
概率论第3章:多维随机变量及其分布
1 二维随机变量1.1 二维随机变量的分布函数设 E 是一个随机试验, 它的样本空间是$S={e}$,设$X=X(e), Y=Y(e)$是定义在 S 上的随机变量,由它们构成的一个二维向量(X,Y)叫做二维随机变量或二维随机向量。
定义1:设(X,Y)是二维随机变量,对于任意实数x和y,二元函数$F(x, y)=P{(X \leq x) \cap(Y \leq y)}=P{X \leq x, Y \leq y}$称为二维随机变量(X,Y)的分布函数,或者称为随机变量X和Y的联合分布函数。
1.1.1 分布函数的函数值的几何解释将二维随机变量(X,Y)看成是平面上随机点的坐标, 那么, 分布函数F(x, y)在点(x, y)处的函数值就是随机点(X,Y)落在下面左图所示的, 以点(x, y)为顶点而位于该点左下方的无穷矩形域内的概率。
$随机点 (X, Y) 落在矩形域 x_{1}<x \leq x_{2}, y_{1}<y \leq y_{2}$内的概率为:
$$\begin{array}{c}P\left(x_{1}&l ...
概率论第2章:随机变量及其分布
1 随机变量1.1 随机变量概念的产生在实际问题中,随机试验的结果可以用数量来表示,由此就产生了随机变量的概念。
有些试验结果本身与数值有关(本身就是一个数).
在有些试验中,试验结果看来与数值无关,但我们可以引进一个变量来表示它的各种结果. 也就是说,把试验结果数值化.
这种对应关系在数学上理解为定义了一种实值单值函数.
1.2 随机变量的定义
说明:实值单值函数随试验结果的不同而取不同的值,因而在试验之前只知道它可能取值的范围,而不能预先肯定它将取哪个值。
随机变量通常用大写字母X, Y, Z, W, N 等表示;随机变量所取的值,一般采用小写字母 x, y, z, w, n等。
1.2.1 引入随机变量的意义有了随机变量,随机试验中的各种事件,就可以通过随机变量的关系式表达出来.
如:每小时查看手机的次数,用X表示,它是一个随机变量.
由于试验结果的出现具有一定的概率,随机变量的取值也有一定的概率。
随机变量概念的产生是概率论发展史上的重大事件。引入随机变量后,对随机现象统计规律的研究,就由对事件及事件概率的研究扩大为对随机变量及其取值规 ...

概率论第1章:概率论的基本概念
1 随机试验概率论是研究随机现象规律性的一门数学学科。
1.1 随机现象随机现象的特征:条件不能完全决定结果。
1.1.1 确定性现象在一定条件下必然发生的现象称为确定性现象。
1.1.2 随机现象在一定条件下可能出现也可能不出现的现象称为随机现象。
实例1:在相同条件下掷一枚均匀的硬币,观察正反两面出现的情况。
说明:
随机现象揭示了条件和结果之间的非确定性联系 , 其数量关系无法用函数加以描述
随机现象在一次观察中出现什么结果具有偶然性, 但在大量试验或观察中, 这种结果的出现具有一定的统计规律性
随机现象是通过随机试验来研究的。
1.2 随机试验在概率论中,把具有以下三个特征的试验称为随机试验。
可以在相同的条件下重复地进行
每次试验的可能结果不止一个, 并且能事先明确试验的所有可能结果
进行一次试验之前不能确定哪一个结果会出现
说明:
随机试验简称为试验, 是一个广泛的术语。它包括各种各样的科学实验, 也包括对客观事物进行的 “调查”、“观察”或 “测量” 等
随机试验通常用 E 来表示
2 样本空间、随机事件2.1 样本空间、样本点一个随机试验E的所有可能结 ...

数据结构第4章:串
1 串的存储1.1 定长顺序存储表示12#define MAXSTRING 255 // 用户可在255以内定义最大串长typedef unsigned char SString [ MAXSTRLEN +1 ];
1.2 堆分配存储表示存储空间是在程序执行过程中动态分配得到的,在堆中使用malloc函数和free函数完成动态存储管理。
12345typedef struct{ char *Ch; // 若是非空串,则按串长分配存储区,否则ch为NULL int Length; // 串长度}HString;
1.3 块链存储表示类似于线性表的链式存储结构,也可采用链表方式存储串值。
每个结点既可放一个字符,也可以存放多个字符,每个结点称为块,整个链表称为块链结构。
块链的效率:
每个结点中数据域越大,效率越高。
$$ 存储密度 = \frac{串所占的存储位}{实际分配的存储位}$$
1234567891011#define CHUNKSIZE 80 // 块大小typedef struct Chunk{ cha ...
