
第二期AI夏令营任务3:实现RAG应用
1 Gradio 技术入门
Gradio是一个开源的 Python 库,用于快速构建机器学习和数据科学演示应用。它使得开发者可以在几行代码中创建一个简单、可调整的用户界面,用于展示机器学习模型或数据科学工作流程。Gradio支持多种输入输出组件,如文本、图片、视频、音频等,并且可以轻松地分享应用,包括在互联网上分享和在局域网内分享.
简单来说,利用 Gradio 库,我们可以很容易实现一个具有对话功能的前端页面,实现最简单人机交互功能。
在目前的深度学习软件开发中,使用gradio熟练展示demo已经成为了基础必备技能,你可以在任何地方(无论是学术还是工业界)见到 gradio 展示,但我们本次可以只从一个简单的对话demo开始,来逐渐展开gradio的熟悉之旅。
我们可以简单的理解为gradio就是在搭积木,或者说简单理解为所有的前端框架都是在利用一块块积木创造出最好的效果。
在gradio中,我们可以把每个组件创建在 gr.Blocks() 包裹的块当中,你可以把它当作一个展示台,我们可以在展示台上放满不同的组件(比如这里的 gr.Button,gr.Textbox 等等),你可以自由组合组件来实现想要的目标。此外,在gradio中同样也有各类可注册事件,这有助于我们在和组件互动时、互动后来指定我们想要发生的事情(比如执行一段函数),比如我们希望按钮按下后执行一个函数,然后根据某些组件的输入输出做反应,我们就可以像下面的 .click 以及 .submit 一样注册相应的事件,根据绑定的函数创作出更多样的可能。
最后,我们只需要launch我们的”展示台“,就可以看到gradio前端展示画面。
1 | import gradio as gr |
