
WSS推荐系统学习笔记5:排序
1 多目标排序模型
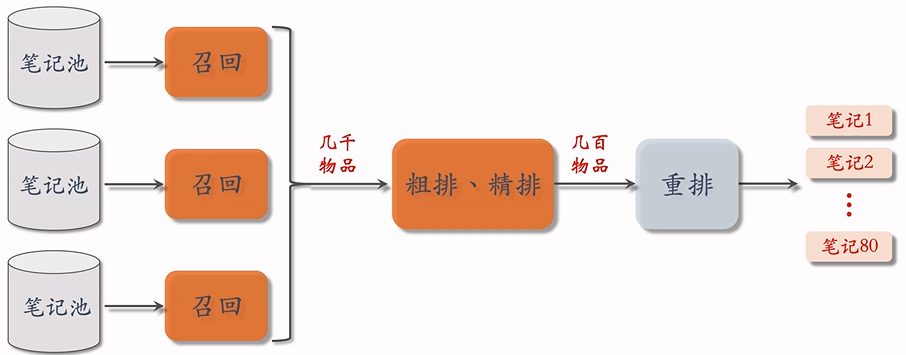
接下来主要研究粗排和精排,粗排和精排的原理差不多,在学习的过程中先不区分粗排和精排。
对于每篇笔记,系统记录:
- 曝光次数(number of impressions)
- 点击次数(number of clicks),点击率 = 点击次数 / 曝光次数
- 点赞次数(number of likes),点赞次数 = 点赞次数 / 点击次数
- 收藏次数(number of collects),收藏率 = 收藏次数 / 点击次数
- 转发次数(number of shares),转发率 = 转发次数 / 点击次数
排序模型预估点击率、点赞率、收藏率和转发率等多种分数,之后融合这些预估分数(比如加权和),根据融合的分数做排序、截断。
1.1 多目标排序
1.1.1 工作过程
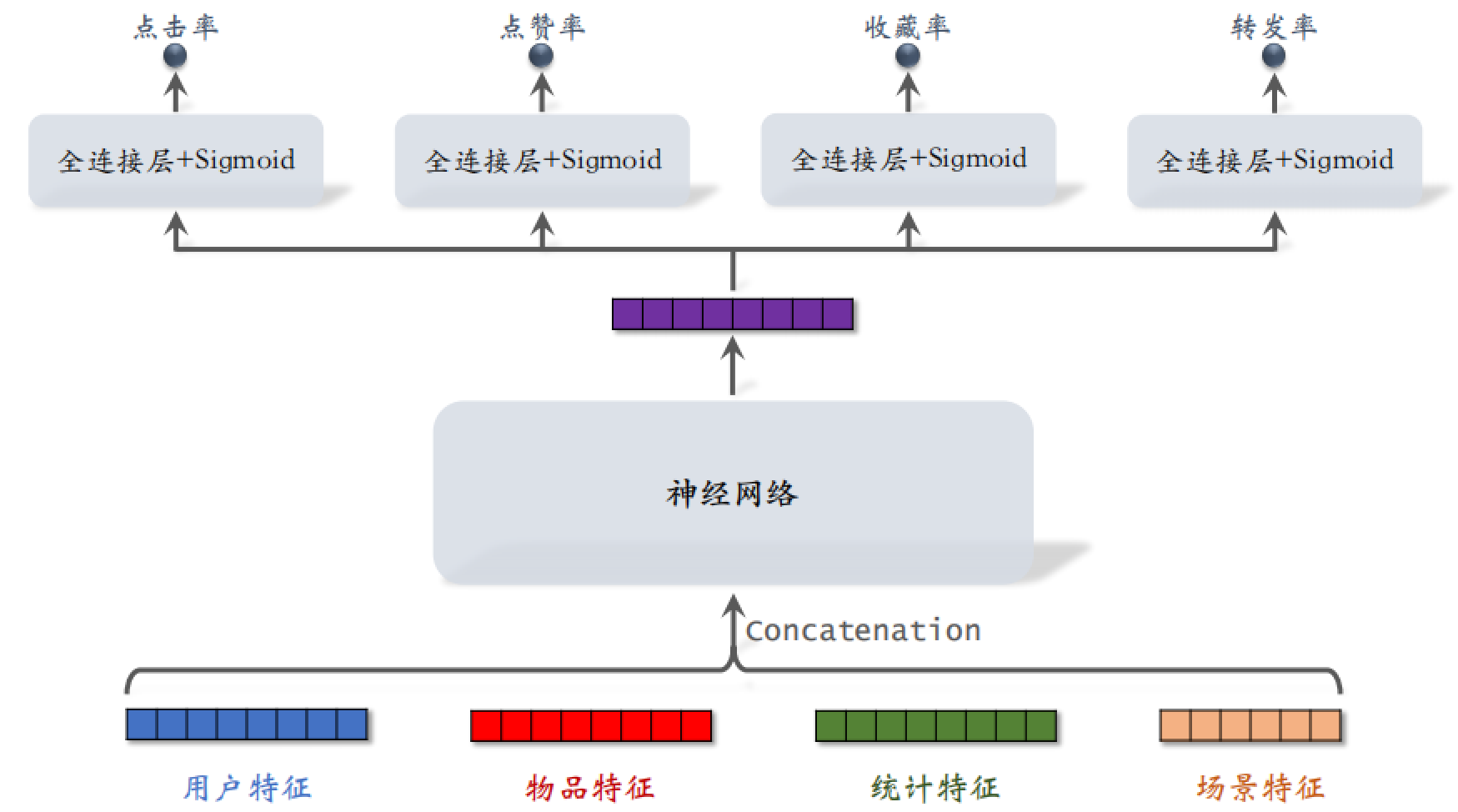
把用户特征、物品特征、统计特征和场景特征都输入神经网络,这些神经网络可以是很简单的神经网络,也可以是复杂的神经网络。
这个神经网络输出一个向量,之后把这个向量送入四个神经网络,这四个小神经网络各有 2~3 个全连接层,再通过 Sigmoid 激活函数得到点击率、点赞率、收藏率和转发率的预估值,这四个预估值都是实数,位于 $[0,1]$ 之间。
1.1.2 训练过程

下面的 $y$ 是用户真实的行为,是一个分类任务,可以使用交叉熵作为损失函数,$p$ 越接近于 $y$,则说明损失越小。之后把四个指标的损失合并为总的损失函数,在收集的历史数据上训练神经网络,做梯度下降。
$$
\sum_{i=1}^{4} \alpha_{i} \cdot \operatorname{CrossEntropy}\left(y_{i}, p_{i}\right)
