
信息安全实验5:SQL注入(字符注入)
1 实验环境
操作系统版本:Windows 11 家庭中文版23H2
VMware® Workstation 16 Pro:16.2.3 build-19376536
Metasploitable2虚拟机版本:2.6.24-16-server
2 实验内容2.1 判断注入点与注入类型(1)分别测试输入:1及1”
图2.1 判断注入类型:输入1
图2.2 判断注入类型:输入1”
由图2.2所示,从网页的url可知,页面采用GET方法提交数据,并且输入“1””后能够正确得到查询结果,所以推测注入类型为字符注入。
(2)测试输入:1及1’
之后输入1’进行测试,数据库报错如图2.3,这个错误提示是在使用MySQL数据库时,使用的SQL语法有问题,具体是在’1’处,所以可以推测SQL语句的闭合方式是单引号,并发现数据库为MySQL。
图2.3 判断注入类型:输入1’
(3)测试输入:1 and 1 = 1和1 and 1 = 2
图2.4 判断注入类型:输入1 and 1 = 1
图2.5 判断注入类型:输入1 and 1 = 2
由图2. ...

操作系统面经3:内存管理
1 存储器管理应具有的功能?存储管理的主要任务是为多道程序的运行提供良好的环境,方便用户使用存储器,提高存储器的利用率以
及从逻辑上扩充存储器,故应具有以下功能:
内存的分配和回收:实施内存的分配,回收系统或用户释放的内存空间。
地址变换:提供地址变换功能,将逻辑地址转换成物理地址。
扩充内存:借助于虚拟存储技术活其他自动覆盖技术,为用户提供比内存空间大的地址空间,从逻辑上扩充内存。
存储保护:保证进入内存的各道作业都在自己的存储空间内运行,互不干扰。
2 将用户程序变为可在内存中执行的程序的步骤?
编译:由编译程序将用户源代码编译成若干目标模块
链接:由链接程序将编译后形成的一组目标模块及所需的库函数链接在一起,形成一个完整的装入模块
装入:由装入程序将装入模块装入内存中运行
3 程序的链接方式有哪些?
静态链接:在程序运行之前,先把各个目标模块及所需库链接为一个完整的可执行程序,以后不再拆开。
装入时动态链接:将应用程序编译后所得到的一组目标模块在装入内存时采用边装入边链接的链接方式。
运行时动态链接:知道程序运行过程中需要一些模块时,才对这些模块进行链接。
4 ...

操作系统面经2:进程管理
1 进程与线程?1.1 进程的概念与定义在多道程序环境下,允许多个进程并发执行,此时他们将失去封闭性,并具有间断性及不可再现性的特征。为此引入了进程的概念,以便更好地描述和控制程序的并发执行,实现操作系统的并发性和共享性。
进程是程序的运行过程,是系统进行资源分配和调度的一个独立单位。
1.2 线程的概念和定义早期,在OS中能拥有资源和独立运行的基本单位是进程,然而随着计算机技术的发展,进程出现了很多弊端:
由于进程是资源拥有者,创建、撤消与切换存在较大的时空开销,因此需要引入轻型进程
二是由于对称多处理机(SMP)出现,可以满足多个运行单位,而多个进程并行开销过大
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,每条线程执行不同的任务。
1.3 进程和线程的区别
进程(Process)是系统进行资源分配和调度的基本单位,线程(Thread)是CPU调度和分派的基本单位;
线程依赖于进程而存在,一个进程至少有一个线程;
进程有自己的独立地址空间,线程共享所属进程的地址空间;
进程是拥有系统资源的一个独 ...