2 Streamlit 技术入门
简单来说,Streamlit 是一个Python库,用于快速构建交互式Web应用程序。它提供了一个简单的API,允许开发者使用Python代码来创建Web应用程序,而无需学习复杂的Web开发技术。这听上去是不是与 gradio差不多?
你可以选择自己喜欢的一款前端库来完成对应 AI 应用的开发,如果聪明的你稍加精进,我们甚至可以创造出五彩缤纷的前端界面:


与 gradio 不同的是, streamlit 不需要复杂的 root_path 路由修改操作,我们只需要简单的运行就可以得到结果。
3 RAG应用
3.1 什么是 RAG
什么是 Retrieval-Augmented Generation(RAG)检索增强生成应用? 检索增强生成顾名思义,就是利用检索来增强大模型的生成结果。
具体而言,RAG 主要是在这样的场景下被需要的:想象一下,当你有一个冷门的知识需要理解,但大模型没有基于这个知识训练过,或者说你想把这个知识全部输入大模型进行问答,但是大模型的上下文没有那么长;
那么,我们需要一个好的方法让大模型可以基于我们新的知识进行对话,这就是 RAG的意义所在。
检索增强生成 (RAG) 通过向量数据库检索的方式来获取我们问题预期想要回答涉及的知识,然后结合这个知识让大模型基于知识生成最后的问答结果,满足了我们对提问的真实性需求。
在理解 RAG 之前,我们还需要理解什么是 Embedding。

在机器学习和自然语言处理(NLP)中,Embedding 是一种将非结构化数据,如单词、句子或者整个文档,转化为实数向量的技术。这些实数向量可以被计算机更好地理解和处理。我们可以把一个词(token)表示成有限维度空间中的表示。
