
WSS推荐系统学习笔记7:用户行为序列建模
1 LastN 特征
LastN 表示用户最近的 $n$ 次交互(点击、点赞等)的物品 ID,可以反应出来用户最近对什么物品感兴趣。召回的双塔模型、粗排的三塔模型和精排模型都可以使用 LastN 特征,LastN 特征很有效。
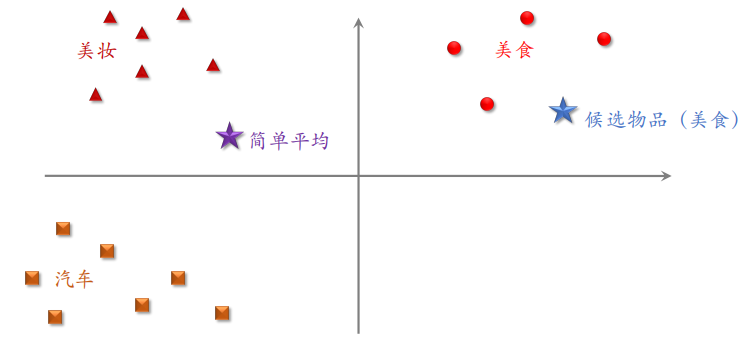
如下图所示,对 LastN 物品 ID 做 embedding,得到 $n$ 个向量。把 $n$ 个向量取平均得到一个向量,这个向量作为用户的⼀种特征,表示用户曾经对什么样的物品感兴趣。
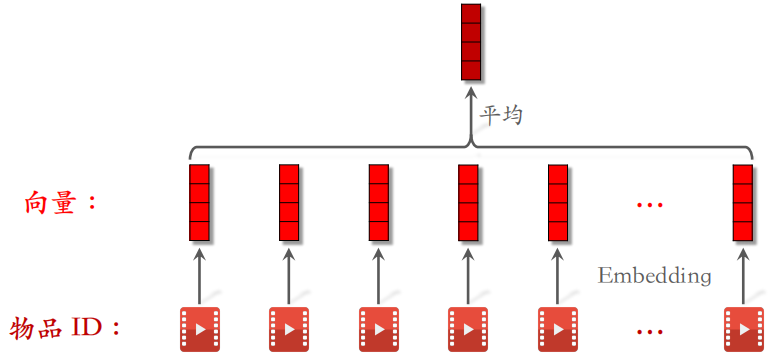
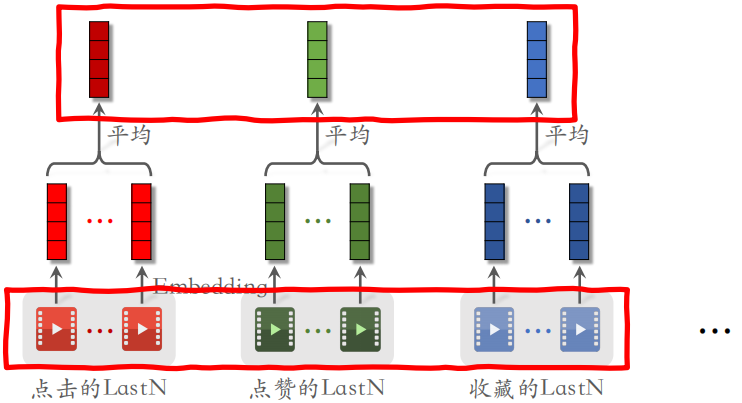
小红书的召回、粗排和精排都用到了 LastN 特征。可以对用户的最近点击过的、点赞过的和收藏过的物品 ID 做嵌入,然后取平均后得到相应的向量,把这些向量拼起来作为一种特征,用于召回等步骤。
2 DIN 模型(注意力机制)
2.1 工作原理
上面介绍的 LastN 特征是对嵌入后的向量取平均,但是取平均不是最好的方法。最近几年有很多论文提出了对 LastN 特征序列建模更好的方法。其中 DIN 是阿里在 2018 年提出的。
想法很简单,就是用加权平均代替平均,即注意力机制(attention)。其中权重是候选物品与用户 LastN 物品的相似度,哪个 LastN 物品和候选物品越相似,权重越大。