Python学习1:基础语法
1 相关工具1.1 IPythonIPython是一种基于Python的交互式解释器。相较于原生的Python交互式环境,IPython提供了更为强大的编辑和交互功能。可以通过Python的包管理工具pip安装IPython,具体的操作如下所示。
1pip install ipython
安装成功后,可以通过下面的ipython命令启动IPython,如下图所示。
2 语法2.1 类型转换可以使用Python中内置的函数对变量类型进行转换:
int():将一个数值或字符串转换成整数,可以指定进制。
float():将一个字符串转换成浮点数。
str():将指定的对象转换成字符串形式,可以指定编码。
chr():将整数转换成该编码对应的字符串(一个字符)。
ord():将字符串(一个字符)转换成对应的编码(整数)。
其中注意一下chr和ord,这两个之前没用过。
下面的代码通过键盘输入两个整数来实现对两个整数的算术运算。
1234567891011121314"""使用input()函数获取键盘输入(字符串)使用int()函数将输入的字符串转换成整 ...

信息安全实验4:文件上传
1 实验环境
操作系统版本:Windows 11 家庭中文版23H2
VMware® Workstation 16 Pro:16.2.3 build-19376536
Metasploitable2虚拟机版本:2.6.24-16-server
Kali虚拟机版本:6.6.9-amd64
2 实验内容编写木马程序文件muma.php,内容如下所示:
代码清单2.1 muma.php文件内容
1<?php @eval($_POST['176']) ?>
首先开启Metasploitable虚拟机,输入用户名和密码进行登录,之后输入“ifconfig”命令查看虚拟机的IP地址,如图2.1所示。
图2.1 查看`Metasploitable`虚拟机的IP地址
开启Kali虚拟机,在浏览器中输入上述IP地址访问Web服务,输入用户名和密码后进行登录,并设置网站的安全等级为“medium”,并点击“Submit”,操作内容如图2.2所示。
图2.2 设置网站安全等级
之后测试文件上传功能,点击“Upload”,选择木马程序文件muma.php文 ...

大佬演讲1:雷军2024年度演讲《勇气》
上了大学特别是学了计算机之后经常能够听到雷军的故事,他也是计算机专业,武汉大学毕业,所以更能感觉到共鸣吧。
之前也回看过雷军的演讲,但是今天有幸听了现场直播,感受如下。
1 遇到困难勇于面对
无论面对何等巨大的危机,都不能被吓到。破釜沉舟的勇气,才是冲出重围的关键。——雷军
小米造车源于一次来自美国的打击,之后雷总想,“如果哪一天小米不能造手机了,靠什么活下去?”,正是从此刻开始,小米有了造车的想法。
所以说,当遇到困难的时候,很多人想的是自己怎么这么难,生活不如意,为什么自己好倒霉等等。但是无论遇到什么困难,都应该有一个勇往直前的决心,正是困难才能让你不断进步,让你反思自己身上存在的问题,让你更加了解自己。
心态是一方面,同时也要采取行动去应对它,而不是等待困难自己消失。想想自己该怎么做,以及这么做是否对自己以及未来的自己是有益的?
2 尊重行业规律
守正出奇,要先守正再出奇,守正有时候比出奇更重要。——雷军
做什么行业,做什么事情要尊重行业或事情发展的规律,任何事物都有一个发展的过程,不能一蹴而就。小米造车,借鉴了其他车企成长的路线,当学习别人的方法的过程中,再逐渐产生自 ...

操作系统面经1:计算机系统概述
1 操作系统的目标和功能(什么是操作系统?)1.1 操作系统是计算机资源的管理者
处理机管理(进程控制、进程同步、进程通信、死锁处理、处理机调度)
存储器管理(提高内存利用率,内存的分配与回收、地址映射、内存保护与共享、内存扩充)
文件管理(计算机中的信息都是以文件的形式存在的)
设备管理(完成用户的I/O请求,方便用户使用设备、并提高设备的利用率)
1.2 操作系统为用户提供使用计算机硬件系统的接口
命令接口(用户通过控制台或终端输入操作命令,向系统提供各种服务要求)
程序接口(由 系统调用 组成,用户在程序中使用这些系统调用来请求操作系统为其提供服务)
图形接口 最常见的 图形用户界面GUI (最终还是通过调用程序接口实现的)
1.3 操作系统用作扩充机器没有任何软件支持的计算机称为裸机,实际呈现在用户面前的计算机系统是经过若干层软件改造的计算机。
操作系统将裸机改造成功能更强、使用更方便的机器。我们将覆盖了软件的机器称为扩充机器或虚拟机。
2 操作系统的运行机制?2.1 内核程序和应用程序(内核态和用户态)在计算机系统中,通常CPU执行两种不同性质的程序:一种是 ...