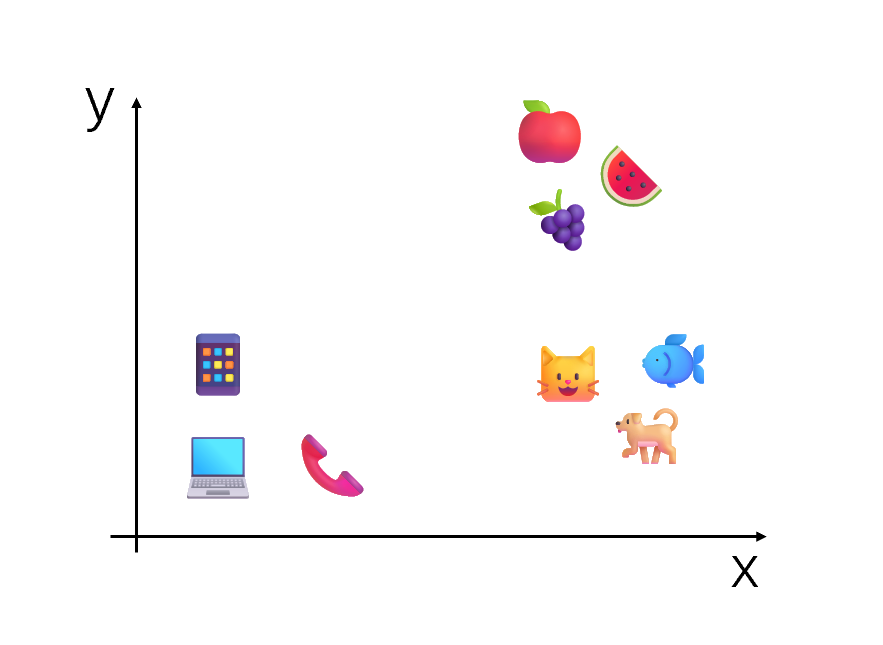
比如,我们可以把苹果映射成 (5,5) ,把梨子映射成 (4,5),把芯片映射到 (1,2)。在这里,坐标的相近表示梨子和苹果的语义有很大的重复成分,而芯片与苹果的距离,自然比梨子与苹果的距离要远。此时这些数字坐标映射就可以理解为简单的 Embedding。
我们可以通过 Embedding 模型,将一个词很方便映射到对应的实数多维表示空间,这个映射关系是提前训练得到的,越准确的 Embedding 模型可以让我们越好的区别不同语义特征的差异性,这也就对 RAG 的准确检索带来了更大的好处。
在搭建 RAG 系统时,我们往往可以通过使用 Embedding 模型来构建词向量,我们可以选择使用各个公司的在线 Embedding API,也可以使用本地嵌入模型将数据构建为词向量;由于我们通常是对文档操作,这里的向量化是对文档块(chunk)进行;我们可以将一个文档分成多个段落,每个段落分别进行 Embedding 操作,得到结果后存储到对应的数据库中保存,以便后续的检索即可。
3.2 向量数据库
而对于数据库,在 RAG 中,我们通常使用的也就是 Embedding 相关的数据库—向量数据库,向量数据库是一种基于向量空间模型的数据库系统,它能够利用向量运算进行数据检索的高效处理。
常见的向量数据库包括 Faiss、Annoy、Milvus等等。这些向量数据库通常与 LLM 结合使用,以提高数据检索和处理的效率。
至此,在理解了 Embedding 之后,我们就理解了 RAG 中的一大核心要素。那么,我们将如何构建一个 RAG 系统?
3.3 如何实现RAG