$$
在训练的时候会出现类别不平衡的问题:
- 每 100 次曝光,约有 10 次点击、90 次无点击
- 每 100 次曝光,约有 10 次收藏、90 次无收藏
解决方法:负样本降采样(down-sampling),保留一小部分负样本,让正负样本数量平衡,节约计算。
1.2 预估值校准
设正样本、负样本数量为 $n_+$ 和 $n_{-}$,对负样本做降采样,抛弃一部分负样本。使用 $\alpha · n_{-}$ 个负样本,$\alpha \in (0,1)$ 是采样率。由于负样本变小,预估点击率大于真实点击率。
真实点击率的期望值为:
$$
p_{\text {true }}=\frac{n_{+}}{n_{+}+n_{-}}
$$
预估点击率的期望值为:
$$
p_{\text {pred }}=\frac{n_{+}}{n_{+}+\alpha \cdot n_{-}}
$$
由上面两个等式可得校准公式:
$$
p_{\text {true }}=\frac{\alpha \cdot p_{\text {pred }}}{\left(1-p_{\text {pred }}\right)+\alpha \cdot p_{\text {pred }}}
$$
2 MMoE
2.1 工作过程
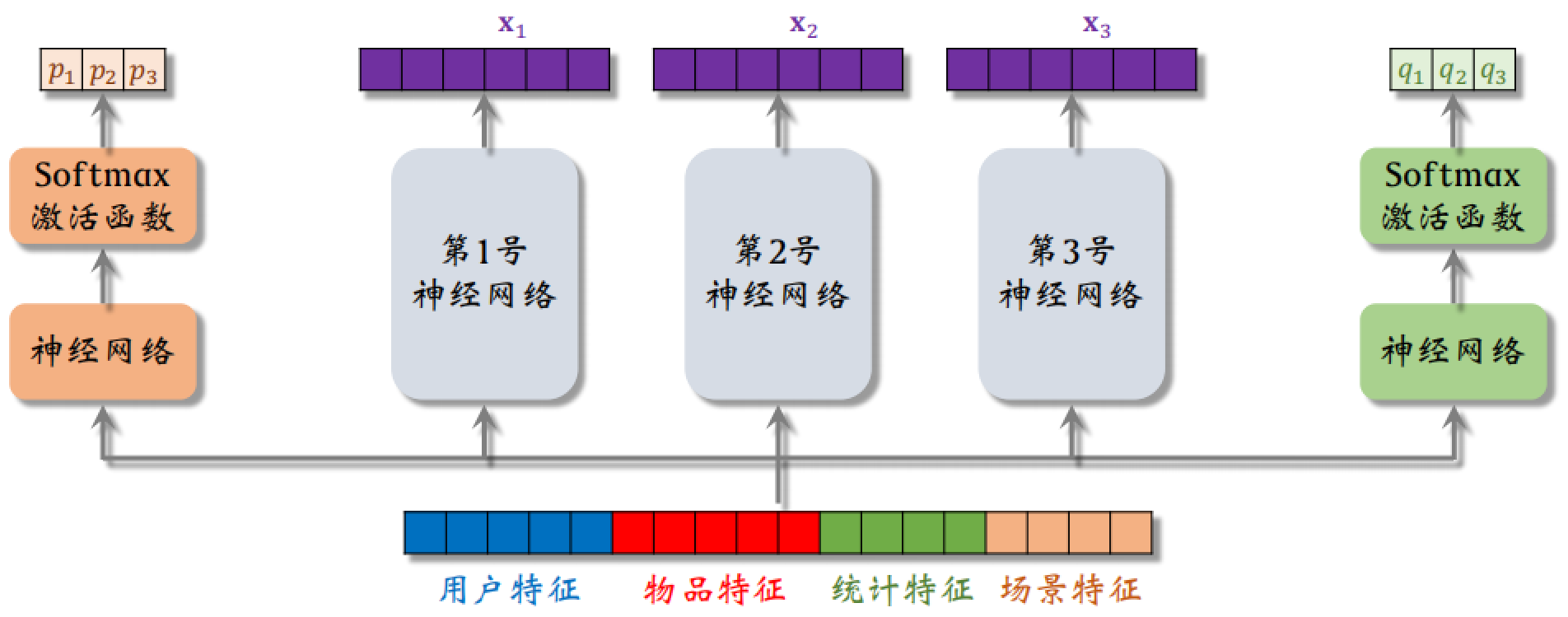
中间的 3 个神经网络相当于三个专家,每个专家神经网络各输出一个向量 $x_i$,同时也得到 $p_i$ 和 $q_i$,用于后面对 $x_i$ 的加权平均。
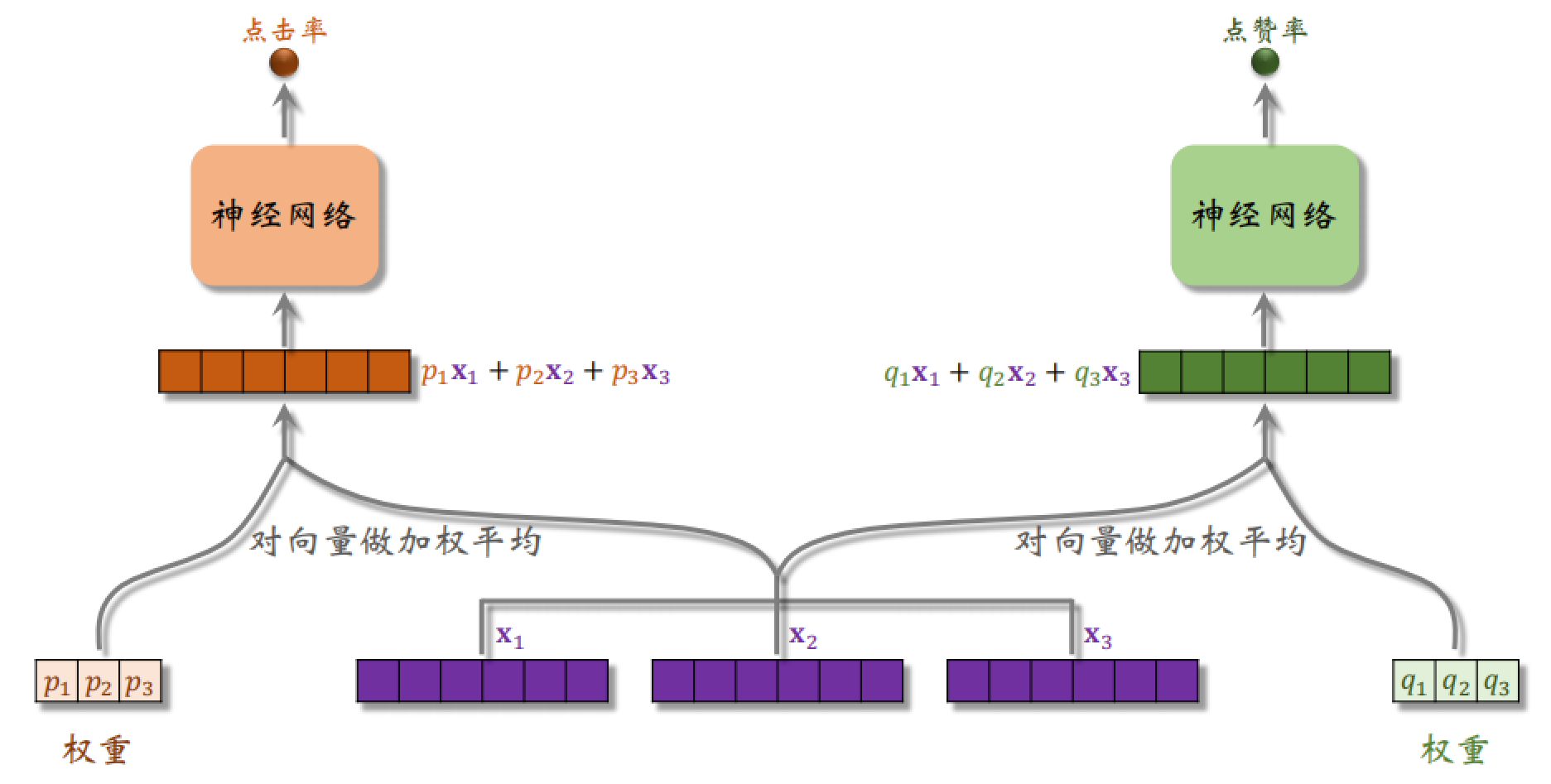
分别用两个权重进行加权平均得到不同的向量,之后送入不同的神经网络,得到不同指标的预估。
2.2 极化现象
