

读书记录6:活着
《活着》是中国当代作家余华创作的长篇小说,首次发表于《收获》1992年第6期。
1 前言2024-09-11 看完的书今天才有机会把读后感写下,当时看这本的感受就是一个:惨。感觉自己每天的生活和福贵相比真的幸福极了。所以还有什么理由不享受当下的生活呢?还有什么理由不开心呢?
2 经典语录
做人还是平常点好,争这个争那个,争来争去赔了自己的命。
人要是累得整天没力气,就不会去乱想了。
世界上没有一条道路是重复的,也没有一个人生是能够替代的。
人是为活着本身而活着的,而不是为了活着之外的任何事物所活着。
生活是属于每个人自己的感受,不属于任何别人的看法。
只要一家人天天在一起,也就不在乎什么福分了。
只要我始终保持事事留心的好学态度,即使衰老也算不得什么痛苦。
最恐怖的莫过于那个懂你的人在某一刻突然离开了你,整个生命就像不能承受般坍塌,你遥遥无期的盼望,却换来和陌生人一般的回答,伤心之处莫过于此。
父母越是关注你,对你的期望就越高,他们的关心像雪一样不断落到你的身上,最终把你压垮。
长日尽处,我站在你的面前,你将看到我的疤痕,知道我曾经受伤,也曾经痊愈。
3 允许无常诗人曾丰有 ...

面试记录6:快手技术一面
1 面试背景
面试公司:快手
面试岗位:推荐算法实习生【模型算法】
面试类型:技术一面
面试时间:2024-12-06 15:00~16:00
面试结果:通过 😊
2 整体感受在面试之前就很想去快手,所以很期待这次面试。面试官一进来感觉挺和善的,而且他还简单自我介绍了一下。面试官看起来年龄不是很大,感觉接近 30 的样子。
在面试过程中面试官会引导你去思考,有的问题并不是想问出来一个确切的答案,就是想让你自己去思考一下。所以我就遇到了很多开放的题目。
后面有两道手撕代码,第一道算笛卡尔积,第二道是动态规划,几乎都做出来了。整体感受还不错吧,但是还是要等面试结果出来。
3 提问的问题3.1 word2Vec
面试官:我看你这里用了一个 w2v 的方式对吧,能介绍一下基本的原理吗?
首先介绍一下 Word2Vec,Word2Vec 是一个生成对“词”的向量表达的模型。分为词袋模型和跳元模型。
利用物品序列是由特定用户的浏览、购买等行为产生的历史行为记录序列来生成 Embedding。输入向量表达就是输入层到隐层的权重矩阵 $\mathcal{W}_{V \times N}$,而 ...
面试记录5:百度技术一面
1 面试背景
面试公司:百度
面试岗位:AIGC—搜推方向
面试类型:技术一面
面试时间:2024-12-06 14:00~15:00
面试结果:通过 😊
2 整体感受
百度是纯简历面,简历从上到下挨个问的,除了有一个可能和深度学习关系不大没问,其余都问了。然后一道手撕代码题,由于自己之前做过,所以一看到题目就知道怎么做,然后很快就把代码写出来了。
之后面试官让我写一个样例跑一下,一跑一个准,直接秒了。由于我使用的语言是 C++,但是推荐算法一般都是 Python,所以面试管又让我用 Python 对数组进行排序,使用什么排序方法都可以。其实我早就开始用 Python 刷题了,所以很快就写出来了。
整体来说感觉很好,没有什么很致命的失误,唯一需要改进的可能是有时候表达再清晰一些。
3 提问的问题
3.1 特征工程
面试官:这个天池新闻推荐系统比赛中,你基本上用了哪些特征呢?
特征工程的话主要分为三个部分:用户特征、物品特征和用户历史交互特征。
3.1.1 用户特征
登录环境:用户点击环境、登录设备等特征(数据集中已给出)
用户的主题爱好特征:对于用户点击的历史文章 ...
面试记录4:牵手未来技术一面
1 面试背景
面试公司:牵手未来
面试岗位:算法实习生
面试类型:技术一面
面试时间:2024-12-05 16:00~17:00
面试结果:不通过 😊
2 整体感受
在面试之前,HR 说要做一个笔试题,我以为是机考,结果是下面这种:
当时感觉这个公司还挺专业,提前让你做题。其他公司都没有,但是我后来又想,那这样不就可以很充分的去准备这些题吗?包括查资料等。那面试的时候问你的肯定你都提前准备了,还怎么拉齐面试时的背景知识?
我当时就给做完了,然后进行面试。面试官问我是哪个学院的,我说软微,他说他也是软微的。
面试的过程特别奇怪,一般会进行简历面,针对简历上的内容提问。但是面试官看到我弄过棋类博弈,直接开始想这个能不能用到他们的业务中?然后几乎全是围绕着他们公司的场景来交流的。
反正面试感受特别差,还问我简历上有哪些亮眼的地方(你是面试官还是我是面试官 😂)。
晚上的时候 HR 说没有通过,我当时很震惊,我感觉我没有什么致命的失误,当时很纳闷,因为如果表现不好的话我自己也会感觉出来。
之后我上网查了一下,有一个回答:
当时突然好像明白了,好像知道为什么要做那个笔试题了,好 ...

