
生成式推荐1:Tiger
1 研究背景
研究问题:这篇文章要解决的问题是如何在推荐系统中进行生成式检索,以提高推荐的准确性和多样性。
研究难点:如何有效地表示和管理大量的物品数据,如何在推荐过程中捕捉用户的长期意图,以及如何在冷启动情况下提供有效的推荐。
2 研究方法
这篇论文提出了一种新的生成式检索框架,称为 TIGER(Transformer Index for GEnerative Recommenders),用于解决推荐系统中的大规模检索问题。
2.1 语义ID生成
使用预训练的内容编码器(如Sentence-T5或BERT)将文本特征转换为一个高维向量x∈Rdx∈R^dx∈Rd。随后,通过量化语义嵌入,为每个项目生成一个唯一的语义ID。
语义ID被定义为一个长度为mmm的码字元组,其中每个码字来自不同的码本。假设每个码本的大小为KKK,则语义ID可以唯一表示的项目数量为KmK^mKm。
希望语义ID具有以下属性:语义相似的项目(即内容特征相似或语义嵌入接近的项目)应该具有重叠的语义ID。例如,具有语义ID(10,21,35)的项目应比具有ID(10,23,32)的项目更接近具有ID(10,21,4 ...

好久没有写博客了
今天是2025-09-13,上次写博客还是5月2号,过了4个月。这四个月发生了很多事情:
本科毕业:记得5月的时候大部分时间好像在弄毕设?记不太清楚了,不过自己的本科毕设很早就做完了,然后加上毕业的各种事情。
暑期实习:5月的时候在kuku找实习,投了很多公司,最终去了字节,记得毕业典礼刚结束,就无缝衔接去实习了,6.23入职,到现在快3个月了。暑假感觉过的也很快,字节的节奏比较快,所以每周忽的一下就过完了,也学到了很多东西。
研究生开学:9.1开学,一个新的环境,不过研究生给我的感觉是没有本科那么有激情了。可能一直在为自己以后的出路做打算,很实际。说实话,开学之前其实我挺期待我周围的同学都是什么来路,感觉都很厉害。但是开学之后这种感觉慢慢消失了,可能每个人都有自己的特点,我只需要按照自己的路线、自己的节奏走就行了。
发小红书:好像是从8月中旬经常在小红书上分享一些内容,收获了一些粉丝和点赞。说实话,我最初发小红书是为了说能不能赚点米,比如接广告?但是后来又想,我离可以接广告的程度还差很多,所以在不断发小红书的过程中,自己的初心发生了一些变化。看到自己发的经验贴能给他人带来帮助的感觉 ...

「HFLLM」5-数据集
1 加载hf上没有的数据集
对于每种数据格式,只需要在load_dataset()函数中指定加载脚本的类型,以及指定一个或多个文件路径的data_files参数。
以下为加载在github上管理的数据集进行演示,首先下载数据集:
解压数据集:
安装datasets库:
加载数据集:
查看数据集:
也可以使用以下方式加载数据集:
如果数据集很有可能存储在某个远程服务器上,可以使用以下方式进行加载:
123456url = "https://github.com/crux82/squad-it/raw/master/"data_files = { "train": url + "SQuAD_it-train.json.gz", "test": url + "SQuAD_it-test.json.gz",}squad_it_dataset = load_dataset("json", data_files=data_files, ...

「HFLLM」3. 微调预训练模型
1 介绍
本章将学习:
如何从 Hub 准备大型数据集
如何使用高级TrainerAPI 微调模型
如何使用自定义训练循环
如何利用 🤗 Accelerate 库在任何分布式设置上轻松运行自定义训练循环
2 处理数据
以下是如何在 PyTorch 中的一个批次上训练序列分类器:
123456789101112131415161718192021import torchfrom torch.optim import AdamWfrom transformers import AutoTokenizer, AutoModelForSequenceClassification# Same as beforecheckpoint = "bert-base-uncased"tokenizer = AutoTokenizer.from_pretrained(checkpoint)model = AutoModelForSequenceClassification.from_pretrained(checkpoint)sequences = [ "I&#x ...

论文精读9:ADSNet
探索ADSNet:广告领域跨域LTV预测的创新突破1 引言在当今数字化广告的时代,客户终身价值(LTV,Lifetime Value)预测已成为广告行业的关键环节。LTV代表着一个客户在与广告商互动的整个周期内所贡献的累计价值,这一指标直接关联着广告商的投资回报率(ROI)。精准的LTV预测对于广告系统的优化意义重大,它能够帮助广告商合理分配广告预算,精准定位高价值客户,从而制定更具针对性的营销策略,提升广告投放的效果和效率。
然而,在实际操作中,LTV预测面临着诸多挑战,其中数据稀疏性问题尤为突出。从广告转化漏斗(如图1)来看,在从曝光到购买的过程中,数据量呈现出指数级的下降。曝光量可能达到$10^9$级别,点击量为$10^7$,激活量为$10^6$,但购买量仅为$10^4$(内部数据)和$6*10^5$(外部数据)。如此少量的购买样本,使得传统的深度学习模型难以充分挖掘数据中的潜在模式和特征,进而严重制约了LTV预测的准确性。
为了解决这些问题,研究人员不断探索新的方法和技术。其中,跨域迁移学习成为了备受关注的方向,它旨在利用外部数据(源域)的知识来辅助广告平台内部数据(目标域)的 ...