上述例子中有两个 Softmax 激活函数,输出都是概率分布,各个元素大于零并且相加等于一。极化现象就是指 Softmax 输出值⼀个接近 1,其余接近 0。
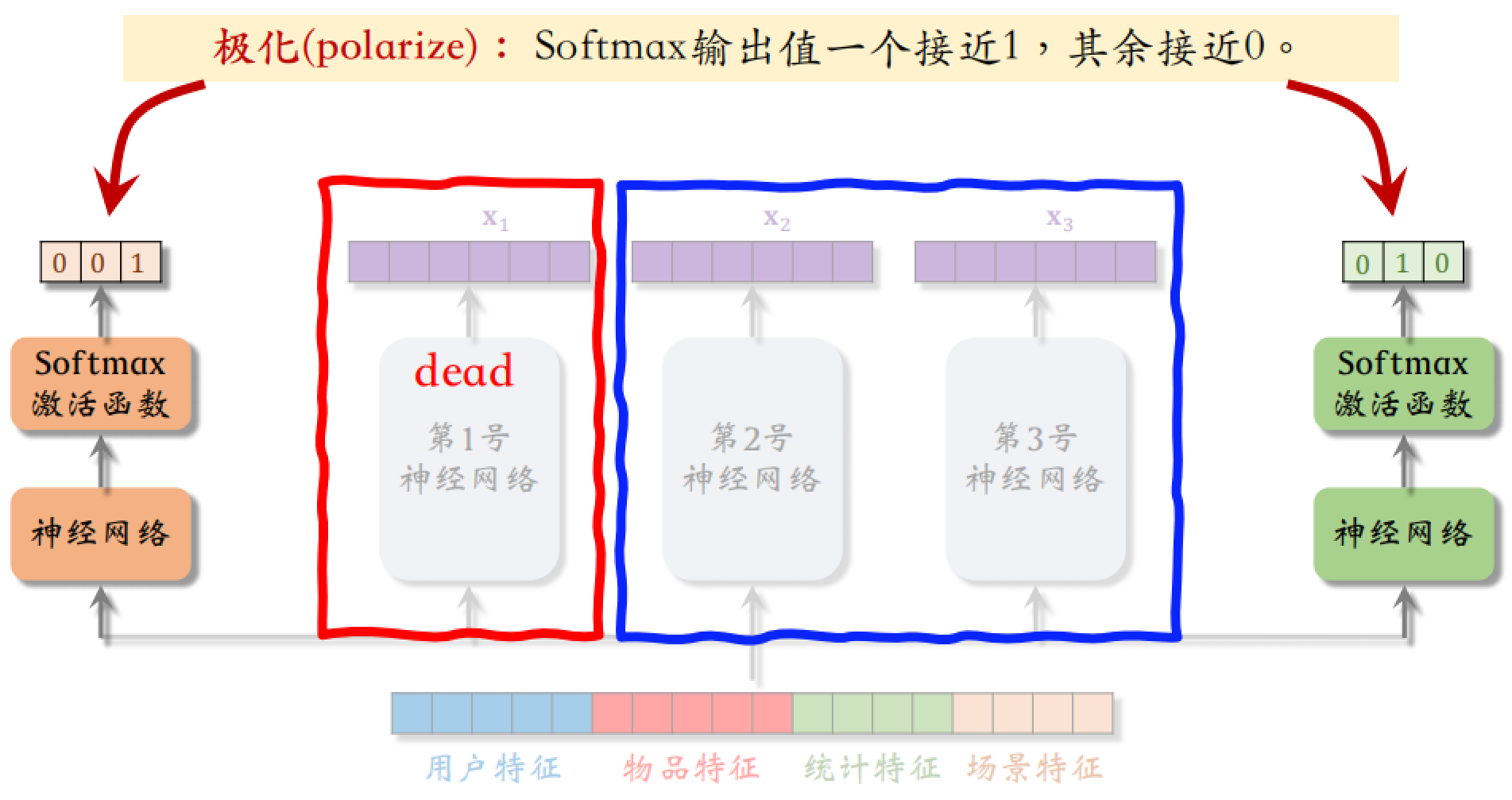
如果这种现象出现,相当于只使用了其中一个专家,有部分专家死掉了。如果有 $n$ 个专家,那么每个 Softmax 的输入和输出都是 $n$ 向量。
如何解决极化现象?在训练时,对 Softmax 的输出使用 Dropout,Softmax 输出的 $n$ 个数值被 mask 的概率都是 10%,则每个专家被随机丢弃的概率都是 10%。
3 融合预估分数
可以使用简单的加权和:
$$
p_{\text {click }}+w_{1} \cdot p_{\text {like }}+w_{2} \cdot p_{\text {collect }}+\cdots
$$
点击率乘以其他项的加权和:
$$
p_{\text {click }} \cdot\left(1+w_{1} \cdot p_{\text {like }}+w_{2} \cdot p_{\text {collect }}+\cdots\right)
$$
以上两种融合方式都很常见,海外某短视频 APP 的融分公式,跟上面的加权和有些有些区别:
$$
\left(1+w_{1} \cdot p_{\text {time }}\right)^{\alpha_{1}} \cdot\left(1+w_{2} \cdot p_{\text {like }}\right)^{\alpha_{2}} \cdots
$$
