
WSS推荐系统学习笔记10:物品冷启动2
1 Look-Alike 人群扩散
1.1 在互联网广告中的应用
Look-Alike 起源于互联网广告。假设一个广告主是特斯拉,它们知道Tesla Model 3 典型用户有以下特点:
- 年龄 25~35
- 本科学历以上
- 关注科技数码
- 喜欢苹果电子产品
把具有上述特点的用户给圈起来,重点在这些用户中投放广告。满足所有条件的用户被称为种子用户,这样的用户数量不是很多。广告主想给一百万个人投放广告,但是我们只圈出几万人,该如何找到其他的目标用户?
可以用到 Look-Alike 人群扩散,对种子用户进行人群扩散找到 Look-Alike 用户,Look-Alike 是一个框架,如何进行扩散,有各种各样的方法。
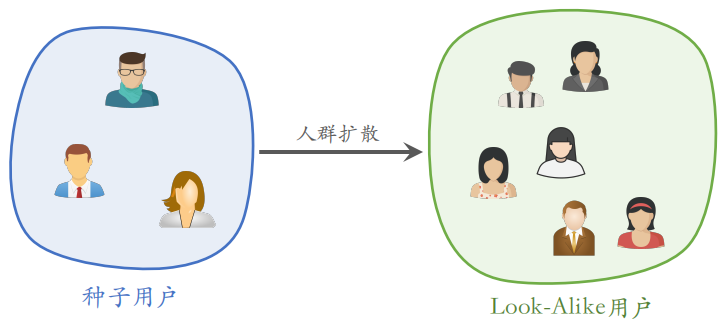
最重要的问题在于如何计算两个用户的相似度,有一些简单的方法:
- UserCF:两个用户有共同的兴趣点
- Embedding:两个用户向量的cosine较大
1.2 用于新笔记召回
在冷启动中,如果用户有点击、点赞、收藏、转发等行为,说明用户对笔记可能感兴趣。把有交互的用户作为新笔记的种子用户,如果一个用户和种子用户相似,可以把这个笔记推荐给他,用 Look-Alike 在相似用户中扩散。
系统对新笔记的推荐不太准,有交互行为的用户数量很少,一旦有交互行为,我们要充分利用这种信号,可以把这些有交互行为的用户向量取均值得到一个新向量,把这个新向量作为该笔记的特征向量。
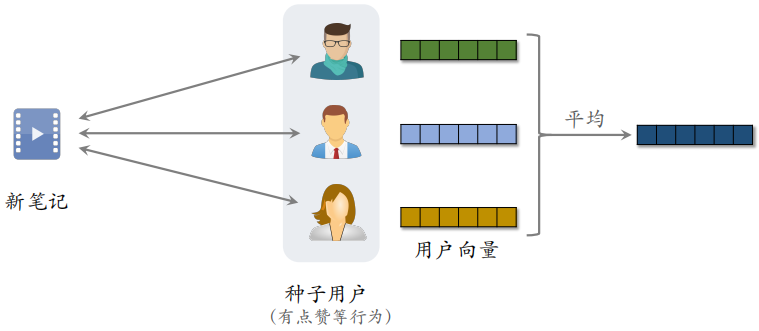
这个特征向量是做近线更新的,意思就是不用实时进行更新,能做到分钟级更新即可。这个特征向量是有交互的用户的向量的平均,每当有用户交互该物品,更新笔记的特征向量。
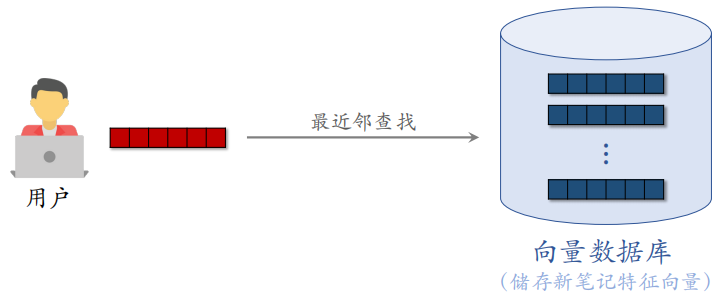
线上召回:把新笔记的特征向量都放在向量数据库里,向量数据库通常支持最近邻查找。之后用户发出推荐请求时,拿用户的特征向量作为 $query$ 在向量数据库中做最近邻查找,取回几十篇笔记,这个过程叫做 Look-Alike。
2 流量调控
冷启动的优化点:
- 优化全链路(包括召回和排序)
- 流量调控(流量怎么在新物品、老物品中分配)
为什么给新笔记流量倾斜?扶持新笔记的目的如下:
- 促进发布,增大内容池:新笔记获得的曝光越多,作者创作积极性越高,反映在发布渗透率、人均发布量。
- 挖掘优质笔记:做探索,让每篇新笔记都能获得足够曝光,挖掘的能⼒反映在高热笔记占比。