设计模式:单例
1 Intent确保一个类只有一个实例,并提供该实例的全局访问点。
2 Class Diagram使用一个私有构造函数、一个私有静态变量以及一个公有静态函数来实现。
私有构造函数保证了不能通过构造函数来创建对象实例,只能通过公有静态函数返回唯一的私有静态变量。
3 Implementation3.1 懒汉式-线程不安全以下实现中,私有静态变量 uniqueInstance被延迟实例化,这样做的好处是,如果没有用到该类,那么就不会实例化 uniqueInstance,从而节约资源。
这个实现在多线程环境下是不安全的,如果多个线程能够同时进入 if (uniqueInstance == null) ,并且此时 uniqueInstance为 null,那么会有多个线程执行 uniqueInstance = new Singleton(); 语句,这将导致实例化多次 uniqueInstance。
123456789101112public class Singleton { private static Singleton uniqueInstance; pri ...
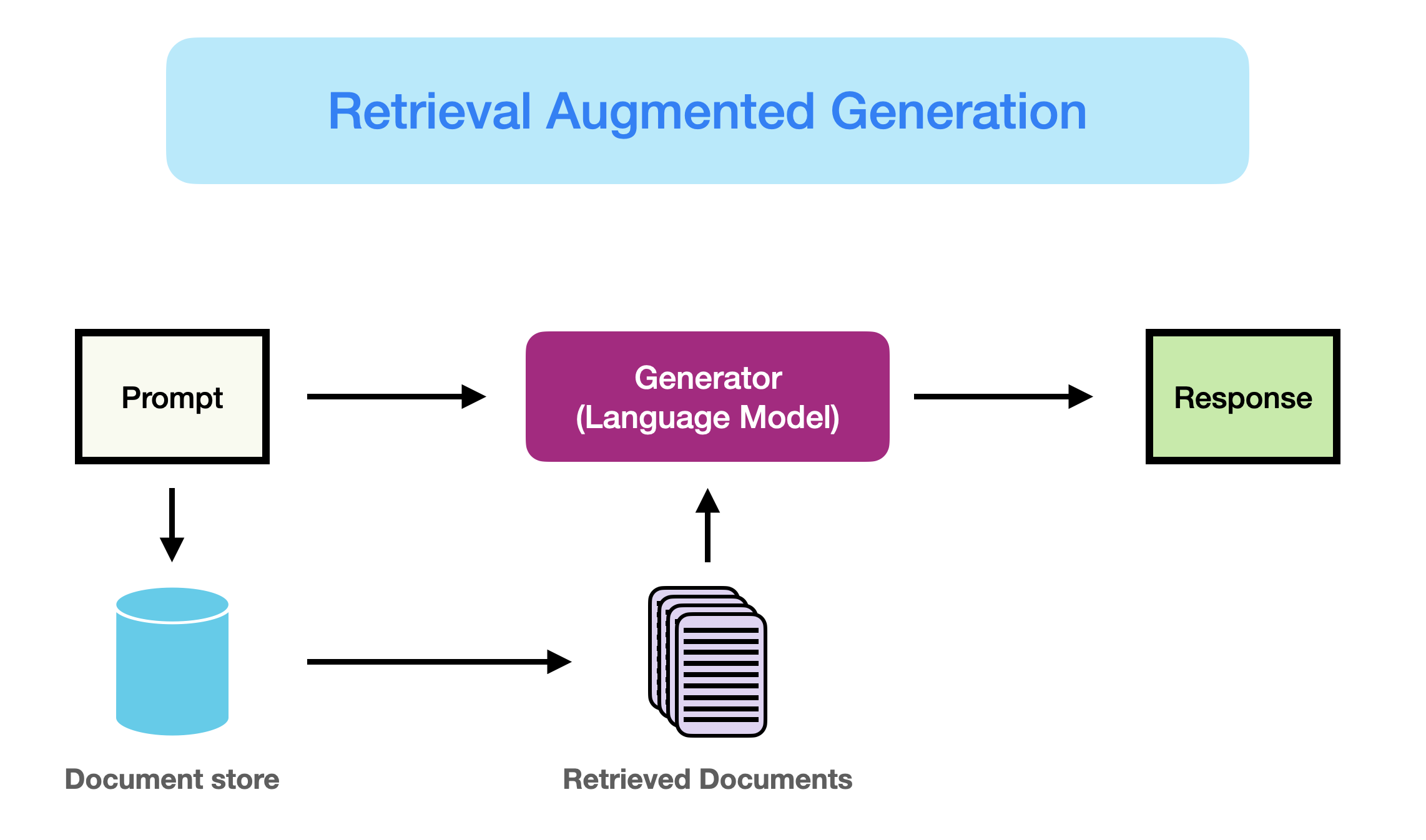
第二期AI夏令营任务3:实现RAG应用
1 Gradio 技术入门Gradio是一个开源的 Python 库,用于快速构建机器学习和数据科学演示应用。它使得开发者可以在几行代码中创建一个简单、可调整的用户界面,用于展示机器学习模型或数据科学工作流程。Gradio支持多种输入输出组件,如文本、图片、视频、音频等,并且可以轻松地分享应用,包括在互联网上分享和在局域网内分享.
简单来说,利用 Gradio 库,我们可以很容易实现一个具有对话功能的前端页面,实现最简单人机交互功能。
在目前的深度学习软件开发中,使用gradio熟练展示demo已经成为了基础必备技能,你可以在任何地方(无论是学术还是工业界)见到 gradio 展示,但我们本次可以只从一个简单的对话demo开始,来逐渐展开gradio的熟悉之旅。
我们可以简单的理解为gradio就是在搭积木,或者说简单理解为所有的前端框架都是在利用一块块积木创造出最好的效果。
在gradio中,我们可以把每个组件创建在 gr.Blocks() 包裹的块当中,你可以把它当作一个展示台,我们可以在展示台上放满不同的组件(比如这里的 gr.Button,gr.Textbox 等等),你可 ...