2024年AI年度关键词
1 图像
1.1 DIT 架构
1.2 图像生成控制
1.3 高分辨率图像处理
1.4 AI 图像商业化
1.5 医疗 AI
2 视频
2.1 规模化训练
2.2 下一帧预测
2.3 艺术家共创
2.4 AI 原生创作
2.5 生成式游戏
2.6 世界模拟器
3 3D 生成
3.1 几何形态还原
3.2 材质还原
3.3 高斯泼溅
3.4 3D 训练数据
3.5 AI 元宇宙
3.6 3D UGC
4 编程助手
4.1 全栈生成
4.2 画布工坊
4.3 云端沙盒
4.4 动态 UI
4.5 推理 Debug
5 Agent
5.1 社会模拟
5.2 智能体协作框架
5.3 智能体应用
5.4 自主执行
5.5 智能体基准评估
5.6 长期记忆
5.7 自我进化
6 端侧智能
6.1 极限压缩
6.2 端侧多模态
6.3 端侧 Agents
6.4 AI 芯片
6.5 读屏操作
6.6 端云协同
6.7 隐私计算
7 具身智能
7.1 人形机器人
7.2 机器人供应链
7.3 空间智能
7.4 机器人商业闭环
7.5 运动控制
7.6 Sim2Real
7.7 共创平台
...

论文精读8:AutoPooling
1 背景
推荐系统中有很多多值特征,文中假设所有特征字段都是多值的,定义为以下形式:
传统的池化对所有特征使用统一的池化算子来压缩信息,忽略了特征分布之间的差异。因此,需要更多区分不同领域的池化方法。
因此提出了 AutoPooling 来自适应学习合适的池化算子,提升模型对于多值特征的学习能力。
2 AutoPooling
可以自动搜索每个特征的最佳池化算子,这个过程可以看作是搜索池化层的最佳子结构,这个子结构是搜索空间中预定义的池化算子。
AutoPooling(图 1 的上半部分)为池化层构建了一个池化算子搜索空间 P\mathscr{P}P,并设计了一种搜索策略来为每个字段找到最佳搜索空间。所以,最佳子结构的搜索转换为架构参数的搜索。通过这种方式,将各种池化层集成到加权和中:
通过优化架构参数 α\alphaα 找到最佳池化算子。
AutoPooling 使用两阶段的方法进行训练,分为搜索阶段和重训练阶段(AP-2stage)。
2.1 搜索阶段
将整个系统的参数分为超参数 α\alphaα 和模型可学习的参数 WWW,搜索阶段的主要目的是得到超参数 α\alphaα ...
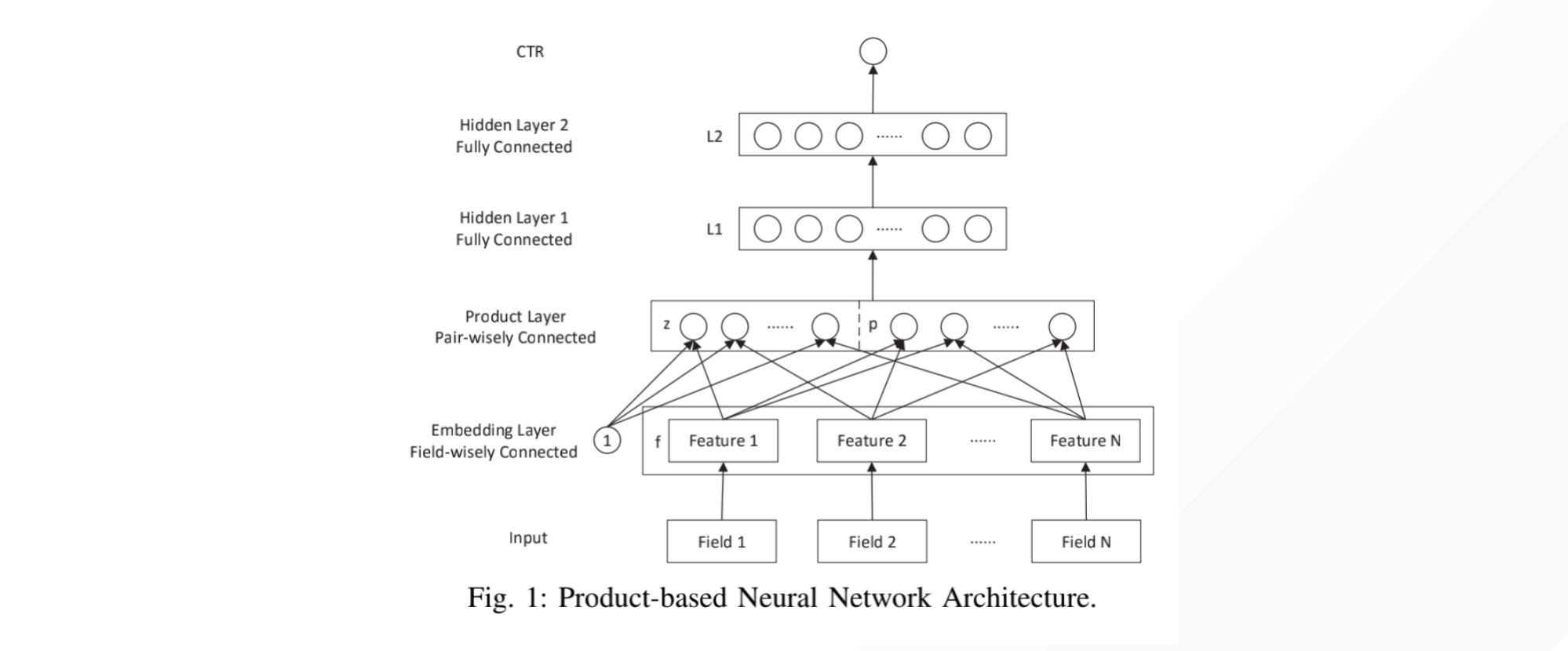
论文精读7:PNN
论文题目:Product-based Neural Networks for User Response Prediction作者:交大张伟楠老师及其合作者发表时间:2016年
1 研究背景目前平台上的数据大部分是通过独热编码转换成高维稀疏二进制特征表示。对于这种极端的稀疏性数据,传统模型从数据中挖掘特征的能力较差。
PNN 论文是构建一个预测模型来估计用户在给定上下文中单击特定广告的概率。
例如当前的用户所处的场景是【星期日:周二,性别:男性,所在城市:伦敦】,那么可以使用独热编码表示为以下形式:
许多机器学习模型已经被提出来处理这种高维稀疏二元特征并有不错的效果,但是这种形式过度依赖特征工程来捕获高阶的潜在模式。可以使用 DNN 自动学习更具表现力的特征表示并提供更好的预测性能。
2 模型结构PNN 的模型结构图如下:
2.1 输出层从自顶向下的角度来看,PNN的输出是一个实数 $\hat{y} \in(0,1)$ 作为预测的CTR:
其中 $\boldsymbol{W}_{3} \in \mathbb{R}^{1 \times D_{2}}$ 和 $b_{3} \in ...

使用大模型API生成摘要
1 安装环境首先安装 PyPI 上的包,在 python 环境中执行如下命令。
1pip install --upgrade spark_ai_python
安装完成后,可以使用以下命令查看是否安装成功:
1pip show spark_ai_python
如果安装成功,将看到该包的详细信息,包括版本号、安装位置等。
上述结果显示安装成功。
2 获取调用密钥在环境安装完成后,调用大模型 API 时需要使用密钥。打开讯飞开放平台控制台。如果尚未登录,请先进行登录。
登录后,导航至 API 管理页面。创建一个新的应用,或者选择已有的应用。在应用详情页中,将看到相关的 API 密钥和其他配置信息。登录成功后的界面如下:
选择左侧的“Spark4.0 Ultra”大模型,可以免费领取 100000 个 token。然后右侧显示当前用户的 APPID、APISecret 和 APIKey,之后的步骤中会用到这几个信息。
3 生成摘要之后使用 sparkai 库来调用讯飞星火大模型的 API,生成给定文章的摘要。以下是代码示例:
1234567891011121314151617181 ...
面试记录7:快手技术二面
1 面试背景
面试公司:快手
面试岗位:推荐算法实习生【模型算法】
面试类型:技术二面
面试时间:2024-12-10 14:00~15:00
面试结果:待定
2 整体感受第一眼感觉面试官 30~40 岁之间,之后没有让我自我介绍,直接让我找一个自己做的好的项目介绍。当时感觉面试官有点不一样,一般都先让自我介绍。
之后问了我几个问题,我都答上来了,然后就是手撕代码环节,也是很快就做出来了,最后面试官的意思基本就是通过了,问我什么时候能去之类的。总之,还是挺好的,找到了实习。
后来了解到面试官是那个组的 leader 😮。
3 提问的问题
面试官:新闻推荐比赛的数据集规模大概是多少?
数据集的话是一共有30万个用户,然后是20万个用户作为训练集,然后5万个用户作为公共的测试集,剩下的5万作为私有的测试集。然后新闻的话大概是60万个新闻。
面试官:你的方案有什么创新点?
首先我对传统的协同过滤进行了改进,传统的协同过滤只考虑两个物品,比如说同时被点击的次数,但是并没有考虑点击顺序和点击时间的权重。balabala……
面试官:除了做一些特征工程,模型结构上有啥变化吗?
b ...