举例说明工业界大致怎么对新发布的物品做扶持。假设推荐系统只分发年龄 < 30 天的笔记,假设采用自然分发,则新笔记(年龄 < 24 小时)的曝光占比为 $\frac{1}{30}$。因此要扶持新笔记,让新笔记的曝光占比远大于 $\frac{1}{30}$。
流量调控技术的发展:
- 在推荐结果中强插新笔记(最原始)
- 对新笔记的排序分数做提权(boost)
- 通过提权,对新笔记做保量
- 差异化保量
2.1 新笔记提权(boost)
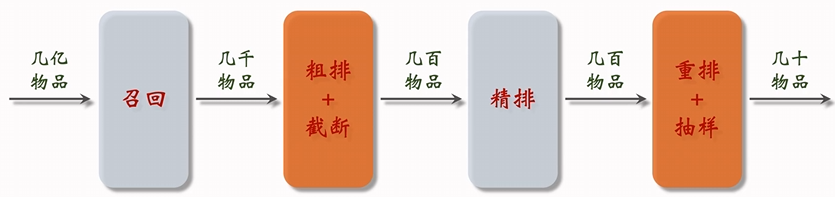
给新笔记提权的目标是让新笔记有更多机会曝光。如果做自然分发,24 小时新笔记占比为 $\frac{1}{30}$。因此做人为干涉,让新笔记占比大幅提升。粗排和重排都是漏斗,如果要做人为干涉,一般时干涉粗排、重排环节,给新笔记提权。
优点是容易实现,投⼊产出比好,在前期没有足够多的人力的时候这种方案比较好。
缺点:
- 曝光量对提权系数很敏感
- 很难精确控制曝光量,容易过度曝光和不充分曝光
2.2 新笔记保量
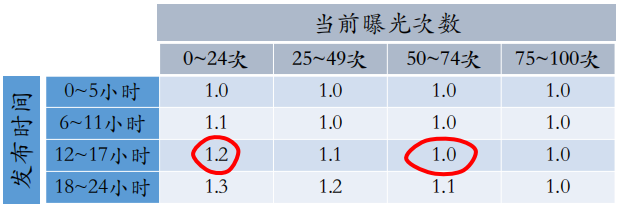
保量:对于一篇新笔记,不论笔记质量高低,都保证在前 24 小时获得 100 次曝光。最原始的保量是在原有提权系数的基础上,乘以额外的提权的系数,需要差异化对待不同的曝光时间,比如:
2.2.1 动态提权保量
动态提权保量是更先进的保量方法,可以用下面四个值计算提权系数:
- 目标时间:比如 24 小时
- 目标曝光:比如 100 次
- 发布时间:比如笔记已经发布 12 小时
- 已有曝光:比如笔记已经获得 20 次曝光
$$
提权系数 =f\left(\frac{\text { 发布时间 }}{\text { 目标时间 }},\frac{\text { 已有曝光 }}{\text { 目标曝光 }}\right)=f(0.5,0.2)
$$
2.2.2 保量的难点
保量成功率远低于 100%
实际操作中,很多笔记在 24 小时达不到 100 次曝光。造成效果不好的原因有很多,可能在推荐链路上存在问题,比如召回、排序存在不足。也有可能是排序模型的问题,对新笔记的预估不准。还有可能提权系数调得不好,导致曝光不足。
此外线上环境变化也会导致保量失败,例如新增召回通道、升级排序模型、改变重排打散规则。线上环境变换之后,往往需要调整提权系数,很麻烦。
是否可以给所有新笔记⼀个很大的提权系数(比如 4 倍),直到达成 100 次曝光为止。这样的保量成功率很高,为什么不用这种方法呢?是否给新笔记分数 boost 越多,对新笔记越有利?