具体而言,RAG 有很多的实现方式,在这里我们使用最简单的实现方法,他遵循最传统的规则,包括索引创建(Indexing)、检索(Retrieval)和生成(Generation),总的来说包括以下三个关键步骤:
- 语料库被划分成一个个分散的块(chunk),然后使用 embedding 模型构建向量索引,并存储到向量数据库。
- RAG 根据 query(当前提问)与索引块(Indexed Chunk)的向量相似度识别并对块进行检索。
- 模型根据检索块(Retrieved Chunk)中获取的上下文信息生成答案。
RAG也可以被简单的分成几大模块:
- 向量化模块:用来将文档片段向量化
- 文档加载和切分的模块工具:用来加载文档并切分成文档片段。
- 向量数据库模块:用于将向量化后的文档存储到数据库中.
- 检索模块:根据 Query (问题)检索相关的文档片段。
- 大模型模块:结合 Query 及检索出来的文档回答用户的问题。
我们可以用一张图简单理解 RAG 系统做了哪些事情:
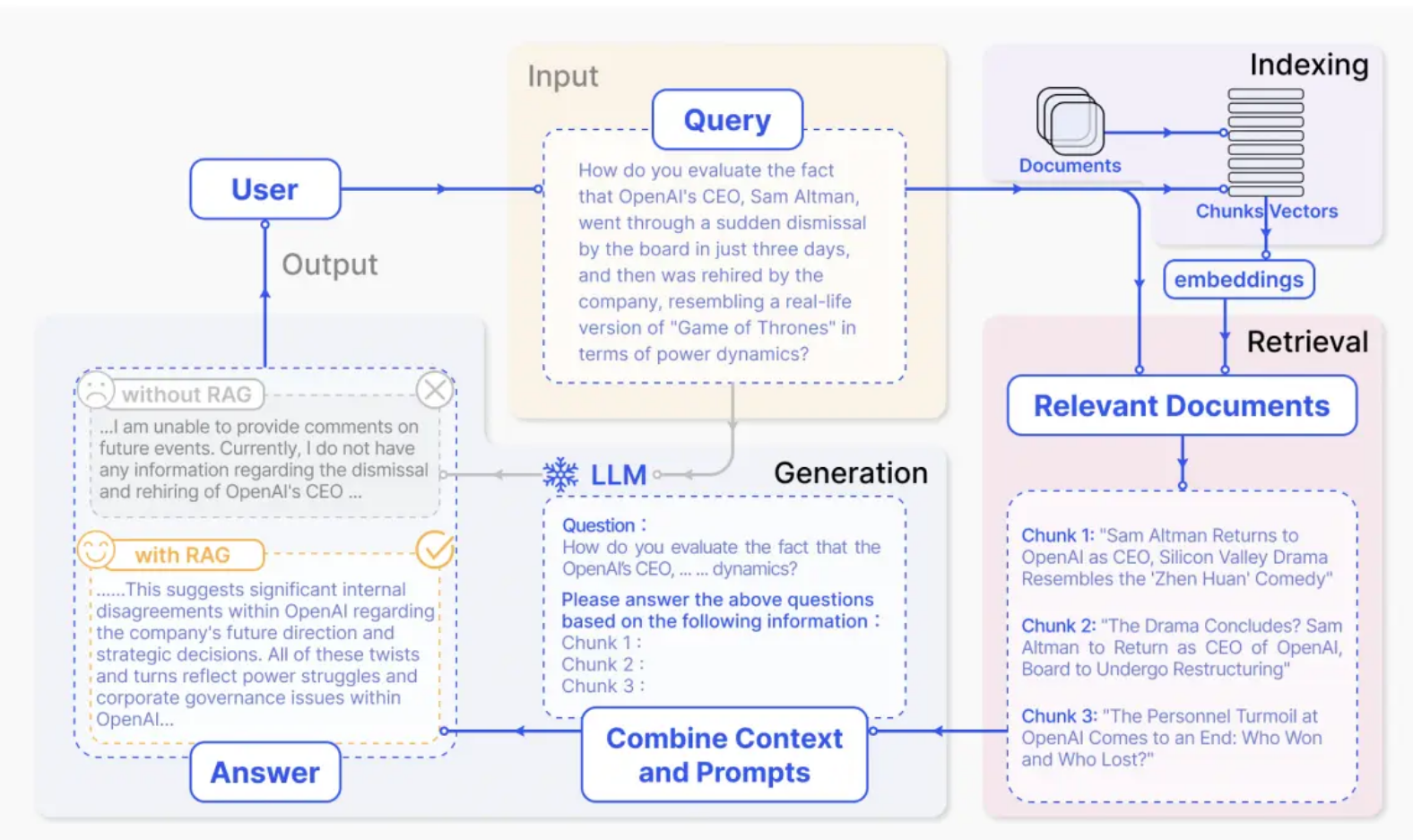
由图可知,我们通过基于提问检索出的知识块,和提问一起拼接输入到大模型问答后,让大模型的回答更加接近我们的提问预期,可靠性大幅度增加。但这也并非 RAG 技术的终点,我们可以通过更多额外方式增强 RAG 的效果,譬如:
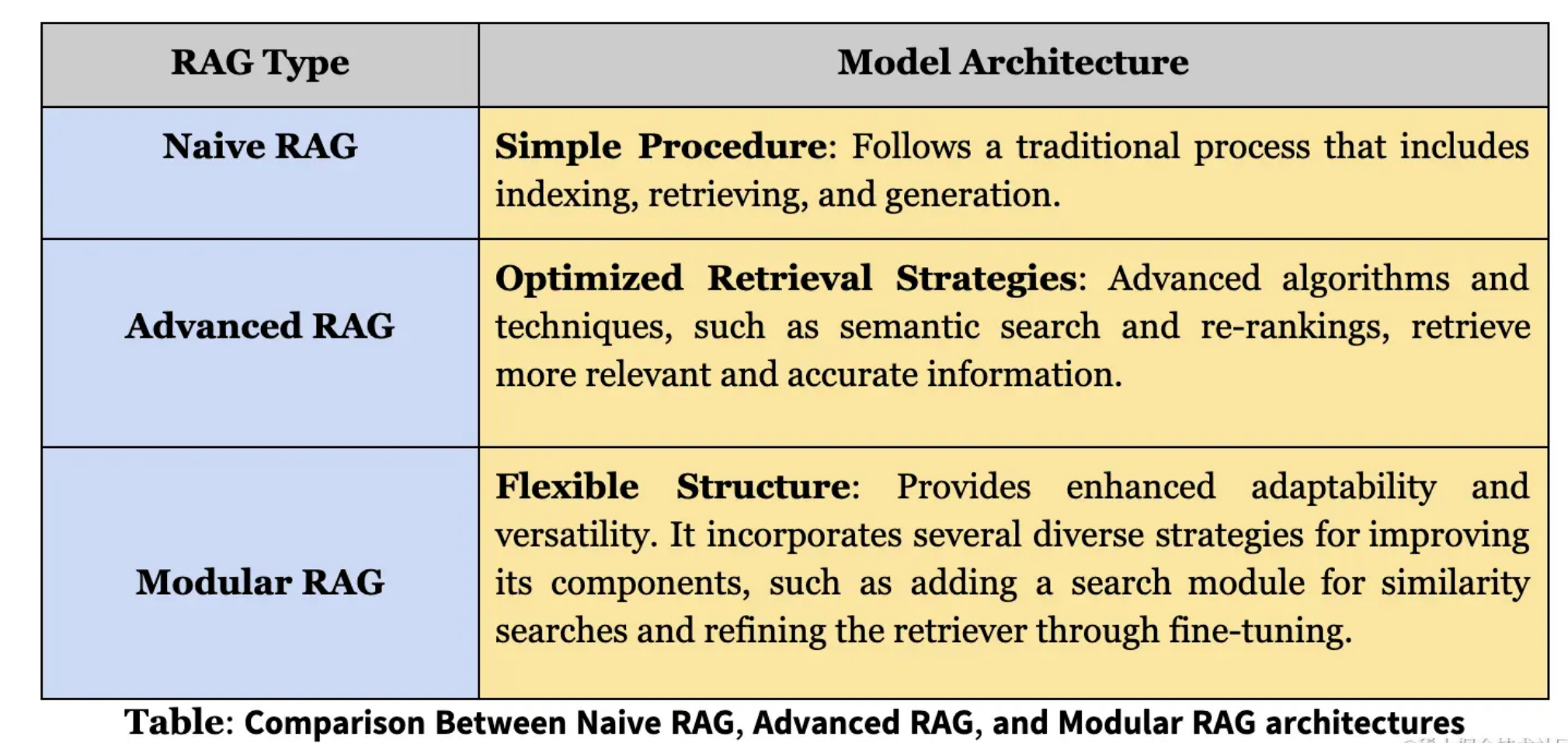
以最简单的“重排技术”为例,我们可以通过检索后重新排布检索的结果,从而提高提高打算使用的检索块与提问的关联度,最终提高问答的生成质量。
在 RAG 架构下,引入重排步骤可以有效改进召回效果,提升 LLM(大语言模型)生成答案的质量。我们可以通过一张图简单理解这一过程:
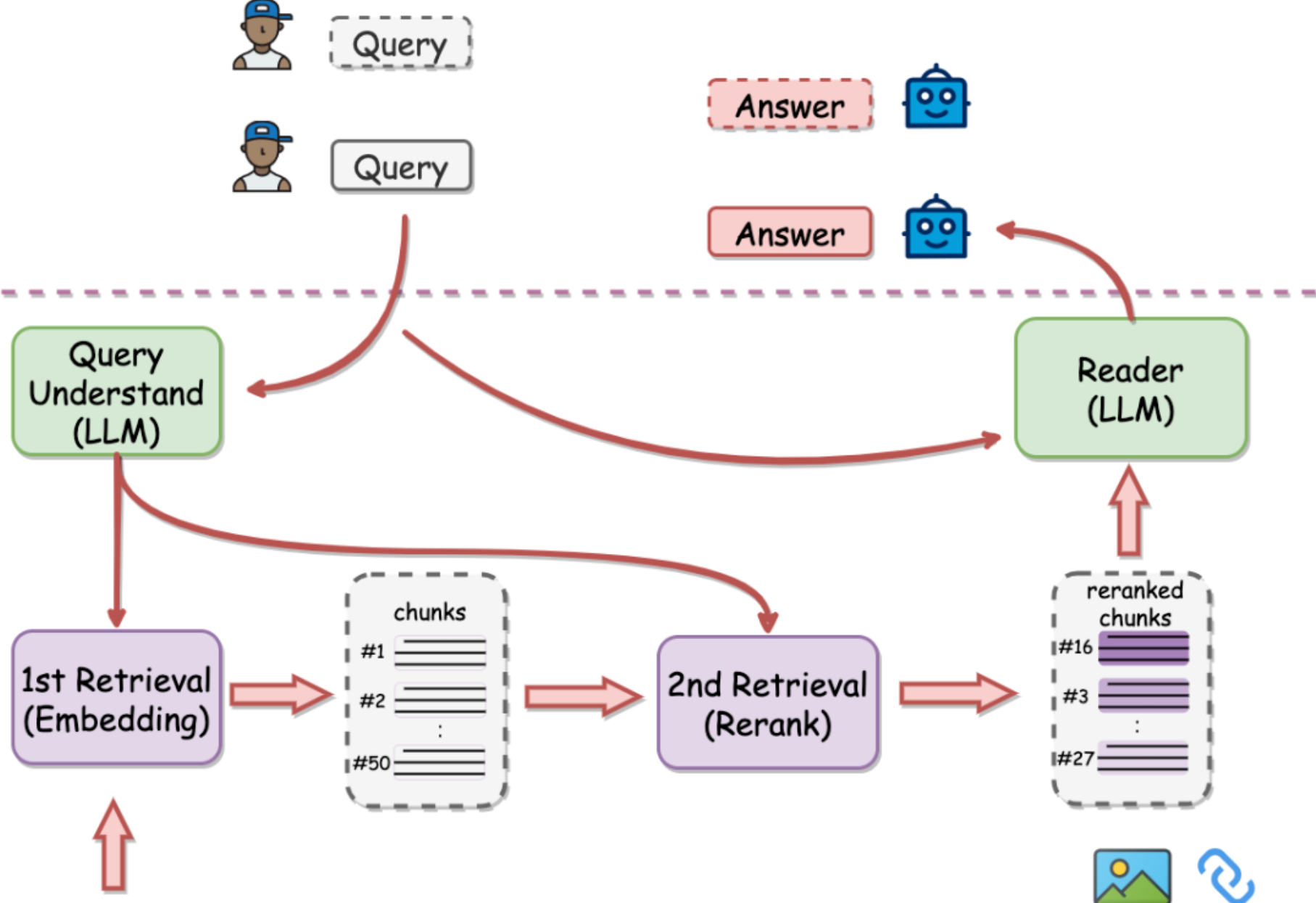