数据结构第5章:树与二叉树
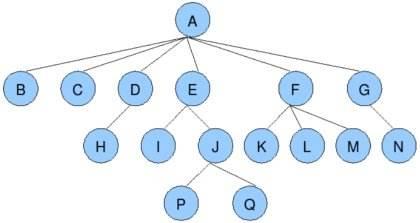
1 树的定义和基本概念树型结构是一类重要的非线性结构。树型结构是结点之间有分支,并且具有层次关系的结构,它非常类似于自然界中的树。树结构在客观世界国是大量存在的,例如家谱、行政组织机构都可用树形象地表示。
树在计算机领域中也有着广泛的应用,例如在编译程序中,用树来表示源程序的语法结构;在数据库系统中,可用树来组织信息;在分析算法的行为时,可用树来描述其执行过程,等等。
1.1 树的定义定义:树(tree)是n(n>0)个结点的有限集T,其中:有且仅有一个特定的结点,称为树的根(root)。
当$n>1$时,其余结点可分为$m(m>0)$个互不相交的有限集T1,T2,……Tm,其中每一个集合本身又是一棵树,称为根的子树(subtree)。
特点:
树中至少有一个结点——根
树中各子树是互不相交的集合
1.2 基本概念
结点(node)——指树中的一个数据元素,包括数据项及若干指向其子树的分支。一般用一个字母表示。
结点的度(degree)——结点拥有的子树数
叶子(leaf)——度为0的结点,也叫终端结点。
分支结点——除叶子结点外的所有结点,也k叫非终 ...
数据结构第6章:图
1 图的存储图的存储结构至少要保存两类信息:
顶点的数据
顶点间的关系
如何表示顶点间的关系?
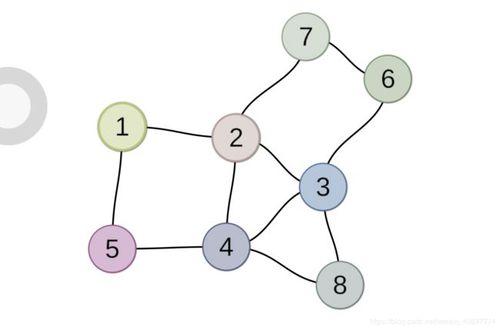
1.1 邻接矩阵图的邻接矩阵(Adjacency Matrix) 存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
设图 G 有 n 个顶点,则邻接矩阵 A 是一个$n ∗ n$的方阵,定义为:
下图是一个无向图和它的邻接矩阵:
可以看出:
无向图的邻接矩阵一定是一个对称矩阵(即从矩阵的左上角到右下角的主对角线为轴,右上角的元与左下角相对应的元全都是相等的)。 因此,在实际存储邻接矩阵时只需存储上(或下)三角矩阵的元素。
对于无向图,邻接矩阵的第i行(或第i列)非零元素(或非∞元素)的个数正好是第i个顶点的度。
有向图中:
顶点 $ V_{i} $ 的出度是A中第 i 行元素之和
顶点 $ V_{i} $ 的入度是A中第 i 列元素之和
邻接矩阵存储适用于稠密图。
1.2 邻接表当一个图为稀疏图时(边数相对顶点较少),使用邻接矩阵法显然要浪费大量的存储空间,如下图所示:
而图的邻接表法结合了顺序存储和链式 ...
数据结构第7章:查找
1 总览查找表:查找表是由同一类型的数据元素(或记录)构成的集合。由于“集合”中的数据元素之间存在着完全松散的关系,因此查找表是一种非常灵便的数据结构,可以用其他的数据结构来实现。
动态查找表:若在查找的同时对表做修改操作(插入删除等)则相应的表称之为动态查找表;否则称之为静态查找表。
平均查找长度ASL(查找算法的评价指标):为确定记录在查找表中的位置,需和给定值进行比较的关键字个数的期望值,称为查找算法在查找成功时的平均查找长度(Average Search Length)。
对查找表常进行的3种操作:
查询某个特定的值是否在表中
插入一个元素
删除一个元素
2 顺序查找和折半查找2.1 顺序查找算法思想:通过数组下标递增来顺序操作每个元素,返回结果。
优点:对数据存储结构没有任何要求。
缺点:平均查找长度$ASL=n$,效率较低。
2.2 折半查找折半查找是一种效率高效的查找方法,但是仅适用于有序的顺序表。
折半查找算法思路:(非递归)
设表长为n、low、high和mid分别指向待查元素所在区间的上界、下界和中点,key为给定的要查找的值。
初始时,令lo ...