国内某短视频 APP 的融分公式,跟上面的做法完全不一样:首先根据预估时长 $p_{\text {time }}$,对 $n$ 篇候选视频做排序。如果某视频排名第 $r_{time}$,则它得分 $\frac{1}{r_{\text {time }}^{\alpha}+\beta}$,其中 $\alpha$ 和 $\beta$ 都是需要调节的超参数。对点击、点赞、转发、评论等预估分数做类似处理,最终融合分数:
$$
\frac{w_{1}}{r_{\text {time }}^{\alpha_{1}}+\beta_{1}}+\frac{w_{2}}{r_{\text {click }}^{\alpha_{2}}+\beta_{2}}+\frac{w_{3}}{r_{\text {like }}^{\alpha_{3}}+\beta_{3}}+\cdots
$$
某电商的融分公式:
$$
曝光 \rightarrow 点击 \rightarrow 加购物车 \rightarrow 付款
$$
模型预估出指标 $p_{click}$、$p_{cart}$ 和 $p_{pay}$,最终融合的分数为:
$$
p_{\text {click }}^{\alpha_{1}} \times p_{\text {cart }}^{\alpha_{2}} \times p_{\text {pay }}^{\alpha_{3}} \times price ^{\alpha_{4}}
$$
4 视频播放建模
4.1 对视频播放时长的预估
图文笔记排序的主要依据:点击、点赞、收藏、转发、评论……。视频排序的依据还有播放时长和完播,如果一个用户完整看完了视频,及时没有收藏、转发和点赞,也能说明用户对这个视频感兴趣。
但是直接用回归拟合播放时长效果不好,建议用 YouTube 的时长建模。
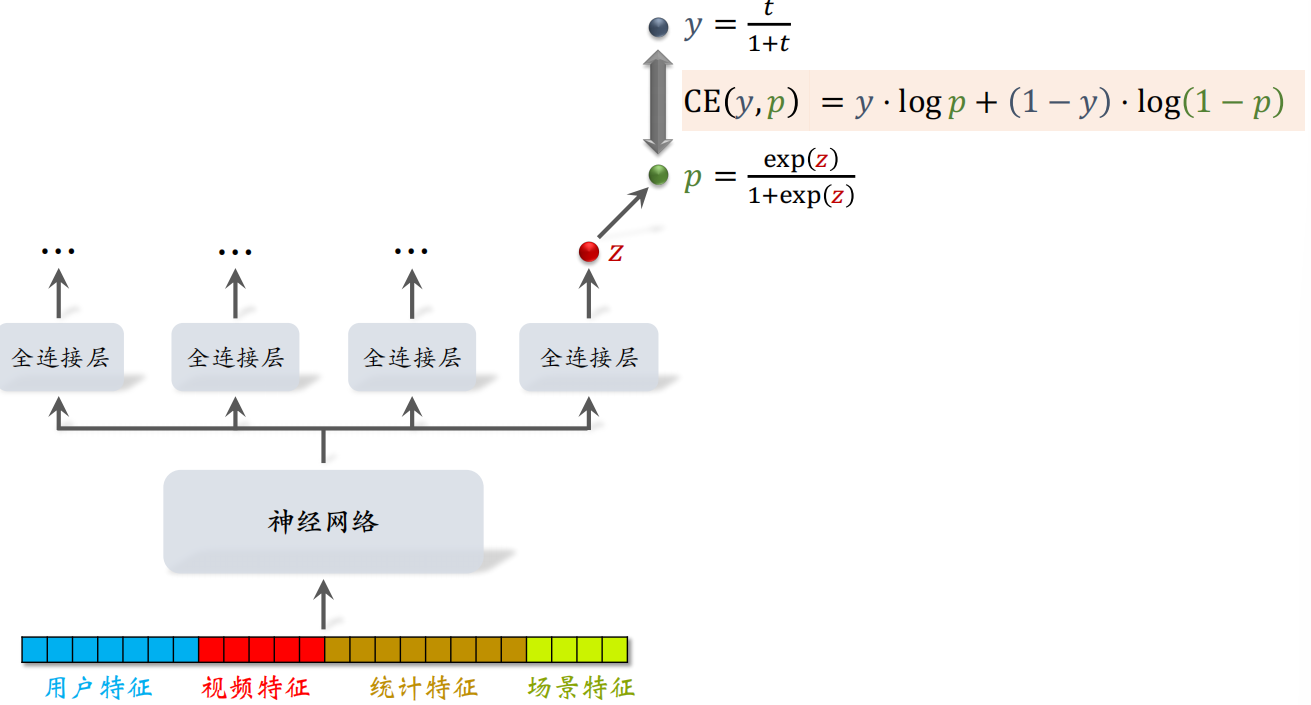
把相关特征送入神经网络之后,送入四个全连接层得到相关指标,其中得到一个实数 $z$,之后对 $z$ 做 Sigmoid 变换,即