总之,我们可以利用 RAG 技术提高大模型问答最后的生成水平,在强事实要求与上下文不足的情况下仅仅依靠 RAG 就能实现满足预期的效果。接下来,让我们从初级 RAG 开始,一步步探索检索增强生成的应用之路。
4 llamaIndex
4.1 什么是 LlamaIndex

我们将使用 LlamaIndex 进行初级 RAG 系统的搭建演示。LlamaIndex 是一个AI框架,用于简化将私有数据与公共数据集成到大型语言模型(LLM)中的应用程序中。它提供了数据 ingestion、 indexing 和查询的工具,使其成为生成式 AI 需求的可靠解决方案。
LlamaIndex 主要包括以下几个组件:
- 数据连接器:帮助连接现有数据源和数据格式(如 API、PDF 等),并将这些数据转换为
LlamaIndex可用的格式。 - 数据索引:帮助结构化数据以适应不同的用例。加载了来自不同数据源的数据后,如何将它们分割、定义关系和组织,以便无论您想要解决的问题(问答、摘要等),都可以使用索引来检索相关信息。
- 查询接口:是输入查询并从
LLM中获取知识增强输出的接口。
其中,LlamaIndex 有几个重要的高层次抽象结构需要我们理解:
4.2 Indexing
Indexing 是一种数据结构,它允许我们快速检索我们所查询的相关上下文,你可以把它简单理解为一种对“node”的抽象组织方式,在 llamaindex 中存在多种不同的组织 node 的方式。Indexing 将数据存储在 Node 对象(代表原始文档的 chunk )中 ,并公开支持额外配置和自动化的 Retriever 接口。当我们看到 Node 对象的时候,你可以把他简单理解为 chunk。对于 LlamaIndex,它是检索增强生成(RAG)用例的核心基础。