计算机网络第2章:物理层
1 物理层的基本概念物理层考虑的是怎样才能在连接各种计算机的传输媒体上传输数据比特流,而不是指具体的传输媒体。
物理层的作用是要尽可能地屏蔽掉不同传输媒体和通信手段的差异。
用于物理层的协议也常称为物理层规程 (procedure)。
物理层的主要任务:确定与传输媒体的接口的一些特性。
机械特性:指明接口所用接线器的形状和尺寸、引线数目和排列、固定和锁定装置等。
电气特性:指明在接口电缆的各条线上出现的电压的范围。
功能特性:指明某条线上出现的某一电平的电压的意义。
过程特性 :指明对于不同功能的各种可能事件的出现顺序。
2 数据通信的基础知识2.1 数据通信系统的模型一个数据通信系统包括三大部分:源系统(或发送端、发送方)、传输系统(或传输网络)和目的系统(或接收端、接收方)。
2.1.1 常用术语
数据 (data) —— 运送消息的实体。
信号(signal) —— 数据的电气的或电磁的表现。
模拟信号 (analogous signal) —— 代表消息的参数的取值是连续的。
数字信号 (digital signal) —— 代表消息的参数的取值是离散的。
码 ...

计算机网络第6章:应用层
每个应用层协议都是为了解决某一类应用问题,而问题的解决又往往是通过位于不同主机中的多个应用进程之间的通信和协同工作来完成的。应用层的具体内容就是规定应用进程在通信时所遵循的协议。
应用层的许多协议都是基于客户服务器方式。客户(client)和服务器(server)都是指通信中所涉及的两个应用进程。
客户服务器方式所描述的是进程之间服务和被服务的关系。客户是服务请求方,服务器是服务提供方。
1 域名系统 DNS1.1 域名系统概述域名系统 DNS (Domain Name System) :
互联网使用的命名系统。
用来把人们使用的机器名字(域名)转换为 IP 地址。
为互联网的各种网络应用提供了核心服务。
互联网的域名系统DNS被设计称为一个联机分布式数据库系统,并采用客户服务器方式。DNS使大部分名字都在本地进行解析,仅少量解析需要在互联网上通信。
域名到 IP 地址的解析是由若干个域名服务器程序共同完成。
域名服务器程序在专设的结点上运行,运行该程序的机器称为域名服务器。
解析过程如下:当某一个应用进程需要把主机名解析为IP地址时,该应用进程就调用解析程 ...

计算机网络第5章:传输层
1 传输层协议概述1.1 进程之间的通信从通信和信息处理的角度看,运输层向它上面的应用层提供通信服务,它属于面向通信部分的最高层,同时也是用户功能中的最低层。
当网络的边缘部分中的两个主机使用网络的核心部分的功能进行端到端的通信时,只有位于网络边缘部分的主机的协议栈才有运输层,而网络核心部分中的路由器在转发分组时都只用到下三层的功能。
运输层为相互通信的应用进程提供了逻辑通信:
1.1.1 应用进程之间的通信
两个主机进行通信实际上就是两个主机中的应用进程互相通信。
应用进程之间的通信又称为端到端的通信。
运输层的一个很重要的功能就是复用和分用。应用层不同进程的报文通过不同的端口向下交到运输层,再往下就共用网络层提供的服务。
“运输层提供应用进程间的逻辑通信”。“逻辑通信”的意思是:运输层之间的通信好像是沿水平方向传送数据。但事实上这两个运输层之间并没有一条水平方向的物理连接。
运输层协议和网络层协议的主要区别:
在运输层有一个很重要的功能——复用和分用。
复用是指发送方不同的应用进程都可以使用同一个运输层协议传送数据
分用是指接收方的 ...


