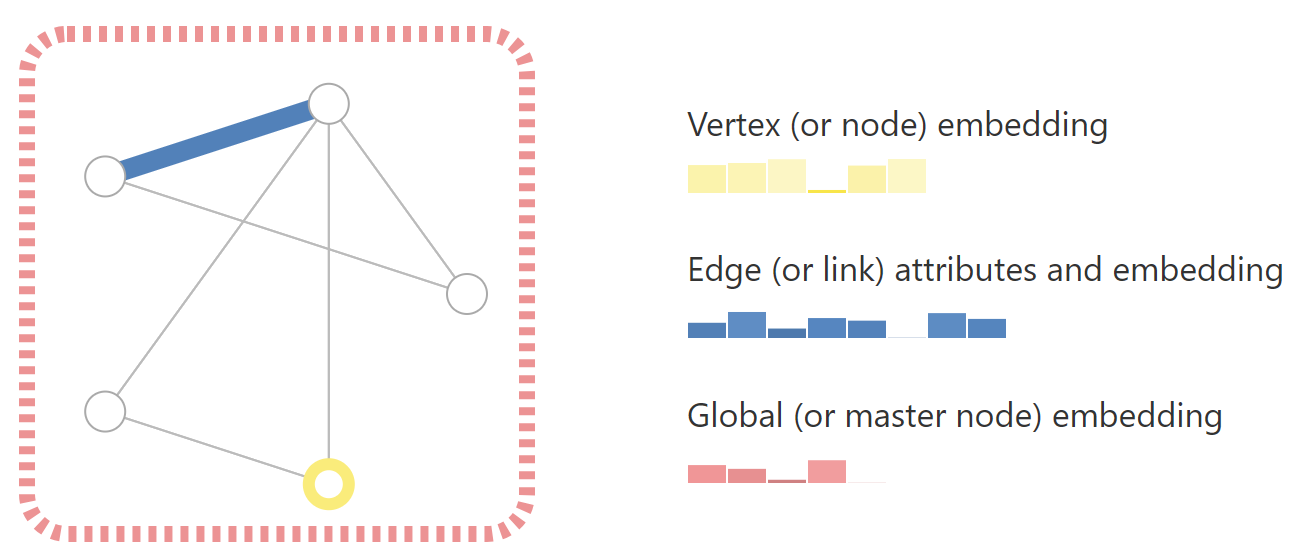
机器学习模型通常采用矩形或类似网格的数组作为输入。因此,如何以与深度学习兼容的格式表示它们并不是立即直观的。图形最多包含四种类型的信息,我们可能希望使用这些信息来进行预测:节点、边、全局上下文和连通性。前三个相对简单:例如,对于节点,我们可以通过为每个节点分配一个索引$i$并将特征存储在$node_i$中来形成结点特征矩阵$N$。虽然这些矩阵的样本数量可变,但无需任何特殊技术即可进行处理。
但是,表示图形的连通性更为复杂。也许最明显的选择是使用邻接矩阵,因为这很容易被拉伸。但是,这种表示方式有一些缺点。从示例数据集表中,我们看到图中的节点数量可能约为数百万个,并且每个节点的边数量可能变化很大。通常,这会导致非常稀疏的邻接矩阵,这在空间上效率低下。
另一个问题是,有许多邻接矩阵可以编码相同的连通性,并且不能保证这些不同的矩阵会在深度神经网络中产生相同的结果(也就是说,它们不是置换不变的)。
例如,之前的奥赛罗图可以等同于这两个邻接矩阵来描述。它也可以用节点的所有其他可能的排列来描述。

表示同一图形的两个邻接矩阵。
下面的示例显示了可以描述这个包含 4 个节点的小图的每个邻接矩阵。这已经是相当多的邻接矩阵——对于像奥赛罗这样的大例子,这个数字是站不住脚的。
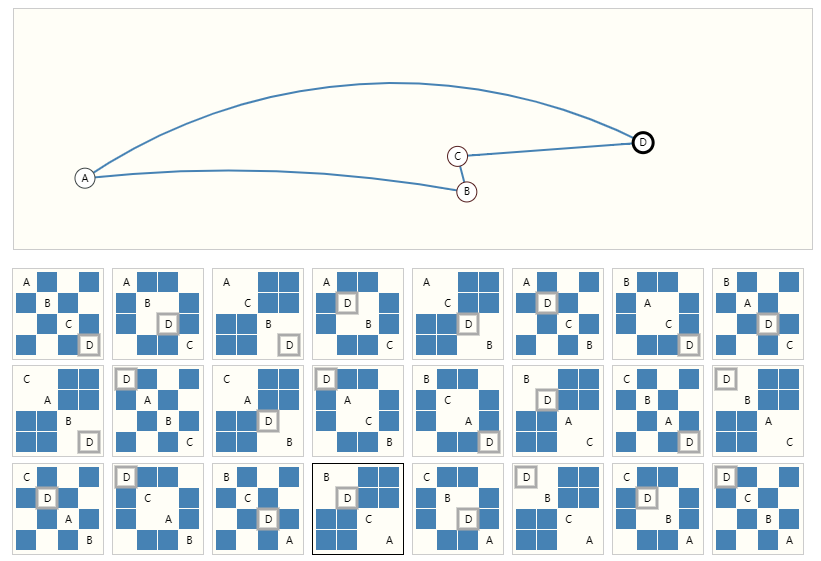
所有这些邻接矩阵都表示同一个图形。单击边以将其删除,在“虚拟边”上添加它,矩阵将相应地更新。
表示稀疏矩阵的一种优雅且节省内存的方法是一种表示邻接列表。它们将节点$n_i$和$n_j$之间的边$e_k$联通性描述为邻接列表的第$k$个条目中的元组$(i,j)$。由于我们预计边的数量远低于邻接矩阵的条目数$(n^2_{nodes})$,因此我们避免了在图形的不连贯部分进行计算和存储。
为了使这个概念具体化,我们可以看到在此规范下如何表示不同图形中的信息:
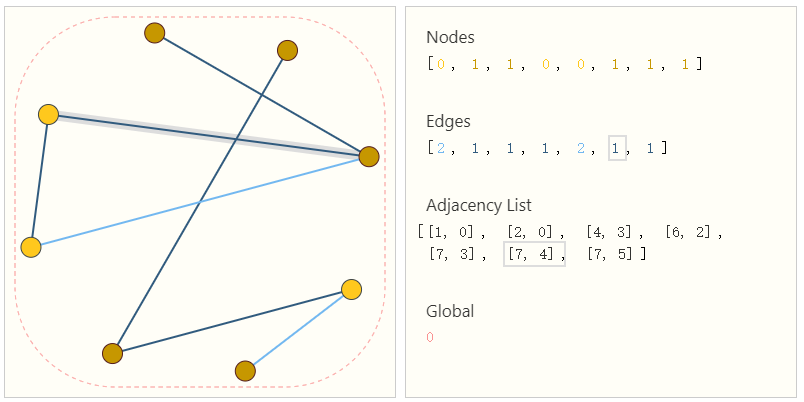
一边是小图,另一边是张量表示中的图信息。
应该注意的是,该图使用每个节点/边/全局的标量值,但大多数实际的张量表示每个图属性都有向量。我们将处理大小为$[n_{nodes},node_{dim}]$的节点张量,而不是大小为$[n_{nodes}]$的节点张量,其他图形属性也是如此。
 微信
微信 支付宝
支付宝