好处:分数提升越多,曝光次数越多。
坏处:把笔记推荐给不太合适的受众。
- 点击率、点赞率等指标会偏低
- 长期会受推荐系统打压,难以成长为热门笔记
2.3 差异化保量
简单的保量不论新笔记质量高低,都做扶持,在前 24 小时给 100 次曝光。差异化保量有区别,不同笔记有不同保量目标,普通笔记保 100 次曝光,内容优质的笔记保 100~500 次曝光。
差异化保量保证每篇笔记都有一个基础保量,比如 24 小时 100 次曝光。依据是笔记内容质量和作者质量。
- 内容质量:用模型评价内容质量高低,给予额外保量目标,上限是加 200 次曝光。
- 作者质量:根据作者历史上的笔记质量,给予额外保量目标,上限是加 200 次曝光。
那么⼀篇笔记在前 24 次小时最少有 100 次保量,最多有 500 次保量。达到保量目标之后就会停止扶持,让新笔记自由分发,跟老笔记公平竞争。
3 冷启的 AB 测试
在冷启的 AB 测试中,既要看作者侧指标,也要看用户侧指标。其中作者侧指标包括发布渗透率、人均发布量,这些指标可以反映作者的发布意愿。用户侧指标包括对新笔记的点击率、交互率。
除此之外,还要看大盘指标:消费时长、日活、月活。不希望冷启推荐的新笔记引起用户的反感,导致用户不活跃。
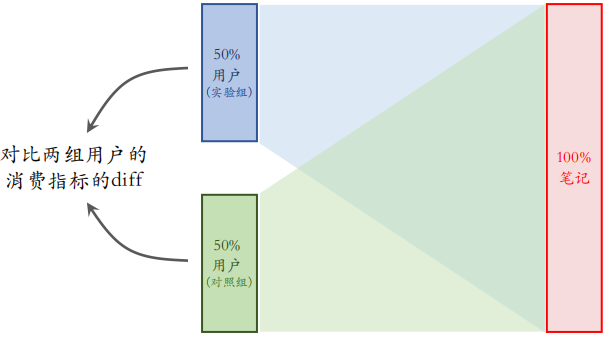
推荐系统标准的冷启测试如下,把用户分为两组,每组包含 $50\%$ 的用户,上面是实验组,下面是对照组,右边是全体的笔记,不分组。在给实验组的用户做推荐的时候使用新的策略,给对照组的用户做推荐使用旧的策略。
在实验的过程中,对比两组消费指标的 diff。
3.1 用户侧实验
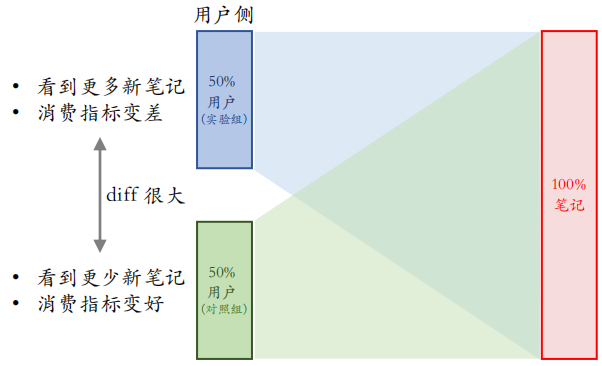
例如要考察策略对新笔记点击率或用户消费时长的影响,这种方法有个缺点:假设冷启要求做保量,要至少给新笔记 100 次曝光。还做个假设,新笔记曝光越多,用户使用 APP 时长越低。
现在使用一个新策略,即把新笔记排序时的权重增大两倍,这样让新笔记能获得更多的曝光。很明显这样的测试结果(只看消费指标)肯定会变差,AB 测试的 diff 是负数(策略组不如对照组)。如果推全,实际上的 diff 会缩小(比如 $-2\%$ → $-1\%$)。