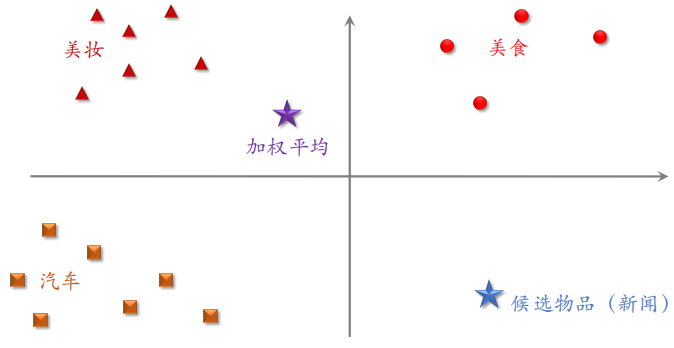
计算候选物品 $q$ 和第一个 LastN 物品的相似度 $\alpha_1$,和第二个 LastN 物品的相似度 $\alpha_2$,……,以此类推。把每个 $\alpha$ 与对应的向量相乘,然后进行加权和得到下面紫色的向量。
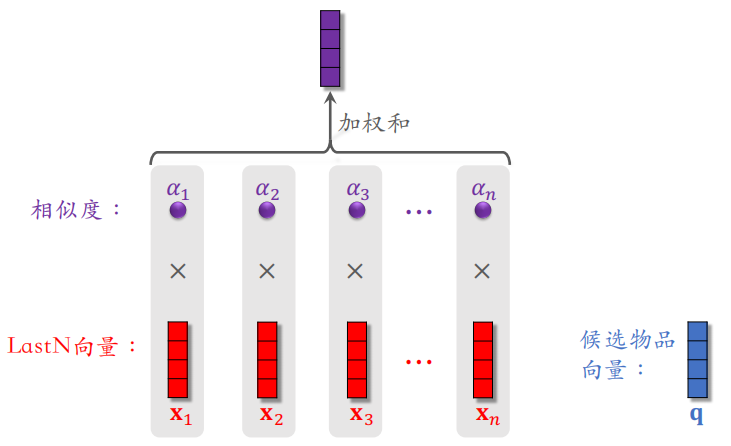
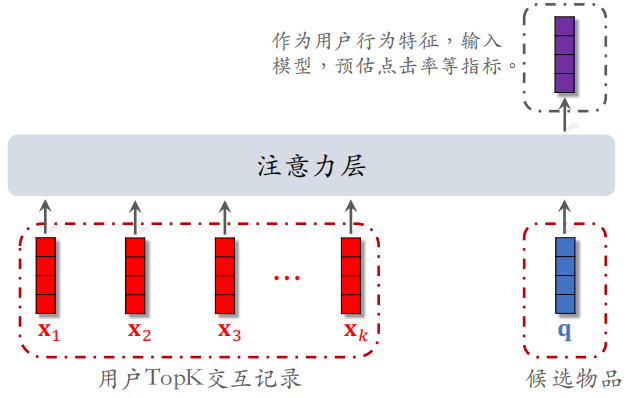
将上述过程总结如下:对于某候选物品,计算它与用户 LastN 物品的相似度。以相似度为权重,求用户 LastN 物品向量的加权和,结果是⼀个向量。把得到的向量作为⼀种用户特征,输⼊排序模型,预估(用户,候选物品)的点击率、点赞率等指标。
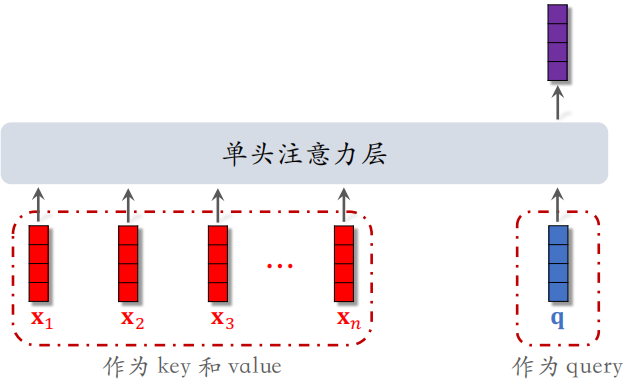
如下图所示,DIN 模型的本质是注意力机制(attention),其中把红色向量作为 $key$ 和 $value$,蓝色向量作为 $query$。
2.2 DIN 模型有效的原因
示例 1
示例 2
2.3 简单平均 vs 注意力机制
简单平均和注意力机制都适用于精排模型,同时简单平均也适用于双塔模型和三塔模型,因为简单平均只需要用到 LastN,属于用户自身的特征,只需要把 LastN 向量的平均作为用户塔的输入即可。