- Keyword Table Index
- Tree Index
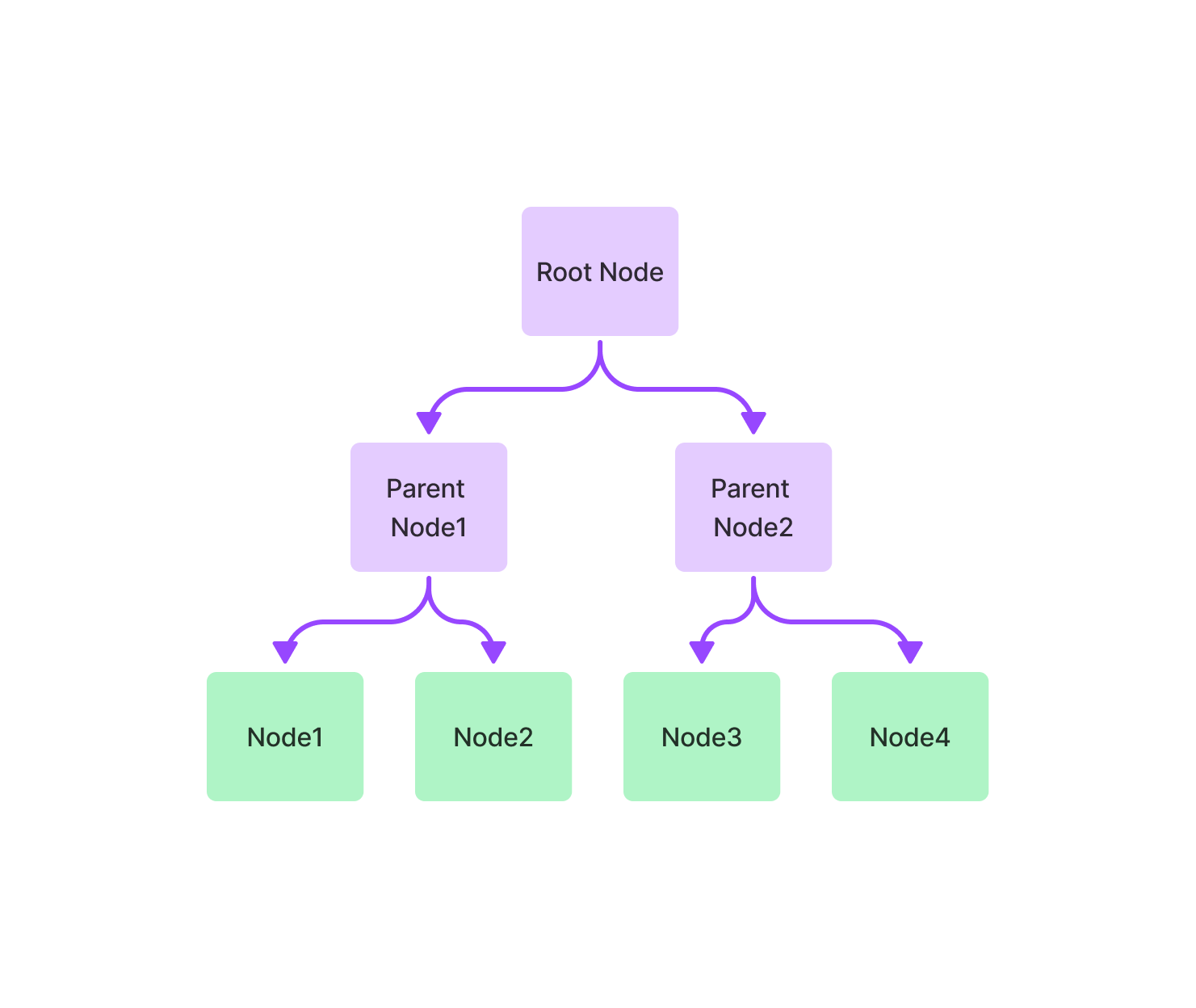
- Vector Store Index
在高层次上,Indexing 是从 Documents 构建的 node 组成的。它们用于构建 Query Engine 等,可以通过您的数据进行问答和聊天。
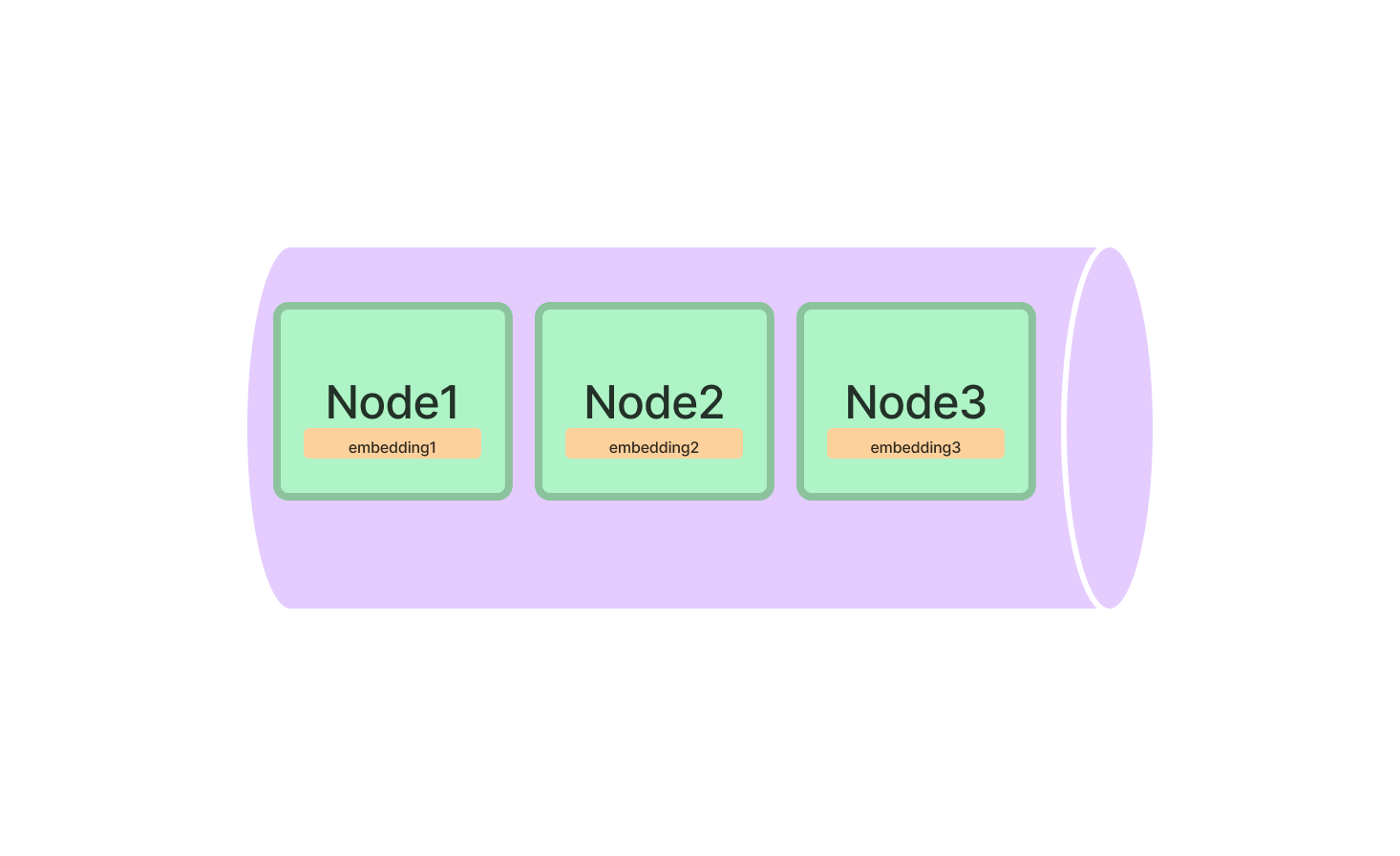
4.3 Vector Stores
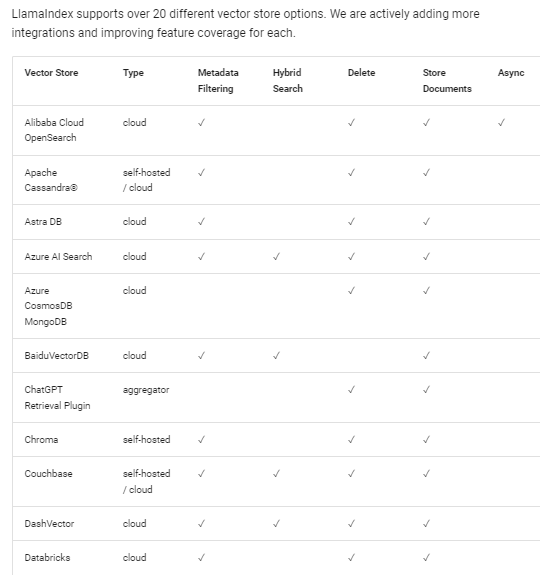
Vector Stores 负责收纳 chunks 的嵌入向量。默认情况下,LlamaIndex 使用一个简单的内存向量存储,非常适合快速实验。它们可以通过调用 vector_store.persist() 进行持久化。
你也可以更换不同的向量数据库进行实验,LlamaIndex 支持多种向量数据库输入。
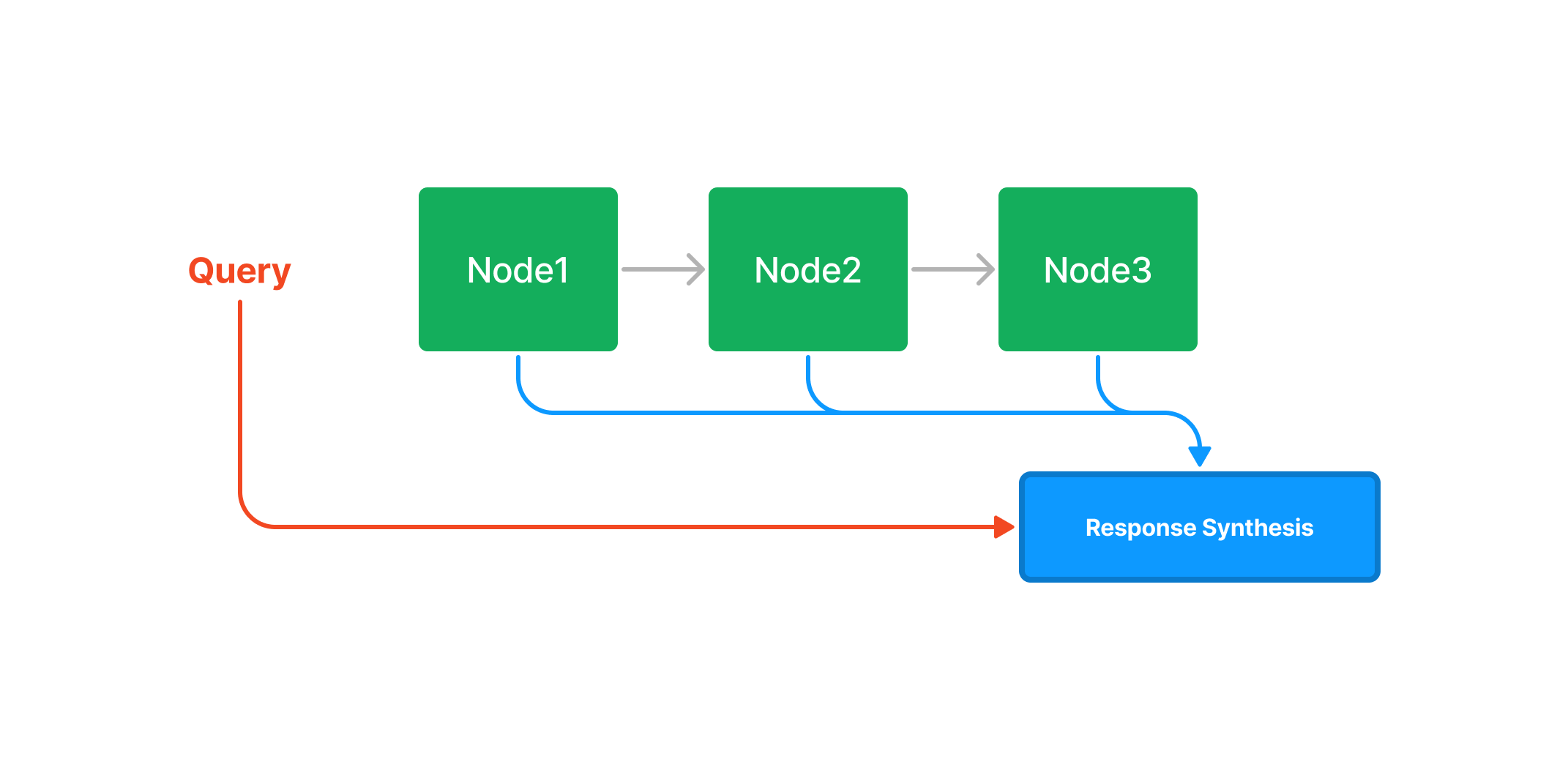
4.4 Query Engine
Query Engine 是 LlamaIndex 中的另一个重要的高级抽象基础设施。Query Engine 是一个通用接口,允许您对数据提出问题。Query Engine 引擎接收自然语言查询,它通常(但不总是)通过检索器建立在一个或多个 indexing 上。您可以组合多个 Query Engine 来实现更高级的功能。
简单而言,我们可以通过以下方式快速基于某个 index 数据结构构建一个查询引擎,并对他进行查询。
1 | query_engine = index.as_query_engine() |