大佬演讲2:李沐讲座
1 个人生涯
你想解决什么问题,导致你会去做什么事情。
2 打工人
公司也好,学校也好创造了一个比较简单的环境,待得越久,不是在一个更广的层次去思考一个问题。
3 PhD
博士还是看是否有研究价值,主要看个人追求,如果想要创造学术价值,并且真心热爱研究还是可以的,但是如果一心工作,读博士感觉很痛苦。
4 创业
所有的困难在你头上,逃避没有用,如果逃避它,就可能解决不了它。要热爱,才能真正做下去。
核心原因是有一个延迟享受,一个东西,可能5年之后才能得到正反馈。在没有立即正反馈的情况下,需要自己给自己加码,才能真正做下来这件事情。
5 动机
要有一个很强烈的动机,简单的欲望容易被满足,简单的恐惧容易被满足,一定要来自很深沉、很底层的欲望。
内心有什么特别不愿意分享出来的事情?
我感觉的话应该是有一些拖延的坏毛病,而且有的时候总是惯性思维,好像因为之前自己一直这么做,就下意识的去做一些事情。但是做一件事情之前,应该想一下是不是值得你去做这件事情。
想一下你背后的动机是什么?你是想要什么还是怕什么?直面自己的欲望,直面自己的恐惧。
需要把这种欲望和恐惧转换成向上的动机,动机一定是正 ...

如何成为一名优秀的推荐工程师
作为一名推荐工程师,所擅长的不应仅仅是机器学习相关知识,更应该从业务实践的角度出发,提升自己各方面的能力。
1 推荐工程师的 4 项能力抛开具体的岗位需求,从稍高的角度看待这个问题,一名推荐工程师的技术能力基本可以拆解成以下 4 个方面:知识、工具、逻辑、业务。
如果用技能雷达图的形式展示与机器学习相关的几个职位所需的能力,则大致如下图所示。
简单来说,任何推荐系统相关的工程师都应该满足 4 项技能的最小要求,因为在成为一名“优秀”的推荐工程师之前,首先应该是一名合格的工程师。不仅应具有领域相关的知识,还应具有把知识转换成实际系统的能力。推荐系统相关的从业者应该具有的最小能力要求如下:
知识:具备基本的推荐系统领域相关知识
工具:具备编程能力,了解推荐系统相关的工程实践能力
逻辑:具备算法基础,思考的逻辑性、条理性较强
业务:对推荐系统的业务场景有所了解
在最小要求的基础上,不同岗位对能力的要求也有所不同。结合上面的技能雷达,不同岗位的能力特点如下:
算法工程师:算法工程师的能力要求是相对全面的。作为算法模型的实现者和应用者,要求算法工程师有扎实的机器学习基础,改进和实现算法的 ...

面试记录3:MiniMax技术一面
1 面试背景
面试公司:MiniMax 大模型公司
面试岗位:大模型推荐&广告算法实习生
面试类型:技术一面
面试时间:2024-12-04 17:00~18:00
面试结果:通过 😊
2 整体感受面试之前一点也不紧张,因为自己保研参加很多线下的面试,而且之前也参加过华为的面试等,所以心态不慌。
面试官刚进来的时候,一看就知道是个强者,前面的头发快没了,而且一副中年程序员的样貌。在面试的过程中还是挺放松的,也一直和面试官讨论技术问题。最后,面试管问我还有什么问题么?我就问了很多我自己关于推荐系统的思考,感觉很 nice,面试官也和我讨论了很多。
需要改进的地方:
自我介绍再背的熟一些
准备的再充分一些
感觉自己发挥的挺好的,没有什么硬伤,还有一些小细节需要优化吧。
3 提问的问题
面试官:你先介绍一下自己吧。
balabala………
3.1 Word2Vec
面试官:看到你参加了天池新闻推荐系统比赛,你可以说一下你是怎么用 Embedding 进行召回的吗?
我主要使用 2 种方法来进行 Embedding,分别是 Word2Vec 和 训练 YouTube D ...

论文精读6:Llama3
Llama3
现代人工智能(AI)系统是由基础模型提供动力的。本文提出了一套新的基础模型,称为Llama 3。它是一群原生支持多语言、代码、推理和工具使用的语言模型。我们最大的模型是一个稠密的Transformer,具有405B参数和高达128K tokens的上下文窗口。本文对Llama 3进行了广泛的实证评价。我们发现,Llama 3在大量任务上提供了与GPT-4等领先语言模型相当的水平。我们公开发布了Llama 3,包括预训练和后训练的405B参数语言模型的版本,以及我们的Llama Guard 3模型的输入和输出安全。本文还介绍了我们通过合成方法将图像、视频和语音能力整合到Llama 3中的实验结果。我们观察到,这种方法在图像、视频和语音识别任务上与最先进的方法相竞争。生成的模型还没有被广泛发布,因为它们还在开发中。
1 Introduction基础模型是语言、视觉、语音或其他模式的通用模型,它们被设计用来支持大量的人工智能任务。它们构成了许多现代人工智能系统的基础。
现代基础模型的发展包括两个主要阶段:
预训练阶段:模型在大规模训练使用直接任务如单词预测或字幕
后训练阶段 ...