但是注意力机制不适用于双塔模型和三塔模型。因为注意力机制需要用到 LastN 和候选物品,但是用户塔在处理的时候是看不到候选物品的,所以不能把注意力机制用在用户塔。
3 SIM 模型(长序列建模)
3.1 DIN 模型回顾
DIN 模型的缺点:
- 注意力层的计算量 ∝ $n$(用户行为序列的长度),$n$ 越大,计算量就越大。
- 只能记录最近几百个物品,否则计算量太大。
- 关注短期兴趣,遗忘长期兴趣。
如何改进DIN?目标是保留用户长期行为序列($n$ 很大),而且计算量不会过大。
- DIN 对 LastN 向量做加权平均,权重是相似度
- 如果某 LastN 物品与候选物品差异很大,则权重接近零
- 快速排除掉与候选物品无关的 LastN 物品,降低注意力层的计算量
所以 SIM 模型需要保留用户长期行为记录,$n$ 的大小可以是几千,对于每个候选物品,在用户 LastN 记录中做快速查找,找到 $k$ 个相似物品。通过查找把 LastN 变成 TopK,然后输⼊到注意力层。SIM 模型减小计算量(从 $n$ 降到 $k$),再用注意力,$k$ 比较小,效果也很好。
3.2 Step1:查找
方法一:Hard Search(根据规则做筛选)
原理:根据候选物品的类目,保留 LastN 物品中类目相同的。
优点:简单、快速并且无需训练。
方法二:Soft Search
原理:把物品做 embedding,变成向量。把候选物品向量作为query,做 $k$ 近邻查找,保留 LastN 物品中最接近的 $k$ 个。
优点:效果更好,编程实现更复杂。