通过 index 、vector store、 query engine 的构建,我们可以很容易针对不同抽象组织的 chunk 进行我们想要的检索、查询操作,最终得到高质量的 RAG 系统。
看了那么多有关 LlamaIndex 的介绍,我们还是不能学会如何结合它与 IPEX-LLM 实现一个简单的 RAG 系统,所以,让我们直接进入到代码的阅读环节。
我们可以来看一个简单的 LlamaIndex 示例,它直观展示了如何构建一个 RAG 体系:
假设你有如下的文件组织:
1 | ├── starter.py |
核心代码为:
1 | # 导入需要的模块和类 |
从代码中,我们可以很容易看到 RAG 系统构建过程。首先我们需要一个读取器,以便我们获取目标目录的对应数据,接着需要对这个数据进行 embedding 化即创建索引,把他转为可存储的向量表示。最后就可以用设定好的大模型,结合查询引擎进行检索增强生成的对话。
5 实现一个自己的 RAG
如果你觉得 LlamaIndex 的封装还不够称心如意,在这里我们还能够实现自己的 RAG 框架,借助于 tiny-universe,我们可以很容易实现一个属于自己的 RAG 框架。
基于简单的结构,我们能够很容易实现属于自己的 Embedding 抽取、持久化、检索与对话。
6 思考题
6.1 🤔 更多的模态
在前面,我们提到的都是语言检索增强生成的方法;但当我们重新审视检索增强这一名词,会发现他并没有指定检索的信息就是语言。
事实上,检索增强——对应的只是通过检索输入最近的向量编码,再利用向量编码提供大模型作为上下文基础信息。那么,我们是否能够检索更多不同模态的向量编码,让我们实现更多模态的 RAG 系统?