$$
p=\frac{\exp (z)}{1+\exp (z)}
$$
得到 $p$,同时对实际的播放时长 $t$ 做以下变换得到 $y$:
$$
y=\frac{t}{1+t}
$$
把 $y$ 作为 $p$ 的标签,可以设计如下的交叉熵损失函数来更新参数:
$$
\operatorname{CE}(y, p)=y \cdot \log p+(1-y) \cdot \log (1-p)
$$
可以发现 $p$ 越接近于 $y$,则 $\exp(z)$ 越接近于 $t$,由于 $t$ 是实际的播放时长,所以可以使用 $z$ 来作为播放时长的预估。
因此在线上工作时,不用计算 $p$,只计算 $\exp(z)$ 来预估时长 $t$。
4.2 对视频完播的预估
4.2.1 回归方法
例如,视频长度 $10$ 分钟,实际播放 $4$ 分钟,则实际播放率为 $y = 0.4$,让预估播放率 $p$ 拟合 $y$:
$$
\operatorname{loss} =y \cdot \log p+(1-y) \cdot \log (1-p)
$$
线上预估完播率,模型输出 $p = 0.73$,意思是预计播放 $73 \%$。
4.2.2 二元分类方法
首先需要算法工程师定义完播指标,比如完播 $80\%$,若视频长度 $10$ 分钟,播放 $> 8$ 分钟作为正样本,播放 $< 8$ 分钟作为负样本。之后做二元分类训练模型:播放 $>80\%$ vs $<80\%$。
线上预估完播率,模型输出 $p = 0.73$,意思是:
$$
\mathbb{P}( 播放 >80 \%)=0.73.
$$
但是不能直接把预估的完播率用到融分公式,因为短视频更容易完播,但是长视频被看完很难。
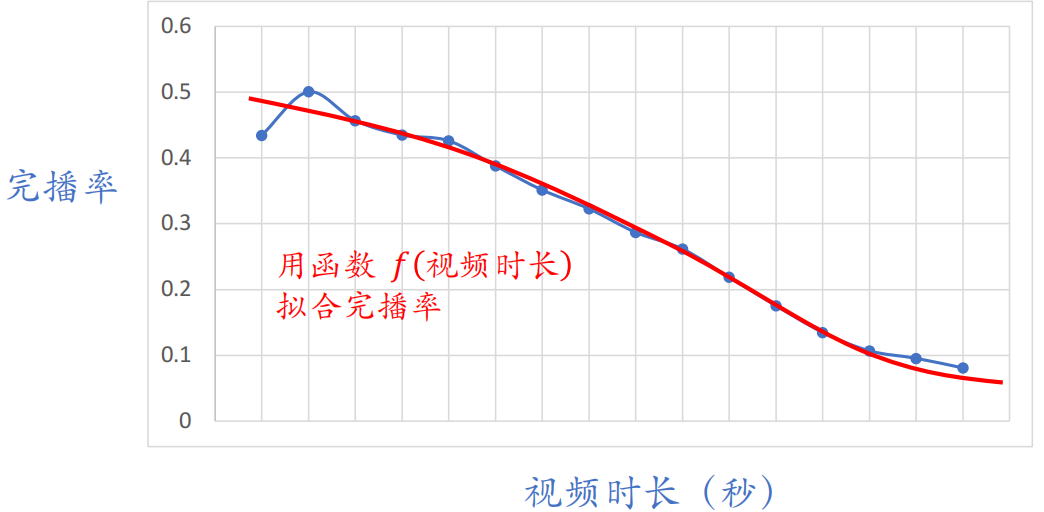