实验表明 Soft Search 比 Hard Search 效果更好,指标 AUC 更高。
3.3 Step2:注意力机制
注意力部分和 SIM 模型没有什么大的区别,主要的区别在于 $x_1,x_2, \dots,x_k$ 是用户 TopK 交互记录,而不是 LastN 记录。注意力层输出的紫色向量和其他特征一起作为用户行为特征送入精排模型中,用于预测点击率等指标。
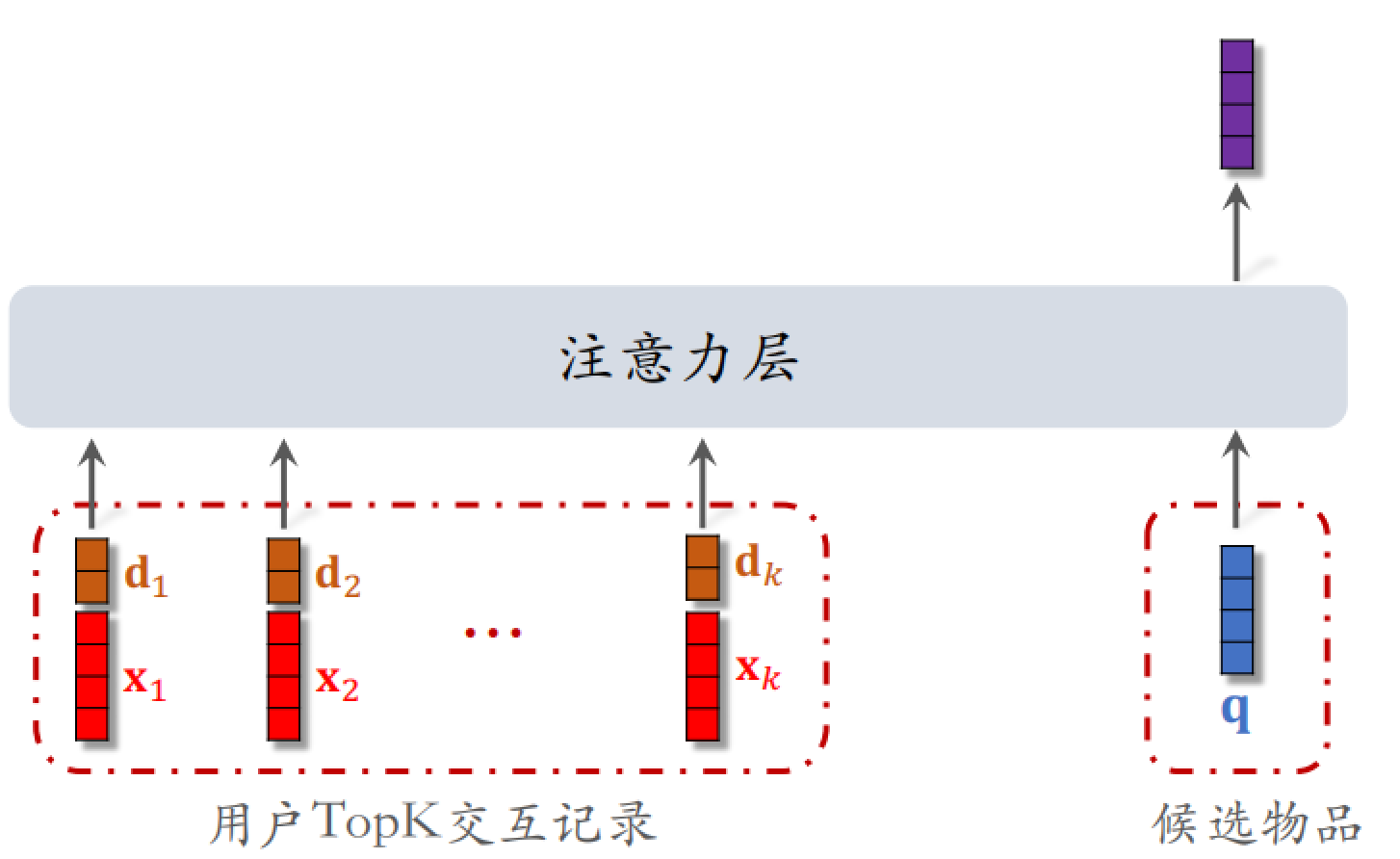
在这里有个技巧:使用时间信息。可以记录用户与某个 LastN 物品的交互时刻,距今为 $\delta$,对 $\delta$ 做离散化,划分成很多区间,再做 embedding,变成向量 $d$。
现在有两个向量,向量 $x$ 是物品 embedding,向量 $d$ 是时间的 embedding,把两个向量做 concatenation 拼成一个向量,表征⼀个 LastN 物品。
为什么 DIN 模型不使用时间信息,SIM 模型使用时间信息?
- DIN 的序列短,记录用户近期⾏为。
- SIM 的序列长,记录用户长期⾏为。
时间越久远,重要性越低,所以模型预测点击率的时候应该把时间也考虑到。
SIM 模型使用长序列(长期兴趣)优于短序列(近期兴趣),效果也更好。注意力机制显著优于简单平均。其中使用 Soft search 还是 hard search?取决于工程基建。
 微信
微信 支付宝
支付宝