为什么会变小?因为在做实验的时候,新笔记更多的曝光给实验组,导致实验组的消费指标变差,同时新笔记更少的曝光给对照组,所以对照组的消费指标会变好,所以实验组和对照组的 diff 会变得更大。所以在推全之后,这个 diff 相对于原来会变小。
3.2 作者侧实验
3.2.1 方案一
不对全体老笔记和用户做分组,但是要区别对待新笔记和老笔记。将新笔记按照作者分为两组,上面是实验组使用新策略,下面是对照组,使用老策略。
缺点在于新笔记之间会抢流量,比如在测试的时候发布指标涨了 $2\%$,但是在推全之后并没有什么变化。首先设定:
- 新老笔记走各自队列,新老笔记没有竞争
- 重排分给新笔记 1/3 流量,分给老笔记 2/3 流量
现在上一个新策略,把新笔记的权重增大两倍。在这种策略下没有任何变化,因为新笔记只和新笔记竞争,把所有新笔记的权重扩大两倍,相当于没有扩大,所以不会改变发布侧指标。但是 A/B 测试的 diff 是正数(策略组优于对照组),显示有正向收益,这是不合理的。
实验组给新笔记提权,对照组没有提权,那么实验组的新笔记会抢走对照组的曝光,因此实验组的发布指标会涨,对照组的发布指标会跌,这就产生了 diff。很显然,把新策略推全之后,diff 会消失(比如 $2\%$ → 0)。

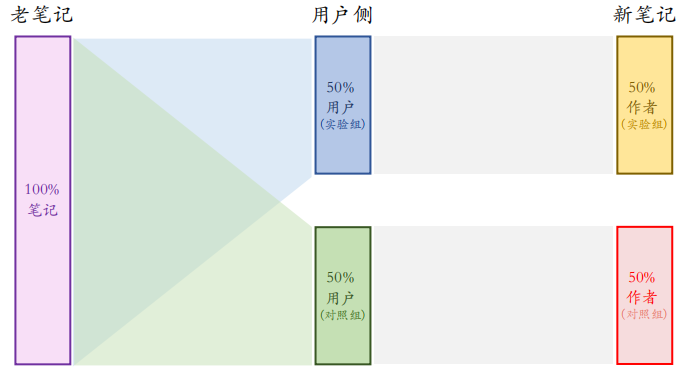
3.2.2 方案二
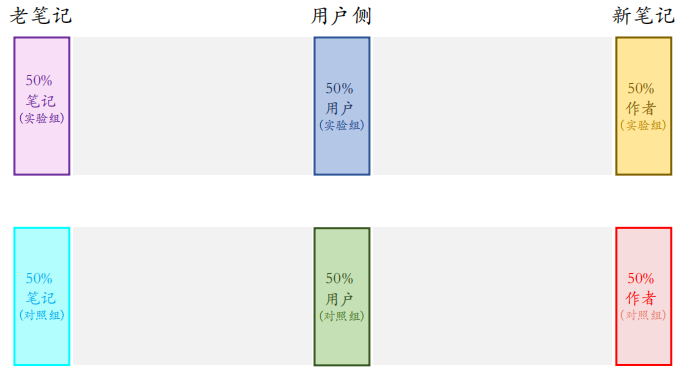
方案二和方案一的区别在于用户被分成了两组,上面是实验组,下面是对照组,实验组的用户只能看到实验组的新笔记,对照组的用户只能看到对照组的新笔记。
方案二比方案一的优缺点:
- 优点:新笔记的两个桶不抢流量,作者侧实验结果更可信
- 缺点:新笔记池减小⼀半,推荐结果变差,对用户体验造成负面影响
相同:新笔记和老笔记抢流量,作者侧 A/B 测试结果与推全结果有些差异。
3.2.3 方案三
这种方案不太可行,相当于把小红书分为两个 APP,内容质量减半,消费指标一定会大跌。
3.3 总结
冷启的AB测试需要观测作者发布指标和用户消费指标,这是因为冷启有两个目标,一个是激励作者发布,另一个是让用户满意。
各种AB测试的方案都有缺陷。设计方案的时候,问自⼰⼏个问题:
- 实验组、对照组新笔记会不会抢流量?
- 新笔记、老笔记怎么抢流量?
- 同时隔离笔记、用户,会不会让内容池变小?
- 如果对新笔记做保量,会发⽣什么?
 微信
微信 支付宝
支付宝