所以在线上预估完播率,然后根据视频长度做调整:
$$
p_{\text {finish }}=\frac{\text { 预估完播率 }}{f(\text { 视频长度 })}
$$
并把 $p_{\text {finish}}$ 作为融分公式中的⼀项。
5 排序模型的特征
5.1 用户和物品画像
5.1.1 用户画像
可以分为用户画像(User Profile)和物品画像(Item Profile),其中用户画像可以包含以下信息:
- 用户 ID(在召回、排序中做 embedding),通常用 32 位或 64 位向量
- 人口统计学属性:性别、年龄
- 账号信息:新老、活跃度……
- 感兴趣的类目、关键词、品牌
5.1.2 物品画像
物品画像可以包含以下内容:
- 物品 ID(在召回、排序中做 embedding)
- 发布时间(或者年龄)
- GeoHash(经纬度编码)、所在城市
- 标题、类目、关键词、品牌……
- 字数、图片数、视频清晰度、标签数……,反应出物品的质量
- 内容信息量、图片美学……,可以训练 CV 和 NLP 模型对物品打分
5.2 用户和物品统计特征
5.2.1 用户统计特征
用户最近30天(7天、1天、1小时)的曝光数、点击数、点赞数、收藏数等,用各种时间力度,可以反应出用户的实时兴趣、短期兴趣和长期兴趣。
也可以按照笔记图文/视频分桶(比如最近7天,该用户对图文笔记的点击率、对视频笔记的点击率),对这两类数据同时做记录,可以反应出用户的偏好。
按照笔记类目分桶(比如最近30天,用户对美妆笔记的点击率、对美⾷笔记的点击率、对科技数码笔记的点击率),如果用户对美食笔记的点击率偏高,那么说明用户对这个类目的笔记比较感兴趣。
5.2.2 笔记统计特征