读书记录5:罪与罚
《罪与罚》是俄国作家陀思妥耶夫斯基创作的长篇小说,也是其代表作,于1866年的1月开始刊登在《俄国导报》上,1867年2月连载结束。
1 前言当时在看这本书的时候,一度不知道这本书要讲什么,后来看着看着就明白了。在看之前就知道这是一本压抑小说,看完了后给我的影响是巨大的。
2 经典语录
人这种卑鄙的东西,什么都会习惯的。
我唯一担心的是我们明天的生活能否配得上今天所承受的苦难。
“你为何不骂我,却拥抱我?” “因为世界没有比你更不快乐的人了。”
有时,一个人遇上强盗,整整半小时感到死亡的恐惧,最后,刀架到脖子上,反倒什么都不怕了。
大家都杀人,在世界上,现在杀人,过去也杀人,血像瀑布一样地流,像香槟酒一样地流,为了这,有人在神殿里被戴上桂冠,以后又被称作人类的恩主。
我只想证明一件事,就是,那时魔鬼引诱我,后来又告诉我,说我没有权利走那条路,因为我不过是个虱子,和所有其余的人一样。
世界上没有什么比直言不讳更难,也没有什么比阿谀奉承更容易的了。
要知道,女人就是这样,爱你也是她,害你也是她,两者并行不悖。
平凡的人必须听话,没有犯法的权利,因为,您要知道,他们是平凡的人。不平凡 ...
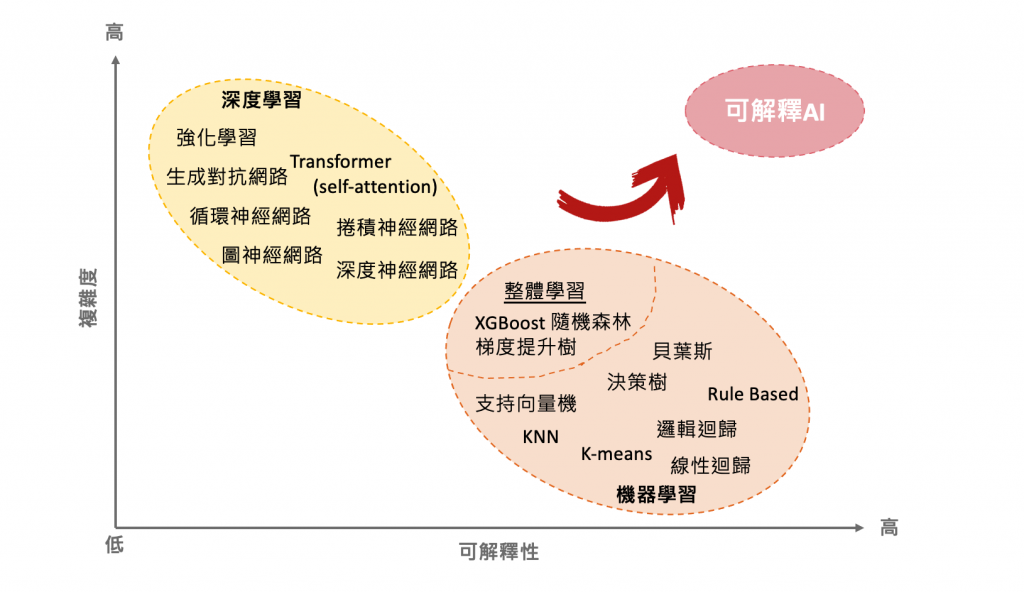
机器学习模型的可解释性
1 模型可解释性介绍如果机器学习的模型具有解释力的话,也可以凭借这个结果去修正我们的模型。未来的目标是知道为什么模型预测的结果很差,并且使用可解释的机器学习修正它。
1.1 Interpretable v.s. Powerful一些模型的解释性是很好的,例如线性模型,但是这种模型的能力较差。深度神经网络很难去解释,就像黑箱一样,但是效果远比线性模型要好。
就像决策树算法的可解释性和效果都很好,所以是不是我们只要使用决策树就可以了?当然不是,因为决策树也可以变得很复杂。就像在打 Kaggle 比赛时,通过不会使用一棵决策树,一般会用随机森林,这时候是很多棵决策树共同决定的结果。
1.2 可解释ML的目标可解释性一定要完全了解ML模型是如何工作的吗?例如,我们不完全知道大脑是如何工作的,但我们相信人类的决定。
一个好的可解释性就是给人一个理由去相信这么解释是对的,重点是人类能够理解模型是如何运行的。
1.3 可解释性的分类机器学习模型的可解释性分为局部可解释性和全局可解释性,以下图为例对局部可解释性和全局可解释性进行介绍:
局部可解释性:为什么这张图片是一只猫
全局可解释性:什么样 ...