比如,我们是否能够实现一个简单的图文对话工具,不需要视觉大模型,而利用一个 图文字典 向量数据库,通过匹配输入图找到对应的向量数据库最接近的图像 embedding,然后返回该图对应的真实文本解释给大语言模型;此时我们实现的就是图像多模态的 RAG 系统。
也许我们可以做的更多? 图像、音频、视频、蛋白质……任何可编码对象都是我们能够检索的,甚至跨不同模态进行检索。
在向量的世界中,他们一视同仁,只有远近之分。
6.2 🍉 更可控的效果
RAG 在当前的发展中,已经极大的提高了大模型问答的精确程度,但我们仍担忧返回错误答案。我们是否有什么方式可以进一步提高检索精度?
- 从知识库的组织让检索更精确
- 从大模型的能力提高让检索更精确
- 通过多模型检查结果实现自动化测试精度
- 通过更多传统语义匹配、混淆度检测方式让回答结果更加固定
- 通过调节参数(温度值等)让回复更可控
RAG的效果已然不错,但我们还需要让他更进一步,这会让AI产品化的爆发临界线越来越近。
7 英特尔芯片的故事
在 AI 时代,席卷而来的不仅仅是人工智能给人的替代压力,而是在大时代下人展现出那颗勇往直前、永远奔腾不息的心。
英特尔公司(Intel)推出的第一款微处理器,也是全球第一款微处理器;于1971年11月15日发布。

1978和1979年,Intel公司先后推出了8086和8088芯片,它们都是16位微处理器,内含29000个晶体管,时钟频率为4.77MHz,地址总线为20位,可使用1MB内存。内部数据总线是16位,外部数据总线8088是8位,8086是16位。1981年8088,芯片首次用于IBMPC机中,开创了全新的微机时代。

Intel公司于1993年03月22 日,发布了P5架构的80586,其正式名称为PENTIUM (中文名:奔腾)。PENTIUM含有310万个晶体管,L1为16KB(8+8)时钟频率最初为60MHZ和66MHZ,Socket 4 ( 273 針腳 PGA 封裝),电压5V,采用0.8um BiCMOS工艺制造。

1997年,在奔腾(P54C)和P6的基础上又有了新的发展,一块奔腾(P54C),加上57条多媒体指令,就得到了多能奔腾(P55C),相对P54C,P55C在以下几方面做了改进:
1。支持称为MMX多媒体扩展的新指令集,有57条新指令,用于高效地处理图形、视频、音频数据
2。内部Cache从16KB增加到32KB
3。优化了CPU的执行核心

在奔腾开创了 CPU 的新时代后,新架构的 CPU 紧随其后不断涌现:


时光来到2024年,小小的奔腾已然演化出繁荣多样的 Intel 芯片体系:

酷睿(Core)是英特尔公司推出的面向中高端消费者、工作站和发烧友的一系列CPU。酷睿替代了曾经是中高端的奔腾(PenTium),将奔腾移至入门级,并将赛扬(Celeron)处理器推向低端。当前常见的I3I5I5就是这个系列,I7还出过至尊版Intel Core i7 Extreme EdiTIon,还有I9处理器。
奔腾(PenTium)是英特尔公司的一个注册商标,作为其x86处理器品牌之一,于1993年推出。之前奔腾是英特尔的唯一的x86处理器产品线,后来随着其产品线的扩展衍生出低端的赛扬(Celeron)系列、供服务器以及工作站使用的至强(Xeon)系列。2006年英特尔推出酷睿(Core)系列处理器产品线,取代原奔腾处理器系列的市场定位。如今奔腾定位中端系列,介于赛扬和酷睿之间。
- 赛扬(Celeron)是英特尔公司中央处理器的一个注册商标。赛扬处理器是Intel旗下经济型产品,于1998年推出。
- 至强(Xeon)是Intel的一个中央处理器品牌,主要供服务器及工作站使用,亦有超级计算机采用此处理器。Intel XeonE3-1230曾因高性价比而受到电脑DIYer的热捧,有“i5的价格,i7的性能”的美誉。
- 安腾(Itanium),是英特尔安腾架构(IA-64)的64位处理器。第一款安腾于2001年推出,该处理器的市场定位是在于企业服务器与高性能运算系统。
- 凌动(Atom)开发代号Silverthorne,是Intel的一个超低电压处理器系列。该处理器的市场定位是在于智能手机、平板电脑和低成本PC,上网本等。
除此之外,英特尔还有许多 GPU 相关的产品线,我们同样也能够通过 IPEX-LLM 以及其他英特尔深度学习框架,将大语言模型高效地运行在我们的端侧设备上。
 微信
微信 支付宝
支付宝