天津大学智算夏令营之旅
1 夏令营安排
2 7月1日第一天刚起床的时候发现下雨了,但是自己并没有带伞,而且当时酒店里也没有伞,问了酒店客服,他说也没有。然后早上就穿着一个外套就出去了,幸亏这个外套是防雨的,外套外面都湿了,但是短袖一点没湿。
当时看到天津大学北洋园的第一印象是:这个学校好大啊,感觉比我本科的学校大了 10 多倍,而且这还只是一个校区。由于上午进行宣讲,而且还下着雨,就直接去教室了。
到了教室后,已经有很多的学生了,下面是当时拍的一个照片。
当时进到天大的一个教学楼,就感觉这个教学楼建的真好,感觉好大啊,而且教室里面的基础设施也很好,教室也真的好大,感觉天大好有钱。
之后就是每个团队的宣讲,主要感觉团队也很多,而且每个团队都有自己的体系,很有纪律。
记得上午的宣讲一直持续了很长时间,好像都快到下午 1 点了,当时挺饿的,宣讲结束之后就马上去吃饭了。天大中只有一个餐厅可以支持微信扫码,所以只能去那一个餐厅。
在去餐厅的路上,看到了天大的图书馆,如下图,是真的大,哭死/(ㄒoㄒ)/~~
到了餐厅,感觉它们餐厅真高级,直接扫桌子上的小程序进行点餐,也不用去前台点,但是感觉 ...