跟用户特征类似,系统会记录笔记最近 30 天(7 天、1 天、1 小时)的曝光数、点击数、点赞数、收藏数。如果点击率、点赞率等指标都很高,说明笔记质量很高,算法应该给这样的笔记更多的流量。使用不同的时间粒度也是合理的,有些笔记的时效性很强,这样的笔记在长时间之后热度肯定会下降。
按照用户性别分桶(可以反应出笔记更受男性欢迎还是更受女性欢迎)、按照用户年龄分桶……
还有作者的统计特征如下,这些特征反映了作者的受欢迎程度,以及作者的平均品质,如果一个作者的作品平均品质很高,那么他新发布的作品的品质应该也会很高。
- 发布笔记数
- 粉丝数
- 消费指标(曝光数、点击数、点赞数、收藏数)
5.3 场景特征
场景特征是随着推荐请求传来的,不用从用户画像和笔记画像的数据库中获取。
- 用户定位 GeoHash(经纬度编码)、城市,用户可能对自己附近发生的事感兴趣
- 当前时刻(分段,做 embedding),用户不同时间对不同时间段发生的事情感兴趣
- 是否是周末、是否是节假⽇,节假日的时候可能对特定的话题感兴趣
- 手机品牌、手机型号、操作系统
5.4 特征处理
离散特征的处理很简单,就是做 Embedding,离散特征有:
- 用户 ID、笔记 ID、作者 ID
- 类目、关键词、城市、⼿机品牌
连续特征处理的第一种方法是做分桶,变成离散特征,例如年龄、笔记字数和视频长度等。也可以做其他变换,例如:
- 曝光数、点击数、点赞数等都是长尾分布,数值可以做 $\log(1+x)$
- 转化为点击率、点赞率等值,并做平滑
在做特征工程的时候,需要考虑一下特征覆盖率,很多特征无法覆盖 $100\%$ 样本:
- 例如很多用户不填年龄,因此用户年龄特征的覆盖率远小于 $100\%$
- 例如很多用户设置隐私权限,APP 不能获得用户地理定位,因此场景特征有缺失
提⾼特征覆盖率,可以让精排模型更准。除了特征覆盖率,还要考虑一下,当特征缺失的时候使用什么作为默认值。
5.5 数据服务
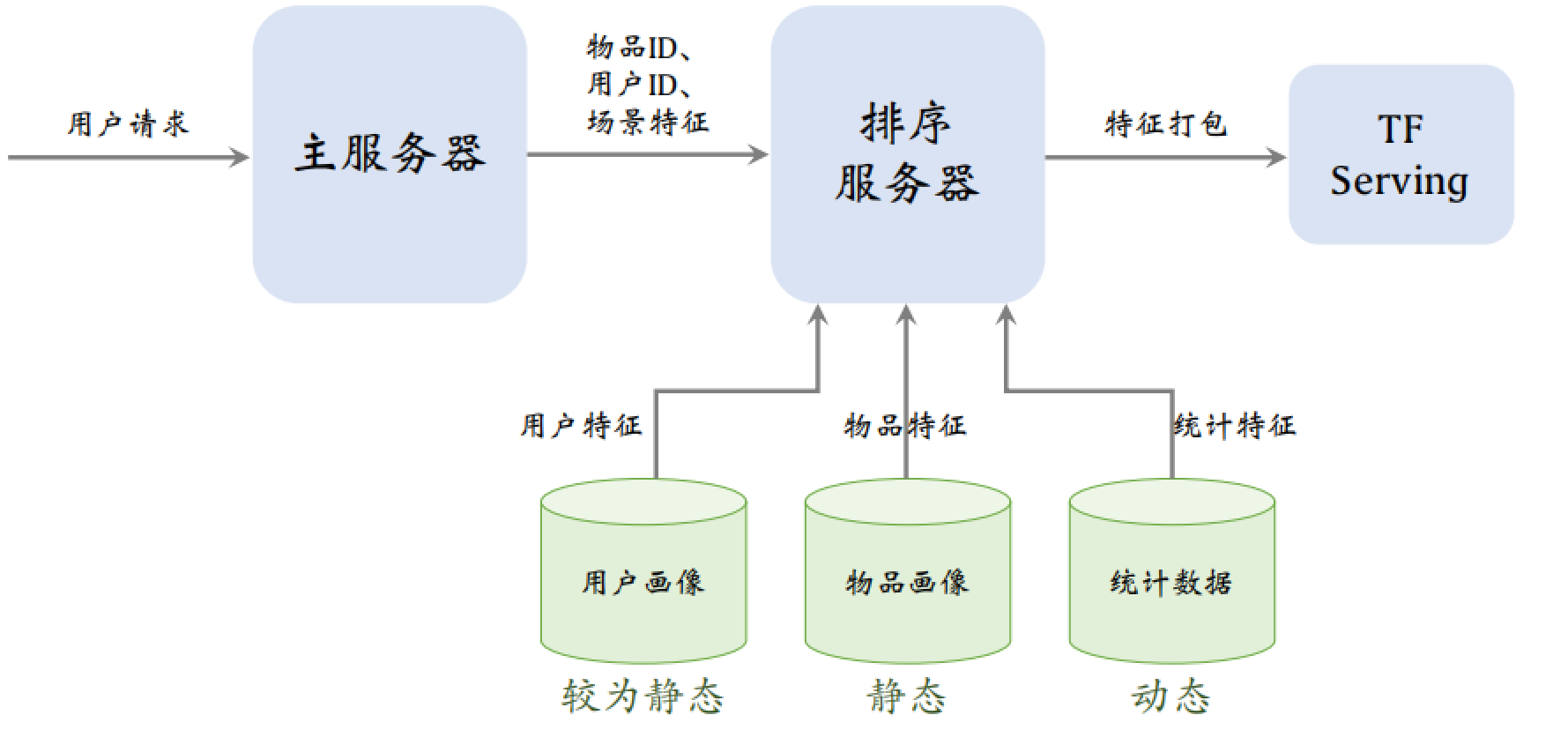
推荐系统中用到三个数据源:用户画像、物品画像和统计数据。三个数据源都存储在数据库中,在线上服务的时候,排序服务器会从三个数据源取出所需的数据,然后把读取的数据做处理,作为特征送入模型后,模型就能预估出点击率等指标。
6 粗排
粗排和精排的对比
| 粗排 | 精排 | |
|---|---|---|
| 工作量 | 给几千篇笔记打分 | 给几百篇笔记打分 |
| 推理代价 | 单次推理代价必须小 | 单次推理代价很⼤ |
| 准确性 | 预估的准确性不⾼ | 预估的准确性更⾼ |
6.1 粗排的三塔模型
6.1.1 模型架构
只有一个用户,用户塔只做一次推理,即使用户塔很大,总计算量也不大。
物品塔(较大):有 $n$ 个物品,理论上物品塔需要做 $n$ 次推理,PS 缓存物品塔的输出向量,避免绝大部分推理,只有遇到新物品的时候才需要做推理。
交叉塔(较小):统计特征动态变化,缓存不可行,有 $n$ 个物品,交叉塔必须做 $n$ 次推理。
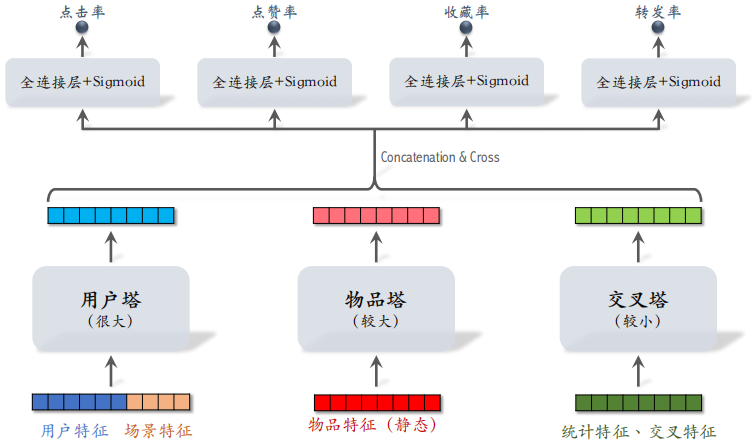
有 $n$ 个物品,模型上层需要做 $n$ 次推理,粗排推理的大部分计算量在模型上层。
6.1.2 模型推理
首先从多个数据源取特征:
- $1$ 个用户的画像、统计特征。
- $n$ 个物品的画像、统计特征。
不论有多少个候选物品,用户塔只做 $1$ 次推理。物品塔只有在未命中缓存时需要做推理,实际上 $99\%$ 的物品都会命中。交叉塔的输入是动态特征,不能做缓存,必须做 $n$ 次推理。
三个塔分别输出三个向量,把这三个向量融合起来,作为上层网络的输入。上层网络必须做 $n$ 次推理,给 $n$ 个物品打分,没有办法通过缓存减少计算次数。
 微信
微信 支付宝
支付宝








