Python 第2次作业
作业2:完成“python进阶知识”ppt中的作业2内容,提供代码及运行结果截图。
读取csv数据“数据2.3.csv”,并开展以下操作:
- 查看数据集中的缺失值
填充数据集中的缺失值(用字符串’缺失数据’代替、用变量均值或者中位数填充缺失数据)
注意:在采取不同方式填充缺失数据时,均需重新读取数据。
- 将var5的数据格式设置成百分比格式。
查看数据集中的缺失值
首先定义read_data** **函数,该函数接受一个参数 file_path,其默认值为 '../data/数据2.3.csv',其中使用 pd.read_csv() 读取指定路径的 CSV 文件。
在检查缺失值时,data.isnull() 返回一个布尔型 DataFrame,表示每个元素是否为缺失值,.sum() 对每列的缺失值进行计数,返回一个包含每列缺失值数量的 Series。
import pandas as pd
def read_data(file_path='../data/数据2.3.csv'):
return pd.read_csv(file_path)
data = read_data()
# 查看数据中的缺失值
missing_values = data.isnull().sum()
print("各列缺失值数量:")
print(missing_values)
运行结果如下:

填充数据集中的缺失值
通过一个函数来实现填充缺失值的功能,根据参数 fill_type 决定填充方式:
'mean':用列的均值填充。'median':用列的中位数填充。'missing':用字符串'缺失数据'填充。
遍历数据框的每一列,根据 fill_type 参数选择不同的填充方式,最终返回处理后的数据框。
def fill_missing_data(df, fill_type='median'):
"""
处理数据框中的缺失值,一共三种填充方式:均值、中位数或'缺失数据'填充。
Args:
df (pandas.DataFrame): 输入的数据框
fill_type (str): 数值型列填充方式,可选 'mean'(均值)、'median'(中位数)、'missing'('缺失数据'),默认为 'median'
Returns:
pandas.DataFrame: 处理缺失值后的数据框
"""
for col in df.columns:
if fill_type == 'mean':
# 对于数值型列,使用均值填充缺失值
df[col] = df[col].fillna(df[col].mean())
elif fill_type == 'median':
# 对于数值型列,使用中位数填充缺失值
df[col] = df[col].fillna(df[col].median())
elif fill_type == 'missing':
# 对于数值型列,使用'缺失数据'填充缺失值
df[col] = df[col].fillna('缺失数据')
return df
filled_data_mean = fill_missing_data(read_data(file_path), fill_type='mean')
filled_data_median = fill_missing_data(read_data(file_path), fill_type='median')
filled_data_missing = fill_missing_data(read_data(file_path), fill_type='missing')
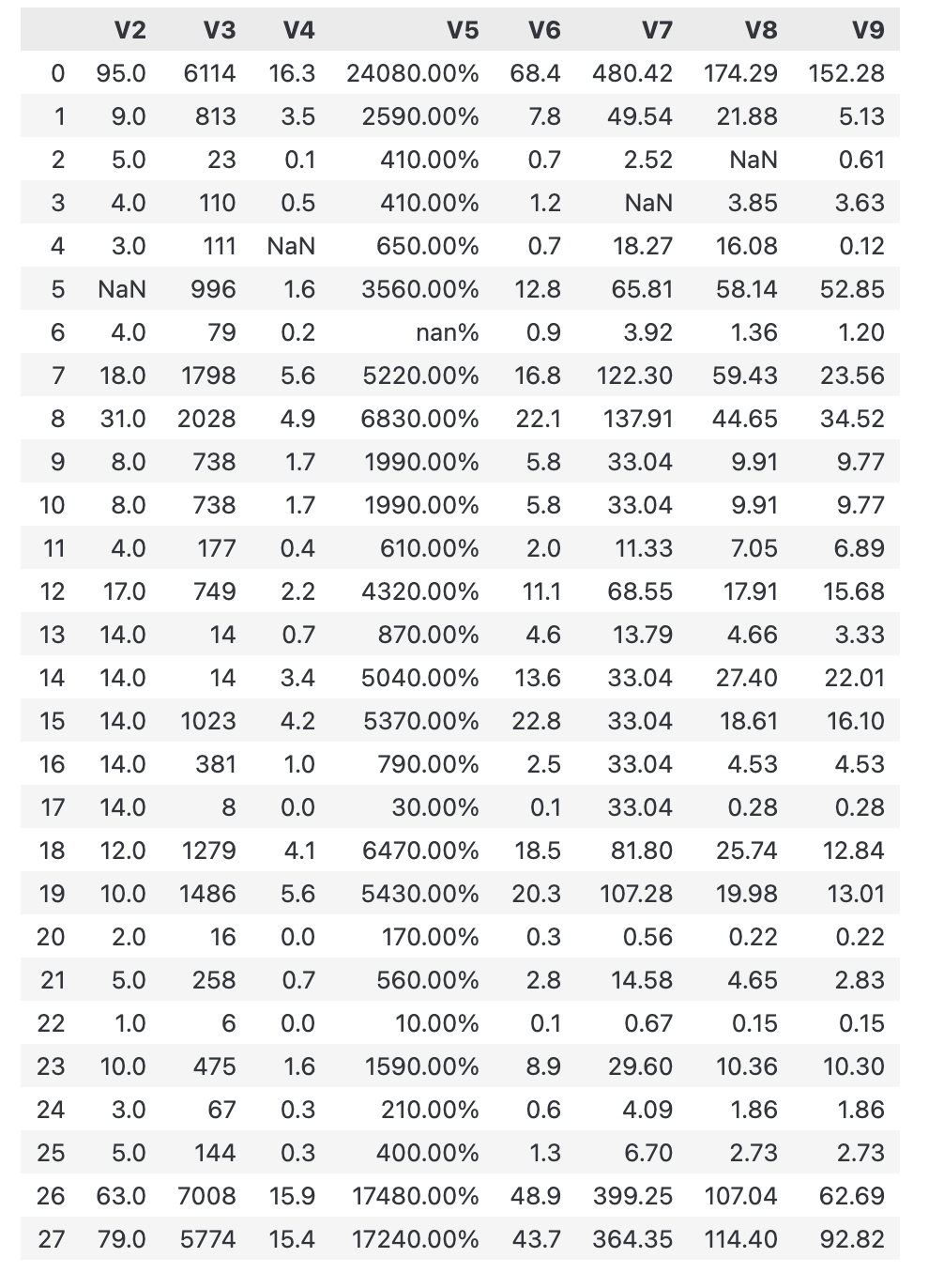
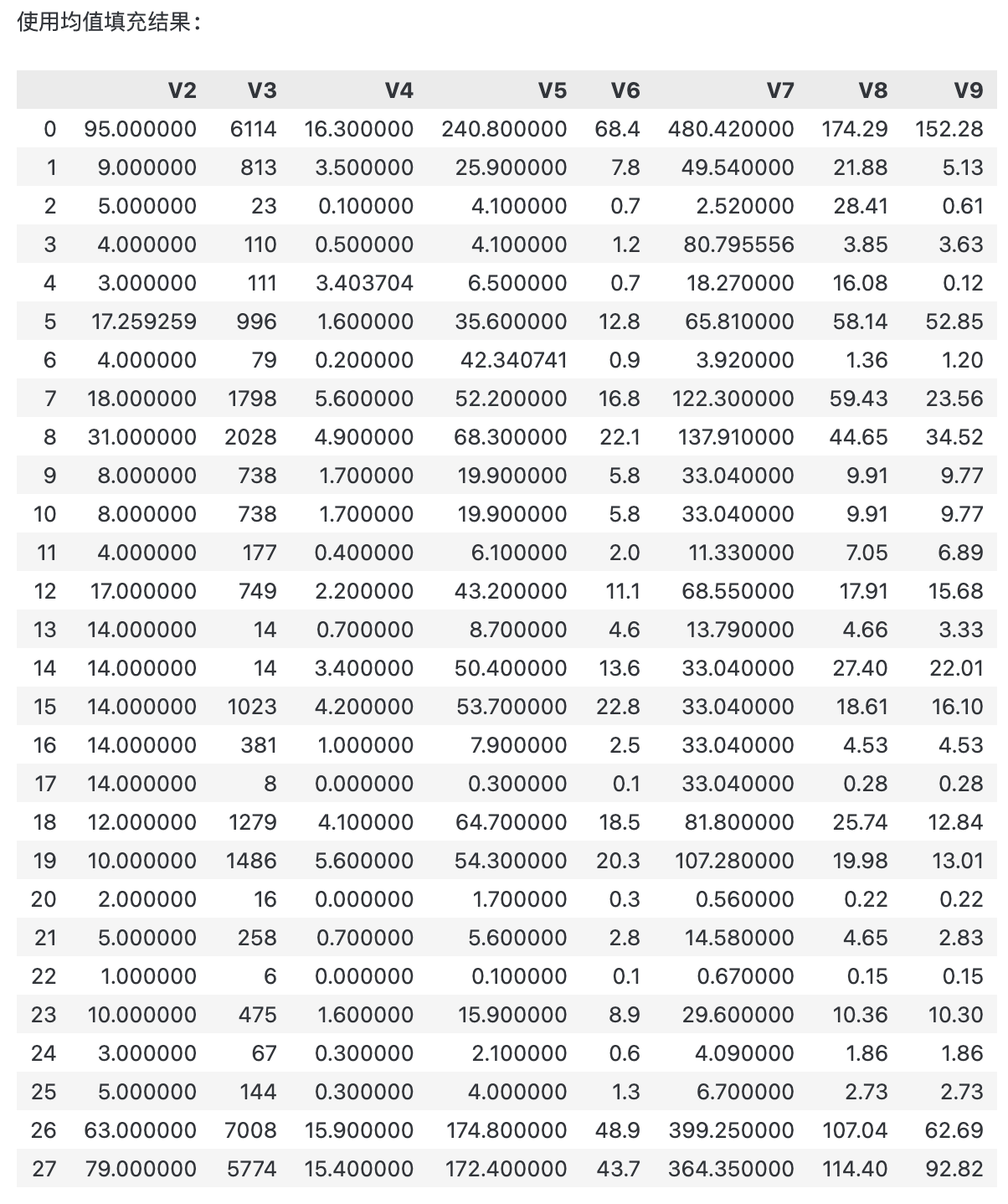
print("使用均值填充结果:")
print(filled_data_mean)
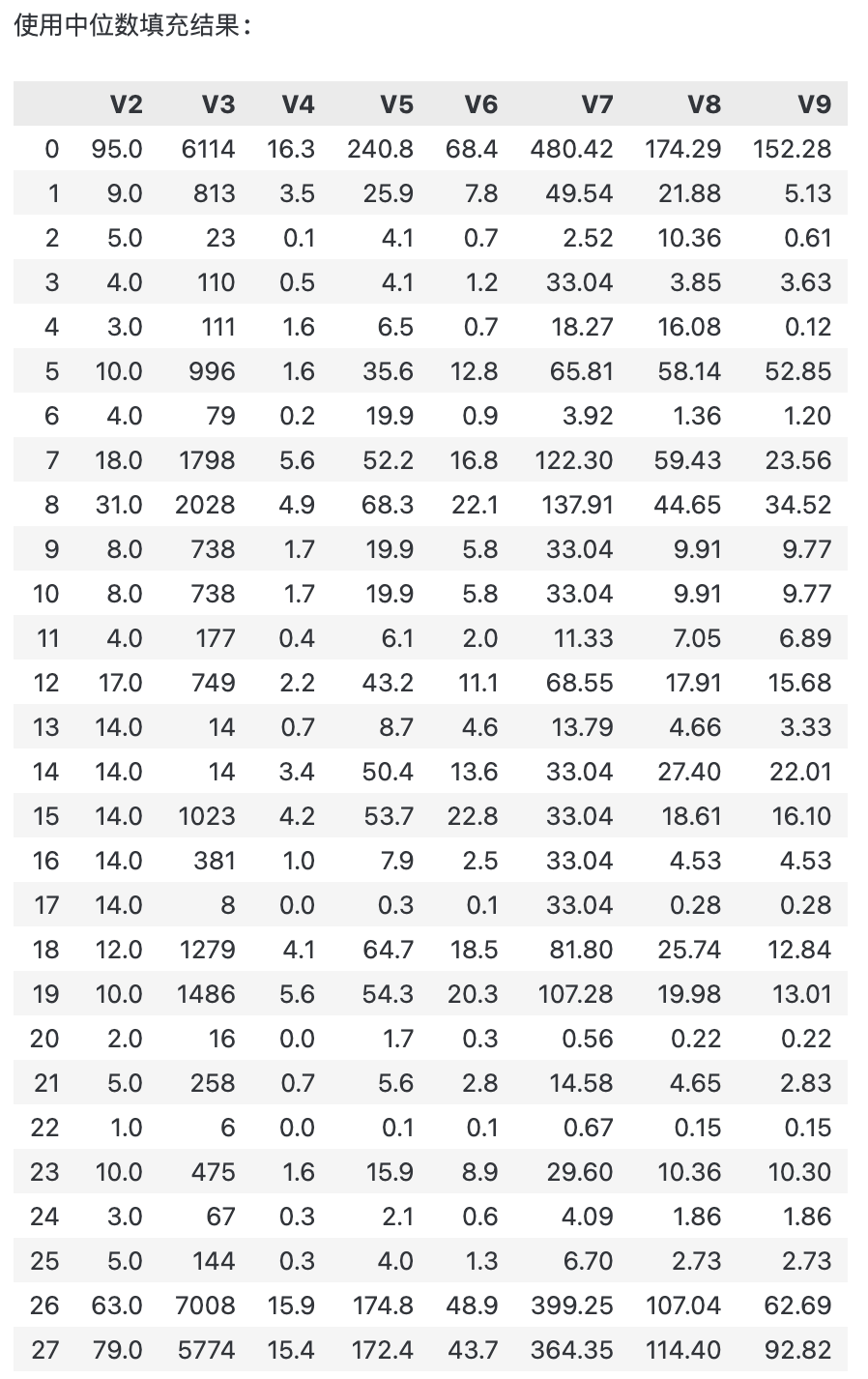
print("使用中位数填充结果:")
print(filled_data_median)
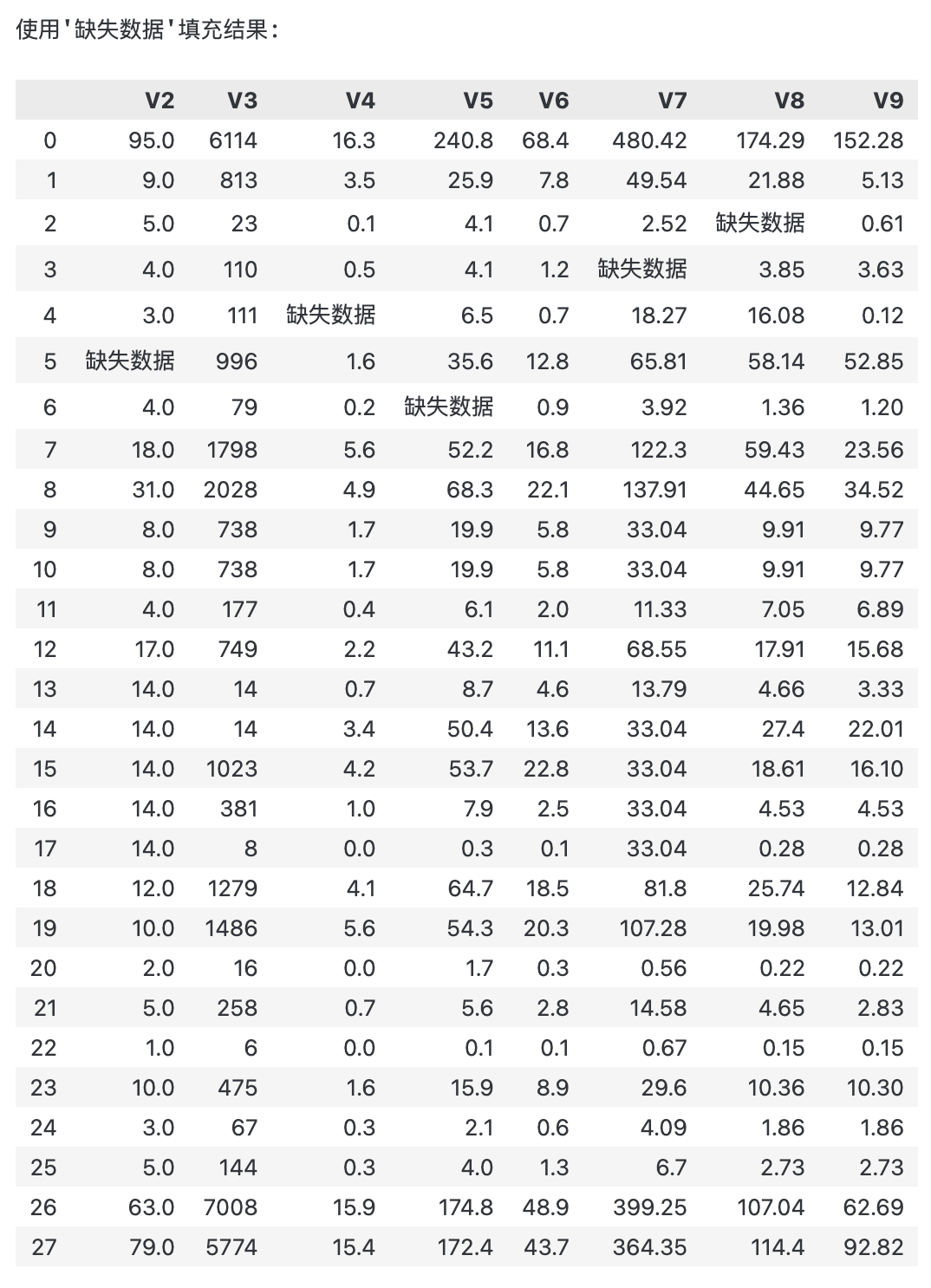
print("使用'缺失数据'填充结果:")
print(filled_data_missing)
运行结果:
将var5的数据格式设置成百分比格式
读取数据并格式化其中某一列(V5)的数据为百分比形式,保留两位小数。
data = read_data(file_path)
data['V5'] = data['V5'].map('{:.2%}'.format)
运行结果: