
隐式(不可见)数字水印生成和攻击技术综述
1 摘要
随着数字内容的广泛传播,数字水印技术作为保护版权的重要手段得到了广泛关注。隐式数字水印(Invisible Watermarking)技术通过在媒体文件中嵌入信息而不影响其可视质量,成为一种有效的版权保护方案。这种水印不仅可以传递版权信息,还可以用于内容追踪和身份验证,极大地增强了数字内容的安全性。本文综述了针对图像、音频和视频的隐式数字水印常见生成技术和攻击技术,探讨了水印的鲁棒性及其在各种应用场景中的重要性。未来,随着人工智能和区块链技术的发展,隐式数字水印的应用前景将更加广阔。因此,深入研究其生成和攻击技术的改进将是一个重要的研究方向。
2 引言
过去几年,以网络视频为代表的泛网络视听领域的崛起,是互联网经济飞速发展最为夺目的大事件之一。泛网络视听领域不仅是21世纪以来互联网领域的重要基础应用、大众文化生活的主要载体,而且在推动中国经济新旧动能转化方面也发挥了重要作用。据中国网络视听节目服务协会发布的《2021年中国网络视听发展研究报告》显示,截至2020年12月,我国网络视听用户规模达9.44亿,2020年泛网络视听产业规模破6000亿元。然而,自泛网络视听诞生之初,盗版如同一颗毒瘤一样蔓延滋长,危害与日俱增,加强网络版权保护,任务紧迫而艰巨。
版权保护技术是指针对盗版侵权行为的确权存证以及监测、取证等技术。当前,区块链、人工智能、数字水印等版权保护应用主要集中在版权确权、监测、取证等环节;其中数字水印技术在版权确权、版权监测环节有着重要应用价值,数字水印具有查找侵权、追根溯源的能力,相比其他技术可以进一步实现对侵权行为的追踪溯源。
数字水印技术是将版权信息、唯一标识信息等以可见或不可见的方式嵌入数字作品载体中,用于证明作品来源。其中不可见的隐藏水印,具有肉眼不可发现但算法可以检测的特性,能够抵抗一定程度的剪切、拼接和编辑等操作。然而,随着盗版技术的不断升级,传统隐藏水印技术在复杂攻击场景中的鲁棒性面临着更加艰巨的挑战。攻击者可以通过复杂多样的编辑处理技术破坏被保护载体中所隐藏的版权信息,使得版权水印提取失效。
因此,数字水印技术的研究和发展迫在眉睫。未来的水印技术需要在鲁棒性、安全性和隐蔽性之间找到更好的平衡,以应对不断演变的盗版手段。同时,结合人工智能和区块链等新兴技术,将为数字水印的应用提供新的思路。
3 设计过程
无论是基于传统方法还是基于深度学习的数字水印技术,一个完整的数字水印系统的设计一般包括三部分:水印生成、水印嵌入和水印提取。
3.1 水印生成
水印信号可以通过多种方式生成,例如利用伪随机序列发生器或混沌系统,或是有意义的二值、灰度或彩色图像。通常为了携带更多的版权信息,人们倾向于使用二值图像或灰度图像来表示水印,例如产品序列号或图标等。对于有意义的水印序列,为了增强水印信息的安全性并提高其抵抗恶意攻击的能力,可以使用置乱技术对水印进行预处理,以消除水印信息之间的相关性。
3.2 水印嵌入
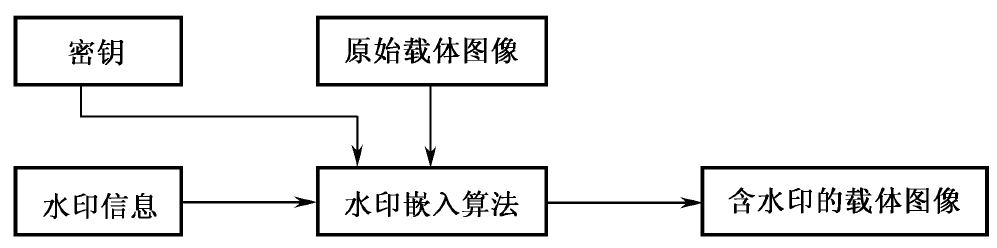
水印嵌入是将水印信息嵌入到载体图像中的过程,它可以通过不同的技术和算法实现。在嵌入的过程中,水印信息被融合进载体图像的特定区域,使其在视觉上不易察觉。嵌入过程如图3.1所示。
3.3 水印提取
水印提取是从载体图像中提取水印信息的过程,它涉及使用特定的算法来从图像中提取已嵌入的水印,这些算法会根据水印嵌入的方式采取相应的措施。水印提取过程如图3.2所示。

4 技术背景
在探讨数字水印技术的具体应用之前,了解其技术背景至关重要。本节将深入分析数字水印的相关技术概念。
4.1 隐写术(Steganography)
隐写术一般指的是向图像或者视频等信息载体中嵌入隐秘信息,其中大部分隐写术算法都是基于空域等知识进行信息嵌入。近年来图像隐写术的发展也是层出不穷,从最早期的LSB、LSB-Match到内容自适应隐写术:HUGO$^{\mathrm{[1]}}$(空域自适应隐写算法)、WOW$^{\mathrm{[2]}}$、SUNIWARD$^{\mathrm{[3]}}$,再到如今的深度学习隐写术。隐写术算法已经可以自动的将隐秘信息嵌入到纹理、噪声丰富的图像区域,并保持复杂的图像高阶统计特性。
4.2 隐写分析(Steganalysis)
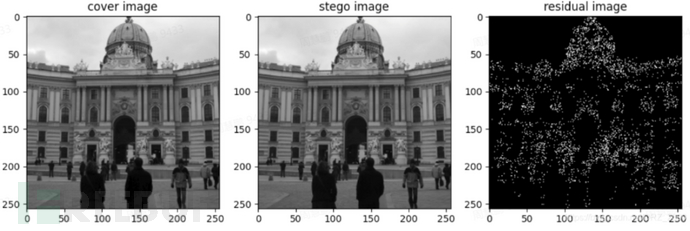
隐写分析是通过对图像的统计特性进行分析,判断图像中是否隐藏有额外的信息甚至估计信息嵌入量、获取隐藏信息内容的技术。目前的隐写分析研究领域通常将隐写分析看成一个二分类问题,目标是区分载体图像和载密图像。图4.1展示了一个隐写分析的例子(图例来自数据集BOSSbase_1.0.1),左图为载体图像,中间为载密图像,右图为差异图像(载体图像与载密图像之间的差异图像)。
隐写分析方法一般分为两类。一类是基于传统特征的图像隐写分析方法,这一类方法主要包含特征提取、特征增强和特征分类器三部分;其中特征提取与增强部分对于后面训练分类器有着决定性的作用,且特征选择非常依赖于人工,存在耗时长、鲁棒性差等缺陷,代表的隐写分析模型有SPAM$^{\mathrm{[4]}}$、SRM$^{\mathrm{[5]}}$、DCTR$^{\mathrm{[6]}}$等。
另一类方法是基于深度学习的隐写分析方法,模型主要分为半学习模型和全学习模型。半学习模型依靠SRM的30个滤波核作为预处理层来进行网络的学习,代表的网络有Xu-Net$^{\mathrm{[7]}}$、Ye-Net$^{\mathrm{[8]}}$等。全学习模型则完全依靠深度神经网络强大的学习能力从纷繁复杂的像素信息中学习到重要的残差特征信息,代表的深度网络SRNet$^{\mathrm{[9]}}$等。全学习深度网络在检测精度上要优于半学习深度网络并且更具有鲁棒性。
4.3 数字水印(Digital WaterMarking)
数字水印技术是指将特定的编码信息嵌入到数字信号中,数字信号可能是音频、图像或是视频等。若要拷贝有数字水印的信号,所嵌入的信息也会一并被拷贝。数字水印技术是一种基于内容的、非密码机制的计算机信息隐藏技术,是保护信息安全、实现防伪溯源、版权保护的有效办法。数字水印一般分为明水印和隐藏水印。隐藏水印通过在载体数据(音频、视频等)中添加隐藏标记,在一般情况下无法被人眼以及机器所辨识。隐藏水印的重要应用之一就是保护著作权,期望能借此避免或阻止数字媒体未经授权的复制和拷贝。
4.4 水印检测(Watermark Detection)
隐藏水印信息检测的方法一般有两种。一种是基于自相关的检测方法,这种方法是根据水印嵌入算法提出的相关函数生成对应的检测算法,另一种则是利用模版匹配的方法,该方法利用图像处理中模板匹配的思想,在添加水印时制定一个模板,通过模板来添加水印;在检测水印时,在待测图像上使用模板进行相似度计算;当相似度超过设定的阈值时便认定检出水印,反之则无水印。
5 评估指标
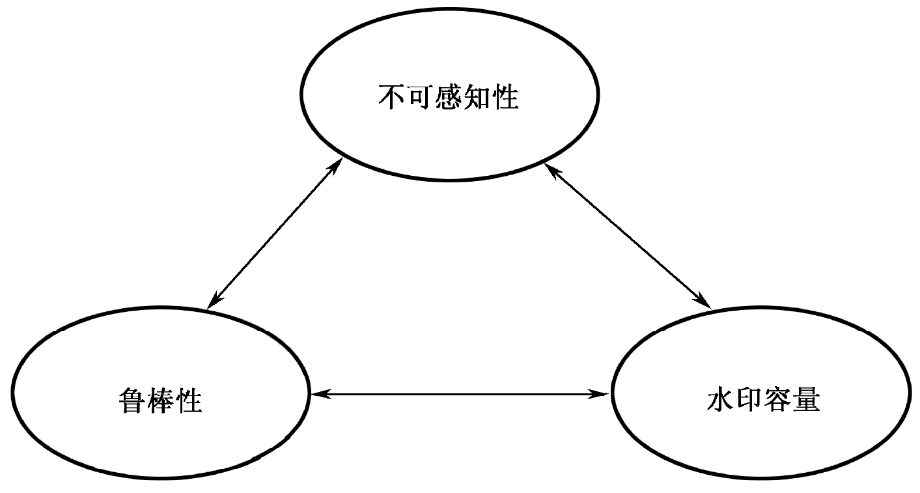
数字水印算法有多种评估标准,主要有以下三个标准:不可感知性、鲁棒性和容量。
5.1 不可感知性
不可感知性指的是载体嵌入水印前后不会引起感知上的明显变化。当评估数字水印算法的不可感知性时,常用的指标是结构相似性指标(SSIM)和峰值信噪比(PSNR)。
SSIM衡量两幅图像之间的结构相似性,考虑了亮度、对比度和结构三个方面的相似度。其数学表达式为:
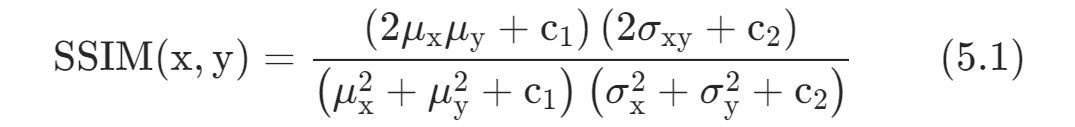
其中$x$和$y$分别代表两幅图像,和分别是$x$和$y$的均值,和分别是它们的方差,是它们的协方差,$c_{\mathrm{1}}$和$c_{\mathrm{2}}$是为了稳定性而加入的常数。
而 PSNR(峰值信噪比)则用于衡量图像的质量损失程度,其数学表达式为:
$$
\operatorname{PSNR}=10 \cdot \log _{10}\left(\frac{\mathrm{MAX}^{2}}{\mathrm{MSE}}\right) \quad \quad (5.2)
$$
其中,MAX(极限值)是图像的最大可能像素值,MSE(均方误差)代表图像之间的均方误差。
这两个指标常用来评估数字水印算法对图像质量的影响,一般来说,较高的SSIM和较高的PSNR值表示水印嵌入对图像质量的影响较小,即水印图像的不可感知性较好。
5.2 鲁棒性
鲁棒性是指数字水印算法抵抗各种攻击的能力,例如JPEG压缩、旋转、剪切、添加噪声等。使用鲁棒性强的水印算法嵌入水印的图像在经历多种攻击后,在提取水印信息时依然有较高的提取成功率。评估鲁棒性常用的指标包括错误率、提取成功率等。
5.3 容量
图像水印容量指的是在载体图像中可以隐藏的最大水印信息量。它的大小受多种因素影响,包括载体图像的统计特性、失真限度,以及水印嵌入和提取算法是否能够充分利用载体图像。不同的应用场景对水印容量有着不同的需求和限制。
5.4 性能指标之间的关系
数字水印的鲁棒性、不可感知性和容量之间存在一种相互制约的关系,这种关系可以通过图5.1进行展示。当三者中的任何一个参数被固定时,剩下的两个参数之间会存在矛盾。举例来说,若水印容量被设定为一定数值,为了提高水印的鲁棒性,可能需要增加水印的嵌入强度,而这样必然会导致更大的图像失真。同理,若降低水印的嵌入强度以保证较好的图像质量,那么水印的鲁棒性就可能会降低。因此,在设计水印算法时,常常需要在水印鲁棒性、不可感知性和容量之间取得一种平衡,根据实际应用需求进行权衡处理。
6 针对图像的数字水印生成和攻击
6.1 传统图像数字水印生成方法
传统数字水印方法通常基于信号处理、信息论和密码学的原理,通过手工设计的算法或规则实现水印嵌入和提取,分为空域和变换域方法。典型的算法有基于对称性的局部几何失真鲁棒水印。
(1)空域方法直接在原始图像中嵌入水印,例如修改像素值或调整图像的特定属性来隐藏信息。
(2)变换域方法则是在图像的变换域进行操作,比如在频域或小波域中嵌入水印。这些传统方法中的常用变换包括离散余弦变换(DCT)、离散小波变换(DWT)、离散傅里叶变换(DFT)、奇异值分解(SVD)等,它们各自有不同的优势和适用场景。
6.2 深度学习图像数字水印生成方法
深度学习水印算法是基于深度学习技术的新兴数字水印方法,与传统数字水印方法有所不同。传统方法基于信号处理、信息论和密码学,通过手工设计的算法实现水印的嵌入和提取,相比之下,深度学习水印算法利用神经网络等深度学习模型来处理水印信息。
现有的基于深度学习的水印方案主要使用的是E-N-D框架$^{\mathrm{[10]}}$。此类框架包含编码器(Encoder)、噪声层(Noise Layer)和解码器(Decoder)三个部分,如图6.1所示。
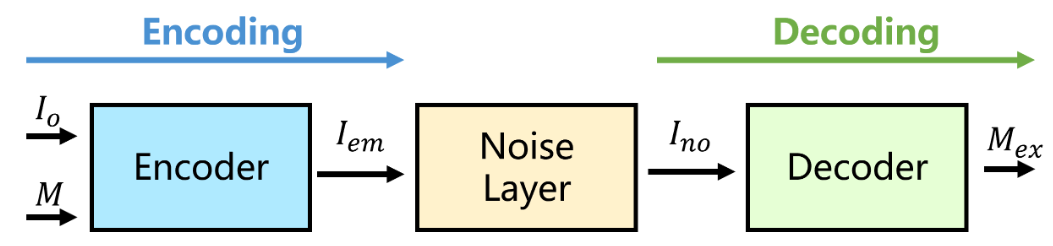
编码器学习将水印消息嵌入到载体图像中,噪声层使带水印的图像失真,模拟真实信道中的失真过程,解码器则尝试从失真的图像中提取水印信息。在训练过程中,这三个组件共同进行联合训练,而在实际使用阶段,噪声层部分被真实的信道代替,仅使用编码器和解码器进行水印嵌入和提取。
E-N-D框架的设计允许模型通过不同的噪声层学习适应各种失真情况,从而增强了水印算法对不同干扰的鲁棒性。下面介绍2种基于E-N-D框架的典型算法。
6.2.1 基于条件可逆神经网络的深度学习图像隐式水印
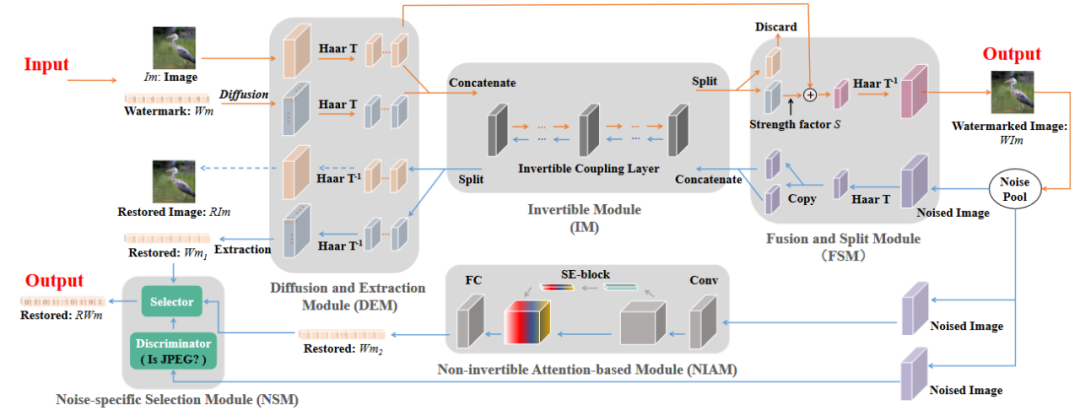
利用可逆神经网络对于复杂高维密度建模的优秀性能,将基于流的归一化可逆神经网络与水印的嵌入提取过程相结合,实现了高效的水印提取和图像恢复,具体实现方法如图6.2所示。
(1)扩散与提取(DEM)
对于前向嵌入过程,DEM接受原始图像与水印信息作为输入,其中水印信息经过如下变换扩散到与图像相同的维度上,与经过Haar变换的原始图像一同输入到可逆网络模块。由于这部分的数据处理均为可逆,所以在水印提取过程中即可方便的经过逆运算重新得到输入。
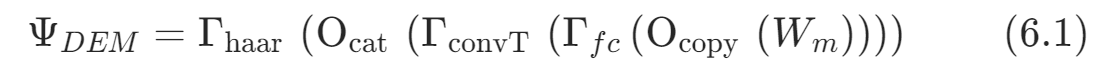
(2)可逆网络(IM)
该模块接受连接后的原始图像和水印信息为输入,在可逆网络中的耦合层通过加性仿射变换将水印信息映射到符合在图像中嵌入水印要求的分布,以达到鲁棒嵌入和不可感知的目的。
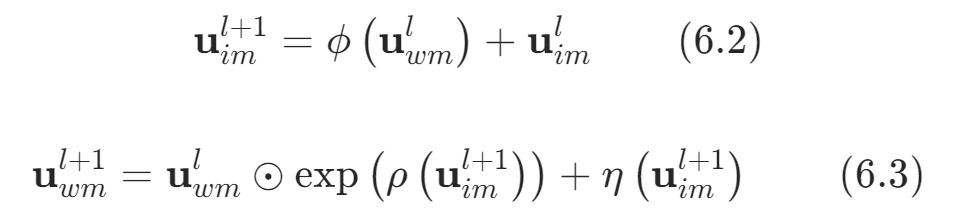
(3)融合和分离(FSM)
可逆网络的输出可以分为两部分,舍弃输出的图像部分,仅保留映射后的水印信息,并将后者添加到原始图像中,得到最终的水印图像。同样的,该部分的可逆性允许从水印图像中恢复水印信息与图像。
$$
W I_{m}=\Gamma_{\text {haar }}^{-1}\left(\Psi_{\text {inv }}^{I I}\left(x ; L R_{-}, H R_{-}\right) \times S+\Gamma_{\text {haar }}\left(I_{m}(x ; L R, H R)\right)\right) \quad \quad (6.4)
$$
(4)噪声层与不可逆提取
作为鲁棒水印的硬性要求,生成的水印图像在经过若干噪声层后对其水印信息应该保持良好的提取率,以上可逆网络中水印的嵌入和提取具有确定性的映射关系,这使得在没有或有加性噪声的场景中水印提取精度得到良好的结果。然而,当受到有损压缩或复杂的非加性噪声时,可逆网络的前向和后向共享同一组参数,解码器的参数会随着编码器的更新而更新,这限制了解码器的能力应对复杂的噪音。
因此,框架中引入了一个额外的解码器,以增强对有损压缩噪声的鲁棒性。不可逆模块使用SENet作为主干来提取水印信息,并且额外训练了一个特定噪声选择模块(NSM),由此判断水印图像是否经过了有损压缩的噪声层,最终决定选择由可逆或不可逆网络提取出的水印消息为准。
6.2.2 基于mini-bactch的深度学习图像隐式水印框架
如图6.3所示,在端到端的基于深度学习的水印方案中,该模型$^{\mathrm{[13]}}$使用Encoder-Noise Layer-Decoder的三层结构。一共结构包括五个组件:
- 参数为$\theta_M$的消息处理器MP接收长度为$L$的二进制秘密消息$M∈{0,1}^{\mathrm{L}}$,并输出消息特征映射$M_{e n} \in \mathbf{R}^{C^{\prime} \times H \times W}$,其中$C’$是特征地图的通道数;
- 参数为$\theta_E$的编码器$E$以$3×H×W$的形状接收RGB cover图像$I_{\mathrm{co}}$,消息特征映射$M_{\mathrm{en}}$作为输入,并对形状为$3×H×W$的编码图像$I_{\mathrm{en}}$进行乘积;
- 噪声层根据MBRS方法随机选取噪声。它接收$I_{\mathrm{en}}$并输出相同形状的噪声图像$I_{\mathrm{no}}$;
- 带有参数$\theta_D$的解码器$D$从噪声图像$I_{\mathrm{no}}$中恢复长度为$L$的秘密消息$M’$;
- 带有参数$\theta_A$的对手鉴别器$A$接收图像$I_{\mathrm{en}}$或$I_{\mathrm{co}}$以预测给定图像被编码的概率。
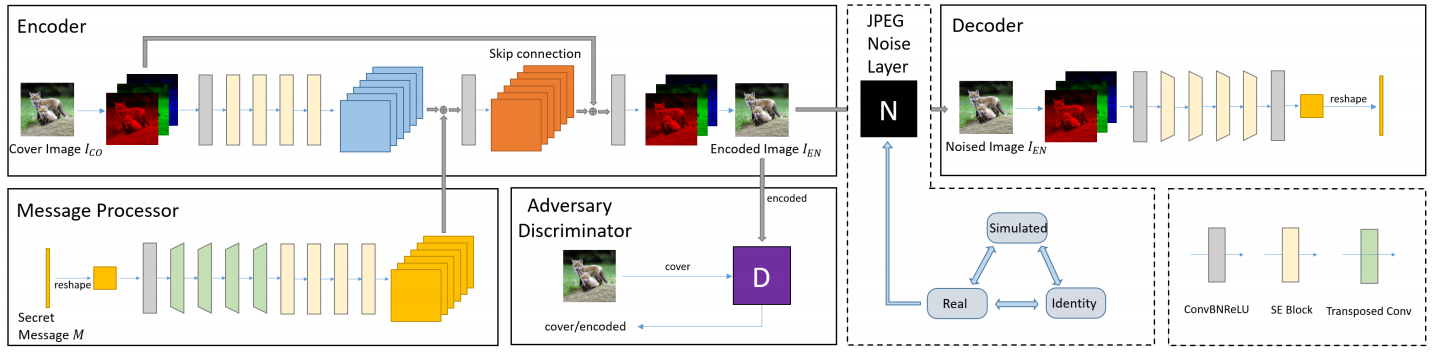
在上述过程中,透明性和鲁棒性是直接影响性能的两个方面。实现透明性的关键是在保证鲁棒性的前提下嵌入尽可能少的水印信号,换言之,嵌入器需仅嵌入解码器需要的信号。因此,核心问题是嵌入器与解码器能否高效耦合。实现鲁棒性的关键是噪声层的设计,噪声层中的失真决定了算法的鲁棒性。为了实现训练,一般要求噪声层可导,因此,对不可导失真(例如JPEG压缩)的噪声层设计是重要的难点问题。
然而,在端到端的结构中,对JPEG图像进行水印的嵌入时,JPEG压缩是信道传输中的常见失真,因此,MBRS的方法旨在训练一个抗JPEG压缩的基于深度学习的鲁棒水印方案。在学习JPEG压缩失真的过程中首要面对的挑战是JPEG压缩中存在不可导的量化过程,使得如果直接使用真实JPEG作为噪声层训练,产生的梯度不可回传,不能有效优化网络。在以往的工作中,尝试使用模拟JPEG信息代替真实JPEG信息保证梯度下降更新,但是模拟JPEG无法保证完全学习真实JPEG信息,因此在MBRS方法中希望引入真实JPEG信息而又可以正常反向传播计算梯度。
为了解决模拟JPEG损失和真实JPEG不可导失真的矛盾,MBRS方法提出使用mini-batch的策略,在每一个训练的小batch里随机从无失真(Identity),真实JPEG和模拟JPEG中选择一种作为噪声层,优化器选择带动量的Adam优化器,这样真实JPEG虽然不可回传梯度,但另两种失真却能通过优化器的特性保证大体的梯度回传方向。除了在噪声层使用mini-batch策略实现真实JPEG信息的学习,编码器和解码器阶段都采用基于SE-Net的框架。
算法整体流程如下:首先将待嵌入的水印消息通过预处理卷积层上采样到与图像隐藏层相同的大小,经过级联卷积后输出含水印图像。含水印图像传入噪声层中,在噪声层中采用上述mini-batch的策略随机在每一个batch中选择噪声层,以更好的鲁棒性训练。最后将选择较好的带噪声失真的含水印图像输入解码器。
6.3 生成图像数字水印生成方法
近两年生成模型的陆续发布和开源降低了用户利用AIGC造假的门槛,Facebook等主流的UGC内容平台上已经充斥着大量AI生成的多媒体信息。这些平台都有识别和追溯这些信息真实性的迫切需求。因此,最近提出了生成图像水印方法,将水印生成和水印嵌入过程合并到图像生成过程中。生成图像水印的嵌入不是发生在图像生成之后而是发生在图像生成过程中,这意味着实际样本并不带有经典加法意义上的水印,而是隐藏在图像分布中的水印。这类方法为内容平台追踪和验证信息真实性提供了一种新的可能性。
6.3.1 针对扩散模型的鲁棒和不可见的树环水印
与现有的在采样后对图像进行事后修改的方法不同,树环水印$^{\mathrm{[14]}}$(见图6.4)会微妙地影响整个采样过程,从而产生人类看不见的模型指纹。水印将一个模式嵌入到用于采样的初始噪声向量中。这些模式是在傅里叶空间中构造的,因此它们对卷积、裁剪、膨胀、翻转和旋转是不变的。在图像生成后,通过反扩散过程提取噪声向量来检测水印信号,然后对嵌入的信号进行检查。
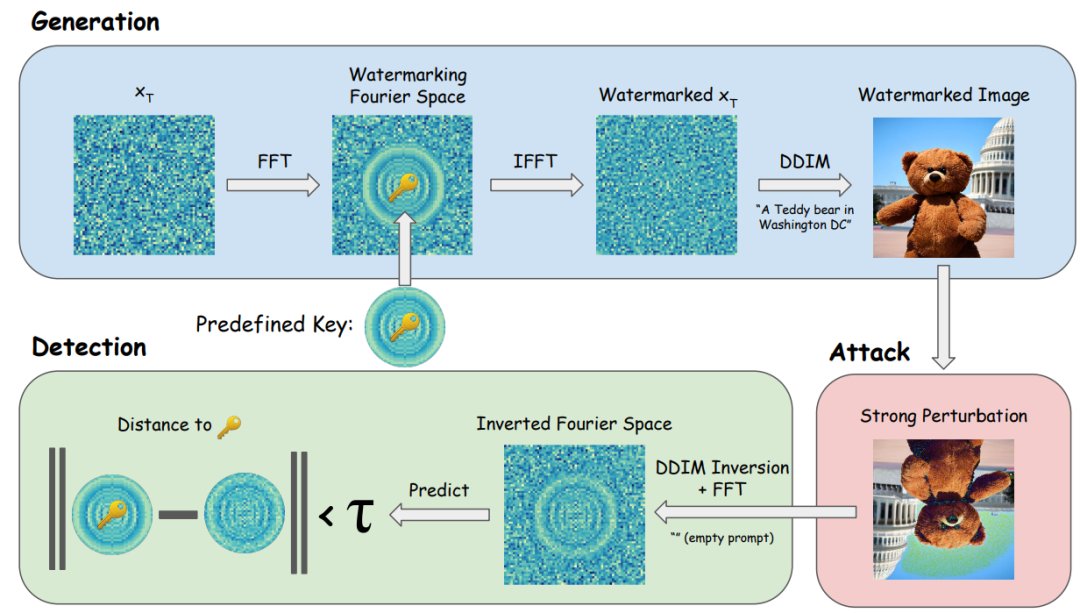
由于直接将密钥输入高斯阵列可能会在生成的图像中产生明显的图案,该方法将密钥输入起始噪声矢量的傅立叶变换中。首先选择一个二元掩码,并对密钥进行采样,则初始化噪声矢量可以在傅里叶空间描述为:
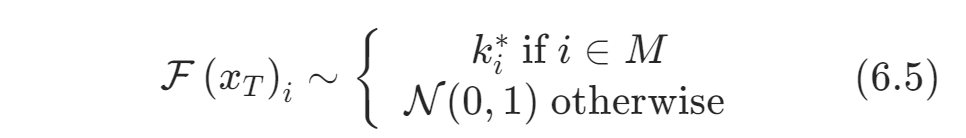
在检测时,给定图像$x_{\mathrm{0}}^{‘}$,模型所有者可以通过DDIM反演过程得到一个近似的初始噪声向量$x_{\mathrm{T}}^{\prime}: x_{\mathrm{T}}^{\prime}=D_{\theta}^{\prime}(x_{0}^{\prime})$,最后的度量计算为在水印区域的傅里叶空间中噪声矢量与密钥之间的距离,即:
$$
d_{\text {detection distance }}=\frac{1}{|M|} \sum_{i \in M}\left|k_{i}^{*}-\mathcal{F}\left(x_{T}^{\prime}\right)_{i}\right| \quad \quad (6.6)
$$
如果该值低于预设阈值,则检测到水印。
对于树环密钥的构造,该方法选择傅里叶空间中以低频模式为圆心,以为半径的圆形区域作为密钥区域。密钥在统计上应与高斯噪声相似,以避免非高斯密钥可能会导致的分布偏移,从而影响扩散模型的性能。
6.3.2 针对Stable Diffusion的高效水印算法Stable Signature
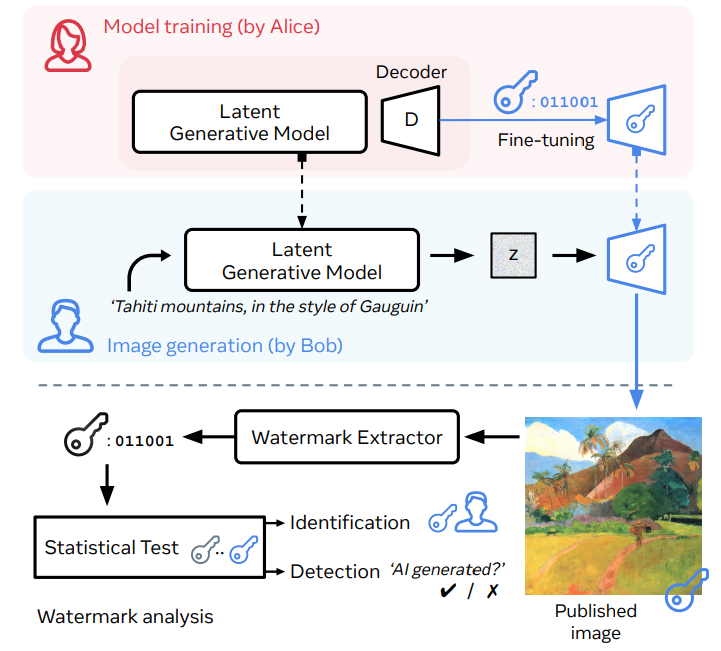
Stable Signature算法$^{\mathrm{[15]}}$提出了一种主动防御策略。图6.5的红色部分是模型发布者Alice,蓝色部分是用户Bob。可以看到,仅仅通过微调LDM的VAE解码器,即可在生成图像中高效嵌入特定的二进制签名,同时保证生成图像的质量。预训练好的水印提取器恢复图像中隐藏的水印,通过一个统计测试可以用于检测和溯源,根据实际假阳率的要求来控制检测的阈值。
检测场景:假设给某位用户Bob的模型签名时一个位的二进制序列,如果Alice利用水印提取器解码的签名和原来的有位以上匹配,则认为这张图片是Alice模型生成的。这里给出两个假设,备择假设说图片是Alice模型生成的,原假设说不是。如果不是Alice模型生成的,可以认为其解码的签名每一位都是独立同分布的Bernoul1i随机变量,这样匹配位数服从二项分布。可以推导出假阳率FPR的计算公式为在条件下匹配位数大于阈值的概率,也就是二项分布的累计分布函数。FPR可以使用不完全beta函数写出闭式解。
溯源场景:假设位用户Bob的模型有不同的嵌入签名,需要进行次检测的假设检验,如果全部拒绝,那么图片不是由他们任何人生成的,否则把图片归属为匹配位数最多的用户。次测试的假阳性更多,所以全局FPR更高,在真实场景一般是给定要求的FPR,反过来确定阈值。
Stable Signature的训练分为两个阶段。第一阶段是预训练一个水印提取网络。首先使用经典水印算法HiDDeN模型编码一张图片和位二进制消息,经过常规的图像变换,然后解码出消息。由于在后续嵌入水印的微调过程中不需要水印编码器,在这个阶段只需要优化消息重构损失,不需要优化原有的感知损失和对抗网络。此外,由于一般图像的解码消息比特间相互关联且高度有偏,违背了前面的独立同分布假设,还需要通过一个PCA白化变换来去偏和去相关。
第二阶段是对给定的签名,微调LDM的VAE解码器。在这个阶段,水印提取器是冻结的,并且同上个阶段一样优化消息重构损失。为了保持图像的生成质量,在这个阶段还需要使用一个Watson-VGG感知损失来控制解码器与原解码器输出图像的失真程度,该方法使用平衡系数来平衡两部分损失。这一阶段的微调过程非常高效,训练小于500张图片只需要单卡1分钟的时间。该方法在LDM等多种生成模型上和DwtDct、SSL Watermark和HiDDeN等多种基线水印方法进行了比较,结果表明该方法的鲁棒性和不可见性与基线方法是可比的。
6.4 图像数字水印常见攻击
水印攻击方法可以分为4类:健壮性攻击、表达攻击、解释攻击和合法攻击。其中前3类可归类为技术攻击,而合法攻击则完全不同,它是在水印方案所提供的技术特点或科学证据的范围之外进行的。在此,仅论述常见的前3类技术攻击方法和一些基本对策。
6.4.1 健壮性攻击
健壮性攻击以减少或消除数字水印的存在为目的,包括像素值失真攻击、敏感性分析攻击和梯度下降攻击等。这些方法并不能将水印完全除去,但可能充分损坏水印信息。为抵抗这类攻击,总体要求水印算法是公开的,算法的安全性应依赖于与图像内容有关或无关的密钥及算法本身的特性。
(1)像素值失真攻击
像素值失真攻击是指对图像像素值的修改,可以分为信号处理攻击和分析攻击两种方法$^{\mathrm{[16]}}$。
信号处理攻击是通过对水印图像进行某种操作,以削弱或删除嵌入的水印,而不是试图识别或分离水印,这种攻击包括线性或非线性滤波、像压缩、添加噪声、图像量化、模数或数模转换等,造成像素值失真的4种基本攻击操作是:外加噪声、幅值变化、线性滤波和量化;其他的攻击操作可看作这4种基本方式的有机组合$^{\mathrm{[17]}}$。在这4种基本攻击操作中,线性相关检测对外加噪声以及归一化相关检测对幅值变化都是健壮的,而变阈值的优化检测方法对线性滤波和量化处理比相关检测具有更好的健壮性。
分析攻击是通过分析水印图像来估计图像中的水印,然后将水印从图像中分离出来并使水印检测失败。常见的例子是合谋攻击,它有两种基本类型:其一是攻击者拥有同一个原图像嵌入了不同水印的拷贝,通过取所有拷贝的均值或仅从每个拷贝中取一小部分,可得到一个检测不到水印的原图像的近似值$^{\mathrm{[18]}}$。其二是攻击者拥有嵌入了同一个水印的不同水印图像,对这些图像取均值并以这个均值作为嵌入水印的估计值,然后从水印图像中将这个估计值减去$^{\mathrm{[19]}}$。它的一种变形是同一个水印重复嵌入一个数据的几个位置,再将这几个位置看作独立的而实施上述合谋攻击,从而估计出嵌入的水印$^{\mathrm{[20]}}$。一个攻击者拥有大约10个不同的拷贝就能成功地将水印除去$^{\mathrm{[21]}}$。
(2)敏感性攻击
水印敏感性分析攻击的基本思想$^{\mathrm{[22]}}$是:使用相关水印检测器寻找从水印检测区域到区域边缘的捷径,而该捷径可由检测区域表面的法线近似表示,并且该法线在检测区域的绝大部分是相对恒定的。
水印敏感性分析攻击的成功,依赖于检测区域边界的法线可用于寻找越出检测区域的捷径。如果检测区域边界的曲率使在每一点的法线仅提供关于该捷径方向的极少信息,则敏感性分析攻击在计算上是不可行的。因此构造具有这种性质的水印检测区域是一个需要关注的问题。
6.4.2 表达攻击
表达攻击是让图像水印变形而使水印存在性检测失败。与健壮性攻击相反,表达攻击实际上并不除去嵌入的水印,而试图使水印检测器与其纳入的信息不同步。
(1)置乱攻击
置乱攻击$^{\mathrm{[17]}}$是指在将水印图像提交水印检测器之前,先对图像的像素值进行置乱,通过水印检测器之后再进行逆置乱。这种置乱可以是像素值简单的行(或列)的置换,也可以是比较复杂的随机置乱。置乱程度与使用的检测策略有关。最著名的置乱攻击是马赛克攻击$^{\mathrm{[23]}}$,它将嵌入了水印的图像分割成许多检测不到水印的小方块,这些小方块再Web页上按相应的HTML标记重新组装起来,但由于这些块太小而无法容纳水印数据,所以无法发现水印。
(2)同步攻击
许多水印技术对同步性非常敏感,要求在检测水印之前,嵌入了水印的图像必须正确对齐。攻击者可在保真度的约束下,通过对图像的几何变形来干扰这种同步性,使得水印虽然存在但却检测不出来。引起失同步的这些几何变形可以是简单的平移、旋转、缩放,或较复杂的图像剪切、水平翻转、行(或列)删除,以及随机几何变形(如直方图拉伸、均衡、非线性扭曲等),甚至是某些几何变形的组合。
6.4.3 解释攻击
在一些水印方案中可能存在对检测出的水印具有多种解释。解释攻击包括拷贝攻击、可逆攻击等,它使数字水印的版权保护受到了挑战。
(1)拷贝攻击
拷贝攻击$^{\mathrm{[24]}}$是从嵌入水印的图像中估计出水印并拷贝到目标图像的其他图像中。拷贝的水印要自适应于目标图像,以保证其不可察觉性。使用拷贝攻击在目标图像中生成一个有效的水印,这既不需要算法知识又不需要水印密钥知识。拷贝攻击分为3步进行:
- 找出图像中水印的估计值;
- 处理该估计值,使得水印能量最大化并满足不可感知性要求;
- 将处理后的水印估计值嵌入目标图像得到伪造的水印图像。
(2)可逆攻击
可逆攻击$^{\mathrm{[25]}}$基于大多数水印方案的嵌入算法是可逆的和多数水印嵌入是健壮的这一事实,攻击者将水印嵌入过程逆过来使用即可。可逆攻击对盲水印系统同样适用,可通过建立一个类似噪声但与发布的图像具有很高相关性的伪造水印实施攻击,这样的水印可通过提取和改变发布图像的某些特征来构造。攻击者从发布的图像中减去伪造的水印便可建立一个伪造的原图像,从而使水印检测陷入死锁,造成图像所有权的模糊性。
从以上分析可以看出,健壮性攻击将对水印造成实质性的损害,遭受这类攻击的水印是难以检测或恢复的;表达攻击是水印方案面临的公开问题,目前仍然缺乏有效的对抗策略,只能通过预见可能遇到的具体攻击方法进行预防,由于它不影响水印的存在性,使用更先进的检测器可能检测到攻击过的水印;解释攻击破坏了水印应用的基础,攻击的是水印必须具有的唯一性解释,但在采取相应的措施后这种攻击是难以实施的。
7 针对音频的数字水印生成和攻击
近年来,数字多媒体技术及互联网技术的迅猛发展使得图像、视频和音频等多种形式的多媒体数字作品的创作、存储和传输都变得极其便利。以MP3为代表的网络音乐在互联网上广泛传播就是得益于数字音频压缩技术的成熟。但是,Internet上肆无忌惮的复制和传播盗版音乐制品,使得艺术作品的作者和发行者的利益受到极大损害。在这种背景下,能够有效地实行版权保护的数字水印技术应运而生。数字音频水印系统的框架如图7.1所示。
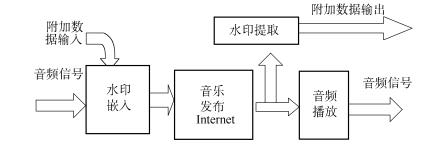
数字音频水印技术就是在不影响原始音频质量的条件下向其中嵌入具有特定意义且易于提取的信息的过程。根据应用目的不同,被嵌入的信息可以是版权标识符、作品序列号、文字(如艺术家和歌曲的名字),甚至是一小段音频等。水印与原始音频数据紧密结合并隐藏在其中,通常是不可听到的,而且能够抵抗一般音频信号处理和盗版者的某些恶意攻击。
7.1 传统音频数字水印生成方法
传统音频水印方法的特点是水印嵌入设计极度依赖经验规则与专家知识。然而,对于各类音频想同时满足高不可感知性、高容量、高鲁棒性是极为困难的任务。因此目前开源可用的音频水印工具屈指可数。
7.1.1 最低有效位替代法
最低比特位替代法(Least Significant Bits,LSB)是音频信息隐藏中应用最广泛,实现最简单的算法之一。时域上的LSB是把每个采样点的最低比特,也可能是最低几位,用秘密信息的数据比特来替代,提取时只要把相应的最低位取出来,就可以恢复嵌入的秘密信息数据流$^{\mathrm{[26]}}$。
LSB方法的优点是水印嵌入和提取算法简单,速度快,能够满足实时性的要求;音频信号里可编码的数据量大。但是缺点也是显而易见的,嵌入后的音频信号易于被篡改,隐藏信息容易被信道噪声、重采样、A/D、D/A等变换破坏,所以鲁棒性差;另外,隐藏数据量大带来的问题是人耳可能会察觉这些隐藏信息产生的噪声,尤其在这种噪声的加载是均匀的时候$^{\mathrm{[27]}}$。
一些学者进行深入研究,也提出了许多改进方案。如为了提高传统LSB方法的健壮性,Nedeljko等人提出将秘密信息嵌入载体信息LSB的高位(第4位以上),同时修改载体信息的低位,以减少因嵌入带来的嵌入误差$^{\mathrm{[28]}}$。Nedeljko的LSB方法比传统的LSB方法在健壮性方面有了较大的提高,但是这种提高是建立在降低感知透明性(不可感知性)的基础上的$^{\mathrm{[29]}}$。为了改善这一点可以在嵌入过程中根据音频的能量进行数据嵌入位的自适应选择$^{\mathrm{[30]}}$,当然,这种方法对平均能量比较高的音频样本更有效。
7.1.2 回声隐藏方法
回声(Echo)算法最初由Gruhl等人于1996年提出,是通过在时间域向音频信号s(t)引入回声αs(t-△t)来将秘密数据嵌入到音频载体数据中:α为衰减率,△t为延迟时间,其选取以人耳无法分辨为准则。通过改变回声信号的延迟时间来对水印信号进行编码,即可选两个不同的延迟时间来分别代表“0”和“1”。根据人耳的听觉心理模型可知,时延的长短是有限制的,一般的取值范围为0.5~2ms之间。太小会影响嵌入信息的提取,太大就会产生感觉得到的回声。同时,回声的幅度系数α也需要精心挑选,它与时延的取值及传输环境有关,一般的范围是0.6~0.9之间,太小会影响嵌入信息提取的准确性,太大会破坏不可感知性。回声算法的提取比嵌入要复杂些,其关键的是回声时延的测定。由于嵌有秘密信息的信号是载体信号与回声信号的卷积,所以可以利用语音信号处理中的同态处理技术,用倒谱自相关测定回声间距。在进行提取前必须知道数据的起点、帧的长度、回声核的时延长度等参数$^{\mathrm{[26]}}$。
回声隐藏方法是利用人类听觉系统中的后屏蔽效应,载体数据和经过回声隐藏的隐秘数据对于人耳来说,前者就像是从耳机里听到的声音,没有回声。而后者就像是从扬声器里听到的声音,由所处空间如墙壁、家具等物体产生的回声。因此,回声隐藏与其他方法不同,它不是将密码数据当作随机噪声嵌入到载体数据中,而是作为载体数据的环境条件,因此对一些有损压缩的算法具有一定的鲁棒性$^{\mathrm{[26]}}$。
7.1.3 相位编码方法
Bender W等人于1996年提出的音频相位编码(Phase Coding)方法,充分利用人耳对绝对相位不敏感性及对相对相位敏感的特性。Bender W等人提出的相位编码的步骤大致是:首先对宿主音频信号进行分段;再对每段进行DFT变换,得到该段的幅值和相位;保存相邻段之间的相位差△φ;将隐藏的二进制比特序列进行相角变换:0→φ0 =π/2,1→φ1 = -π/2,并代替原宿主信号第一段的相位值;根据第一段和前述保存的相邻段之间的相位差△φ决定之后各段的相位值;利用各段隐藏信息后的相位值和未改变的幅值进行傅里叶反变换(IDFT);将反变换后的各段合并。水印提取时则须知嵌入隐藏信息时的分段长度、DFT变换点数和数据间隔。这种做法的结果使相邻频率分量的相对相位关系与原始音频信号的相对相位关系有较大的差别,从而带来音频变形$^{\mathrm{[27]}}$。
Ciloglu T将音频信号通过无限脉冲响应(IIR)的全通滤波器,从而将水印信息嵌入到原始音频信号的相位上,无限脉冲响应的全通滤波器通常具有较复杂的相位特性,所以使用这种方法嵌入的水印一般具有较差的不可感知性$^{\mathrm{[31]}}$。
7.1.4 量化索引调制
量化索引调制(Quantization Index Modulation,QIM)的大致思想是:将隐藏信号的可能值看成是量化索引,如二进制隐藏信号0、1对应的量化索引值为1、2,其他依次类推。每一个索引值对应不同的量化器,对宿主信号进行量化。具体隐藏及提取的方法大致为:首先将宿主音频信号进行分段,每一段欲隐藏一个值的隐藏信号。用欲隐藏的这个隐藏值对应索引的量化器量化宿主信号,即得隐藏信息控制后的该段信号。依次对每段宿主信号做相应量化即可实现信息隐藏。采用QIM音频隐藏方法可实现盲提取。提取方应知道分段方法,首先按隐藏方同样的方法分段,然后对该段欲提取信号,按各种可能的索引对应的量化器进行量化;比较各种量化结果与实际欲提取信号的差异,取最小的一种索引值,其对应的隐藏值即判为该段嵌入的隐藏信号值。对各段依次进行提取,即得所有隐藏信号的序列$^{\mathrm{[27]}}$。
对基于量化调制的数字音频水印嵌入方案来说,量化步长的选取至关重要。因为量化步长与水印嵌入强度密切相关,量化步长取值越大,数字水印鲁棒性能越好(但同时也更容易给音频引入失真)。选取确定量化步长应充分考虑数字音频自身特点和人类视觉掩蔽特性。现有量化调制音频水印嵌入方案普遍采用了均匀量化策略,即对整个数字音频采用一个相同的量化步长*,*而且量化步长必须结合大量实验得到。不同的载体音频信号,只有采纳不同的量化步长值才能各自达到比较好的隐藏效果$^{\mathrm{[32]}}$。文献[32]引入模糊聚类分析理论,提出了一种自适应量化小波域数字音频盲水印算法。该算法能够结合数字音频局部特征,利用模糊聚类分析自适应确定量化步长,并在小波域内将水印信号嵌入到音频数据段的低频分量中。
7.2 深度学习音频水印生成方法
神经网络音频水印方法的特点在于能够自动学习水印嵌入、提取方式,极大降低了水印方法的设计难度。如图7.2所示,基于神经网络的水印模型遵循Encoder-Decoder结构,音频与要嵌入的比特信息一块输入到Encoder,由Encoder产生水印音频,随后Decoder利用水印音频解码信息内容,整个模型以端到端的方式进行训练,自动学习水印嵌入与提取。

为使得音频水印具备鲁棒性,可以在Encoder之后进一步添加一个“攻击模拟层”(Attack Layer),对水印音频施加攻击处理(比如MP3压缩、高斯噪声),从而使得模型学习出对特定攻击鲁棒的嵌入方式。
这种Encoder-Attack Layer-Decoder的结构由Jiren等人$^{\mathrm{[33]}}$于2018年提出,流行于图像水印领域。目前音频水印领域还处在起步阶段,主要有三篇代表性的文章:Robust-DNN$^{\mathrm{[34]}}$、DeAR$^{\mathrm{[35]}}$和WavMark$^{\mathrm{[36]}}$。这些论文的意义是递进的:Robust-DNN、完成了神经网络音频水印的可行性验证;DeAR提高了嵌入容量并、扩充了攻击类型;而WavMark进一步提高了不可感知性、并解决了水印解码时的定位问题,使得神经网络音频水印能够被真正应用于现实环境。
7.2.1 Robust-DNN
最早的基于神经网络的音频水印是2022年的Roubst-DNN$^{\mathrm{[34]}}$。这篇文章遵循Encoder-Attack Layer-Decoder的基本结构,在STFT频域执行嵌入、实现对三种攻击类型的鲁棒性(Dropout、随机噪声、高通滤波),达到了较低的嵌入容量(1.25bps)在Encoder选取上,模型使用了基于U-Net的结构。
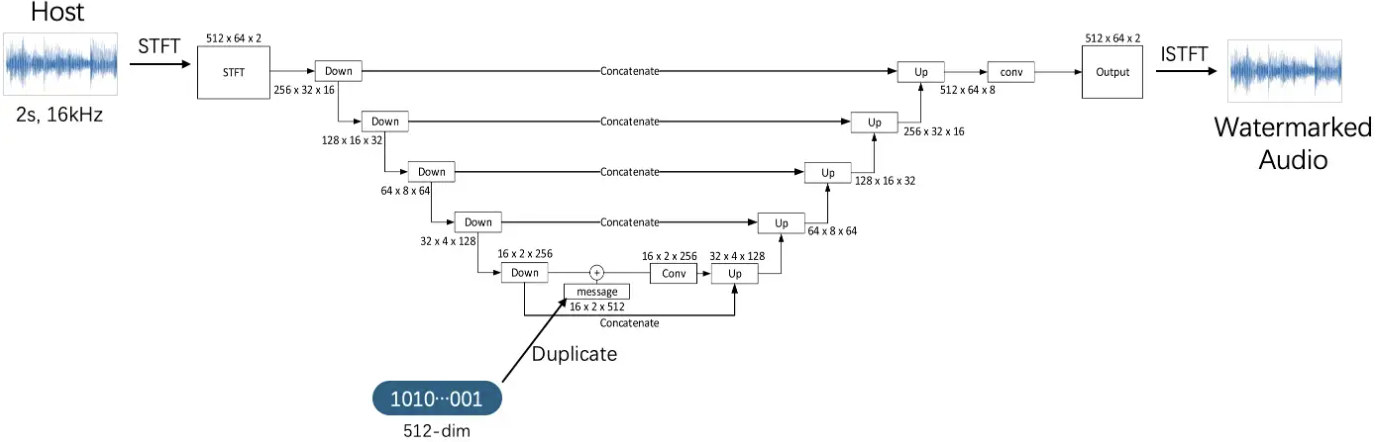
输入长度为2秒、16kHz采样率的宿主音频,通过短时傅里叶变换(STFT)转变为特征图。特征图经过U-Net下采样后与512维的比特信息向量进行相加操作(element-wise),随后执行上采样得到水印音频表示。
7.2.2 DeAR
DeAR$^{\mathrm{[35]}}$同样是在频域执行嵌入,相较Robust-DNN将抵抗的攻击类型扩充到9种,并实现了更高的嵌入容量(9bps)。此外,它在结构上的特点是Encoder所产生的内容不是水印音频,而是残差(Residual),将残差乘以系数与宿主音频相加后得到水印音频。
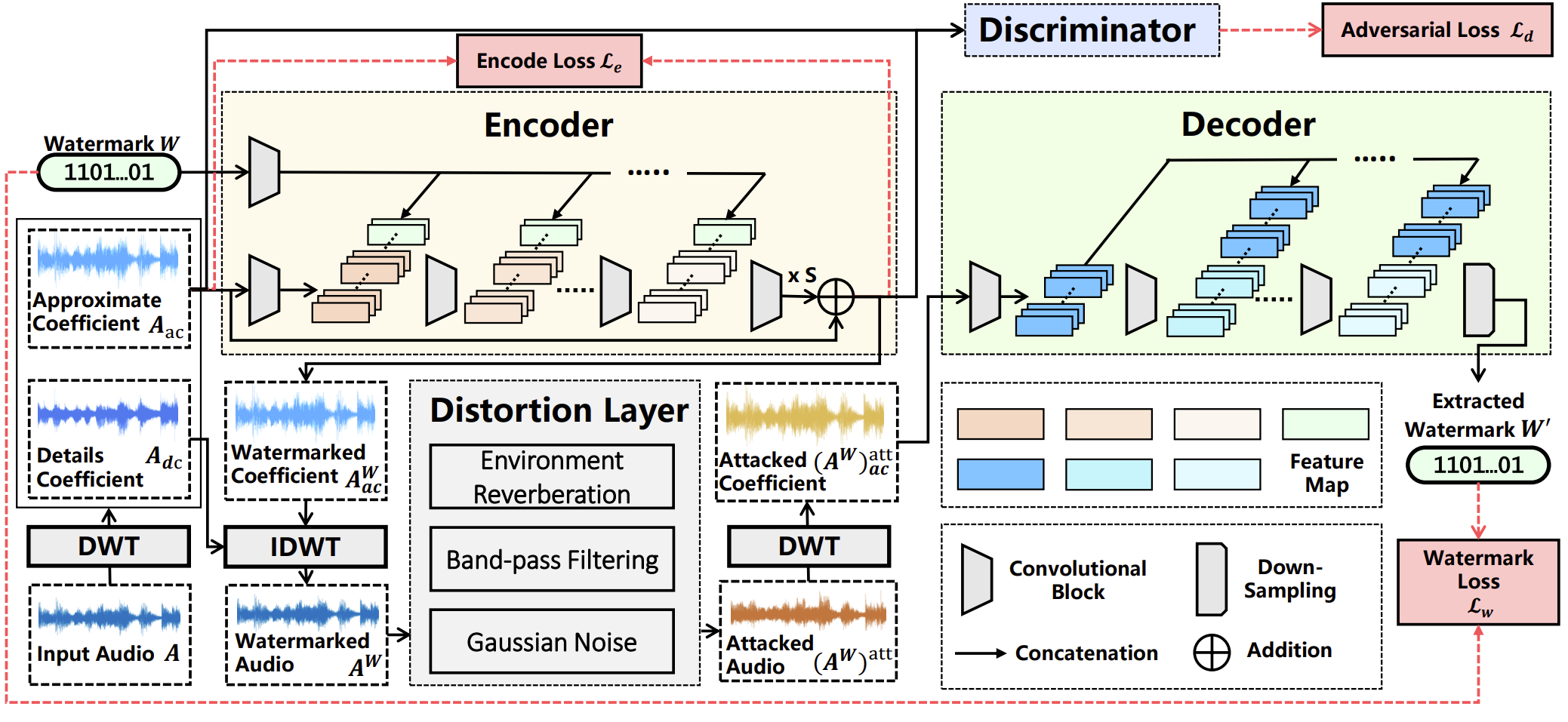
直观来看,这种结构的优点是在使用时可以通过调整系数来控制加水印力度,从而在鲁棒性与不可感知性之间进行折中。但是仔细想想就会发现,这种优点并非此类学习残差的结构所独有,因为“水印音频 - 原始音频 = 残差”。所以对于Robust-DNN这类直接生成水印音频的模型,可以先得到水印音频,然后减去原始音频得到残差,进而实现定量调整。
在具体的嵌入设计上,DeAR使用了离散小波变换(Discrete Wavelet Transform, DWT),依靠1D-CNN修改低频小波系数实现嵌入。宿主音频长度为11秒,44.1kHz采样率;嵌入bit信息为100维度,因此嵌入容量为8.8bps。此外,DeAR将“音频转录”视为三种基本攻击的叠加(高斯噪声、带通滤波、环境混响),通过引入相应的攻击模拟层,从而实现了对转录攻击的鲁棒性。
7.2.3 WavMark
之前两种基于神经网络的水印模型虽然实现了音频的嵌入与提取,但是离实际应用还存在一些距离,因为1)水印音频质量不高,人耳可以听得到噪声;2)实验环境过于理想,没有考虑水印在解码时的“定位问题”;3)嵌入容量有待进一步提升(< 10bps)。微软亚洲研究院提出了WavMark$^{\mathrm{[36]}}$,使得神经网络音频水印被真正地应用于现实环境。
整体而言,WavMark实现了32bps的嵌入容量、对10种常见攻击类型的鲁棒性,并保持了良好的不可感知性(SNR > 36dB,PESQ > 4.0)。
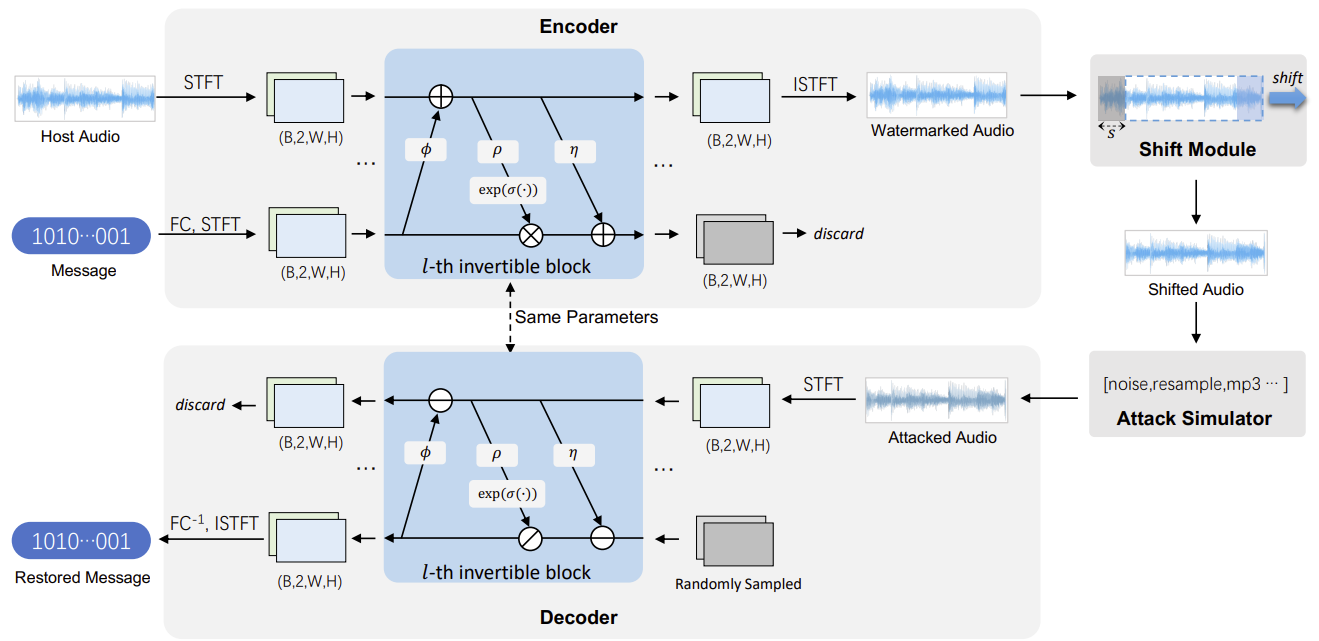
WavMark提高水印音频质量与嵌入容量的关键点在于它使用了基于“可逆神经网络”(Invertible Neural Network)的Encoder与Decoder。“可逆神经网络”最早提出于2014年(Nice:Non-linear independent components estimation,2014),其特点是网络运算是完全可逆的。如果将普通神经网络的运算过程记为$y= f(x)$,则可逆网络同时支持将结果“逆向输入”,由 $y$ 得到 $x:x = f^{\mathrm{−1}}(y)$。这种可逆的特点使得可逆网络在水印嵌入、解码任务上能获得更好的表现。为解释这一点,可以重新审视音频水印模型的基本结构——宿主音频与水印信息经过Encoder后得到水印音频,随后Decoder进行消息解码。
7.3 音频数字水印常见攻击
对数字音频水印技术进行的攻击通常有滤波、重采样、重量化、剪切、加噪声、时间缩放、变调、混频和有损压缩等,此外还有针对某种水印技术专门设计的攻击以及协议层的解释攻击$^{\mathrm{[37]}}$,而且已经出现了顽健性标准测试工具Stirmark for Audio$^{\mathrm{[38]}}$。
根据对音频信号同步结构的影响一般把攻击分为两类:
类型一:MPEG压缩、低通/带通滤波、加性/乘性噪声、加入回声和重采样/重量化。这种类型的攻击不显著影响音频信号的同步结构。
类型二:抖动攻击(jittering)、时间尺度变形(time-scale warping)、变调(pitch-shift warping)以及上下采样(up/down sampling)。这种类型的攻击会损坏音频信号的同步结构,比第一种类型的攻击更具挑战性。
同步问题对任何数据隐藏技术都是一个严重的问题,尤其是对一维的音频信号。剪切掉不想要的音频片段或随机向音频数据中添加和删除样本,都会引起这个问题。扩频技术中采用的相关检测器依赖于待检测信号和水印信号之间精确的对齐,同步错误会对检测性能产生严重的影响$^{\mathrm{[39]}}$。大多数的音频水印算法都是基于位置的,即水印嵌入到特定位置再从该位置检测,而同步攻击引起的位移将会使水印检测不在嵌入位置上进行,这就需要在检测前恢复同步。
8 针对视频的数字水印生成和攻击
随着互联网和视频编码技术的飞速发展,尤其是一些新的视频编码标准如H.264/AVC的普及,视频应用早已成为大众生活中的一部分,但技术的不断更新换代也带来了一些严重的问题。如今,高带宽的网络服务使数字媒体内容的分发、复制、编辑变得愈发容易,同时也使得盗版行为越来越猖獗。屡禁不止的盗版行为严重损害了影视行业、视频所有者的利益,对视频等数字多媒体数据的版权保护迫在眉睫。
视频数字水印作为一种可以起到版权保护作用的技术,已经被大范围应用。与传统的数字图像水印技术类似,视频水印技术也是将特定的信息如视频所有者的logo嵌入视频,从而起到保护视频所有权的目的。
8.1 基于非压缩域的视频水印方案
非压缩域的视频水印方案处理的对象是原始的、未经压缩的视频数据。这类方案一般需要先对压缩后的视频进行解码,然后嵌入水印,最后进行重压缩,所以计算量较大。由于原始的视频数据就是由一系列的图像组成的,早期一些学者提出可以直接将静态图像的数字水印方案应用在视频中。与图像水印的处理思路类似,对于视频信号,可以直接在空间域(像素域)对原始视频数据进行处理,如可以直接对每帧图像的像素值进行操作,也可以将原始视频数据变换到变换域,再进行水印嵌入。常见的变换操作有DCT变换、DWT变换和DHT变换等。其中,对DCT域的水印方案讨论最为广泛。
8.1.1 空间域水印方案
早期的一些方案$^{\mathrm{[40-43]}}$都借鉴了扩频通信的思想。Hartung$^{\mathrm{[41]}}$针对MPEG-2视频数据,提出了面向非压缩视频和压缩视频的两套数字水印方案。扩频通信的目的是通过一个宽带信号来传输窄带信号,可以利用这种思想让视频数据携带水印信号。通常来说,一个视频信号被看成是三维的,而文中将原始视频信号扫描成一个一维信号,扫描方式为从左到右,从上到下,从前到后。先将要嵌入的水印比特序列乘以一个因子来获得扩展序列。然后,将扩展的序列乘以一个局部可调振幅因子,并用一个二进制伪噪声信号对信号序列进行调制,最终完成扩频。在此基础上将扩频的水印信号叠加到一维视频信号上。由于经过以上处理的水印信号和伪噪声信号相似,所以水印信息很难被检测、定位以及篡改。
8.1.2 频率域水印方案
Cox$^{\mathrm{[18]}}$提出将水印构造为独立的且分布均匀的高斯随机矢量,以不易察觉的方式将它们以类似于扩展频谱的方式插入到数据中视觉感知最为明显的频谱分量中。在这种情况下插入水印会使水印对信号处理操作(如有损压缩、滤波、模数转换、重新量化等)以及常见的几何变换(如裁剪、缩放、平移和旋转)具有较好的鲁棒性。
Zhu$^{\mathrm{[44]}}$将具有高斯分布特征的水印嵌入所有的高通小波系数,这样可以允许不同解析度下的小波域水印信息的检测。
8.2 基于压缩域的视频水印方案
由于在实际应用中,视频数据基本上都是以压缩的形式进行存储和传输的,所以在此背景下,如果还是针对原始的视频信号进行水印嵌入,则首先需要进行压缩视频码流的解码,然后嵌入水印,最后重新进行压缩编码,所以计算量很大。因此,应用基于压缩视频的数字水印方案是很有必要的。由于嵌入水印信息的压缩视频将来会被解码,所以这一类方案的基本要求是在解码后,水印信息仍然存在于视频中,并且可以被正确提取出来。
基于压缩视频的数字水印方案根据处理阶段的不同可以分为两类:第一类是在压缩视频的过程中嵌入数字水印;第二类是直接在压缩后的视频码流中嵌入数字水印(或者只进行部分解码来嵌入水印)。
8.2.1 编码过程中的水印方案
这类方案是在视频的编码过程中进行水印嵌入操作,从已有的方案来看,主要还是把水印嵌入DCT系数或者运动矢量中。在视频的编码过程中视频序列中只有少部分帧(如I帧)使用的是帧内预测,而大部分帧(如B帧和P帧)使用的是帧间预测。由于在帧间预测的编码过程中需要使用运动估计来预测当前帧,此过程中会产生大量的运动矢量,因此将水印信息嵌入运动矢量中也是一类讨论较为广泛的方案。
Song$^{\mathrm{[45]}}$针对AVS编码的视频,提出可以通过修改不同宏块的运动矢量分辨率来实现水印的嵌入,修改规则是基于运动矢量分辨率和水印之间的映射规则。
Qiu$^{\mathrm{[46]}}$等在H.264/AVC编码过程中将鲁棒水印和脆弱水印一起嵌入视频,通过更改一组选定的运动矢量的分量,将脆弱水印嵌入运动矢量,通过改变I帧中量化的AC系数将鲁棒水印嵌入DCT域。该方案可以同时满足版权保护和篡改认证的需求。
Zhang$^{\mathrm{[47]}}$提出首先对水印信息进行预处理,并对灰度水印模式进行处理,然后将其嵌入运动矢量。
8.2.2 基于压缩视频码流的水印方案
Hartung$^{\mathrm{[41]}}$同样使用上文提到的扩频通信的方法来产生和伪噪声信号类似的伪随机水印信号,然后将水印信号排列成和视频帧具有相同维度的信号,接着对该水印信号进行8×8的DCT变换,然后将变换后的信号和码流中8×8的DCT系数相加完成嵌入。此方案面临的主要问题是:加入水印可能会导致霍夫曼码的增长,从而引起码流长度增加;在视频编码过程中,如果参考帧发生变化,则其可能会在时间上和空间上传播开来,而加入水印即会造成帧的变化,引起差错传播。因此,作者提出需要额外添加一个偏移补偿信号来补偿前一帧的水印信号来避免此问题。
8.3 视频数字水印常见攻击
按照对水印化视频流的操作目的不同,对水印的攻击可以分为无意的攻击和有意的攻击。
无意的攻击
无意攻击采用各种压缩编码标准(如MPEG-1、MPEG-2和MPEG-4等)对视频进行压缩编码;在NTSC、PAL、SECAM和通常的电影标准格式之间转换时所带来的帧速率和显示分辨率的改变,以及屏幕高宽比的改变(如4∶3,16∶9,2.11∶1);帧删除、帧插入、帧重组等视频编辑处理;数/模和模/数转换,在转换中给视频可能带来的影响包括低通滤波、添加噪声、对比度轻微改变以及轻微的几何失真等。
8.3.2 有意的攻击
Hartung等$^{\mathrm{[48]}}$将水印攻击分为4类:简单攻击、检测失效攻击、混淆攻击和移去水印攻击。Voloshynovskiy等$^{\mathrm{[49]}}$提出的分类方法,也把水印攻击分为4类:移去水印的攻击、几何攻击、密码攻击和协议攻击。对于单个视频帧,针对静态图像的攻击一般来说仍然有效;对于连续视频帧,除了帧删除、帧插入、帧重组等攻击之外,还有统计平均攻击和统计共谋攻击两种攻击方法。平均攻击是对局部连续的帧求平均,以消除水印平均攻击方法对于在各帧中嵌入随机的、统计独立的水印算法比较有效。统计共谋攻击方法是先从单个的帧中估计出水印,并在不同的场景中求平均以取得较好的精确度;然后从每帧中减去估计的水印。这种攻击对于在所有帧中嵌入相同的水印的方案比较有效。
9 展望与未来的挑战
随着AIGC时代的发展,数字媒体安全领域对于可证安全的需求日益突出。未来的发展趋势之一是在可证安全隐写技术的基础上研究和设计可证性能无损水印技术,即在保持图像质量不受影响的情况下,实现水印的可靠提取和验证,为数字内容的真实性和完整性提供更强的保障。考虑到水印技术的不断进步,嵌入方式逐渐朝向更为隐蔽和智能化的方向发展。
此外,传统数字水印和深度学习水印技术结合的多重水印技术可能能够克服传统水印算法在面对复杂攻击时的局限性。融合传统水印的泛化性和深度水印的针对性,可以满足不同应用场景下的需求。这种技术的发展可能是数字媒体安全领域未来的一个重要方向,为数字内容的保护提供更为可靠和多元化的解决方案。
随着视频水印技术的发展,新的攻击算法也在不断地提出,对水印的鲁棒性构成了很大的挑战。有关水印算法的复杂度、水印的鲁棒性和不可感知性、水印的随机检测等关键技术和问题亟待研究和解决。
10 参考文献
- Pevný T, Filler T, Bas P. Using high-dimensional image models to perform highly undetectable steganography. International Workshop on Information Hiding. Springer, Berlin, Heidelberg, 2010: 161-177.
- Holub V, Fridrich J. Designing steganographic distortion using directional filters. 2012 IEEE International workshop on information forensics and security (WIFS). IEEE, 2012: 234-239.
- Holub V, Fridrich J. Digital image steganography using universal distortion. Proceedings of the first ACM workshop on Information hiding and multimedia security. 2013: 59-68.
- Jindal N, Liu B. Review spam detection. Proceedings of the 16th international conference on World Wide Web. 2007: 1189-1190.
- Fridrich J, Kodovsky J. Rich models for steganalysis of digital images. IEEE Transactions on Information Forensics and Security, 2012, 7(3): 868-882.
- Holub V, Fridrich J. Low-complexity features for JPEG steganalysis using undecimated DCT. IEEE Transactions on Information Forensics and Security, 2014, 10(2): 219-228.
- Xu G, Wu H Z, Shi Y Q. Structural design of convolutional neural networks for steganalysis. IEEE Signal Processing Letters, 2016, 23(5): 708-712.
- Ye J, Ni J, Yi Y. Deep learning hierarchical representations for image steganalysis. IEEE Transactions on Information Forensics and Security, 2017, 12(11): 2545-2557.
- Boroumand M, Chen M, Fridrich J. Deep residual network for steganalysis of digital images[J]. IEEE Transactions on Information Forensics and Security, 2018, 14(5): 1181-1193.
- Zhu J, Kaplan R, Johnson J, et al. Hidden: Hiding data with deep networks[C]// Proceedings of the European conference on computer vision (ECCV). 2018: 657-672.
- Han Fang, Yupeng Qiu, Kejiang Chen, Jiyi Zhang, Weiming Zhang, and Ee-Chien Chang. 2023. Flow-based robust watermarking with invertible noise layer for black-box distortions. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence (AAAI’23/IAAI’23/EAAI’23), Vol. 37. AAAI Press, Article 564, 5054–5061.
- Ma R, Guo M, Hou Y, et al. Towards Blind Watermarking: Combining Invertible and Non-invertible Mechanisms[C]//Proceedings of the 30th ACM International Conference on Multimedia. 2022: 1532-1542.
- Jia Z, Fang H, Zhang W. Mbrs: Enhancing robustness of dnn-based watermarking by mini-batch of real and simulated jpeg compression[C]//Proceedings of the 29th ACM international conference on multimedia. 2021: 41-49.
- Wen Y, Kirchenbauer J, Geiping J, et al. Tree-Ring Watermarks: Fingerprints for Diffusion Images that are Invisible and Robust[J]. arXiv preprint arXiv:2305.20030, 2023.
- Fernandez P, Couairon G, Jégou H, et al. The stable signature: Rooting watermarks in latent diffusion models[J]. arXiv preprint arXiv:2303.15435, 2023.
- 杨义先 ,钮心忻 ,任金强. 信息安全新技术[M]. 北京:北京邮电大学出版社 ,2002. 56259.
- Cox I J, Mill M L, Bloom J A. Digital Watermarking* *[M]. San Francisco: Morgan Kaufmann Publishers, 2001. 2412316.
- Cox I J, Kilian J, Leighton T, et al. Secure spread spectrum watermarking for multimedia [J]. IEEE Trans on Image Processing* *,1997 ,6 (12) :1673-1687.
- Cox I J, Linnartz J M G. Some general methods for tampering with watermarks [J]. IEEE J on Selected A reas in Com m unications ,1998 ,16 (4) :5872593.
- Boeuf J, Stern J P. An analysis of one of the SDMI candidates[A]. Proc of the Fourth Int Workshop on Inf ormation Hiding[C]. Berlin: Springer ,2001. 3682374.
- Voloshynovskiy S, Pereira S, Pun T, et al. Attacks on digital watermarks: Classification, estimation2based attacks and benchmarks[J]. IEEE Communications Magazine, 2001, 39(8) :1182125.
- Kalker T, Linnartz J P, Dijk M V. Watermark estimation through detector analysis[A]. IEEE Int Conf on Image Processing[C]. Los Alamitos ,1998. 4252429.
- Petitcolas F A P, Anderson R, Kuhn M G. Information hiding: A survey[J]. Proc of the IEEE, 1999, 87(7): 106221078.
- Kutter M, Voloshynovskiy S, Herrigel A. The watermark copy attack[A]. Proc of the SPIE[C]. San Jose, 2000. 3712380.
- Craver S, Memon N, Yeo B L, et al. Resolving rightful ownerships with invisible watermarking techniques: Limitations, attacks and implications[J]. IEEE J on Selected Areas in Communications, 1998 ,16 (4) :5732586.
- 汝学民. 音频隐写与分析技术研究[D]. 杭州: 浙江大学, 2006.
- 张歆昱. 基与心理声学模型的音频数据算法研究[D]. 武汉:华中科技大学,2004.
- Nedeljko Cvejic, Tapio Seppanen. Increasing the capacity of LSB-based audio steganography[C]. In: Proceedings of 2002 IEEE Workshop on Multimedia Signal Processing, St Thomas, Virgin Islands, USA, 2002; Virgin Island: IEEE, 2002: 336-338.
- 卢欣, 叶成荫, 吴旭翔. 一种基于能量特征的LSB方法设计[J]. 商场 现代化, 2007, (11):44-45.
- 陈燕辉. 数字水印系统和能量自适应LSB语音数字水印研究[D]. 杭州: 浙江大学, 2003.
- 侯剑, 付永生, 郭恺. 基于相位调制的立体声音频数字水印[J]. 电子技术应用, 2006, (6):49-51.
- 王向阳, 付斌. 基于内容的自适应量化数字音频盲水印算法[J]. 辽宁师范大学学报(自然科学版), 2006,29(1):37-42.
- Jiren Zhu, Russell Kaplan, Justin Johnson, and Li Fei-Fei. 2018. HiDDeN: Hiding Data With Deep Networks. In Computer Vision – ECCV 2018: 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part XV. Springer-Verlag, Berlin, Heidelberg, 682–697.
- PAVLOVIĆ K, KOVAČEVIĆ S, DJUROVIĆ I, et al. Robust speech watermarking by a jointly trained embedder and detector using a DNN[J/OL]. Digital Signal Processing, 2022: 103381.
- Liu, Chang & Zhang, Jie & Fang, Han & Ma, Zehua & Zhang, Weiming & Yu, Nenghai. (2023). DeAR: A Deep-Learning-Based Audio Re-recording Resilient Watermarking. Proceedings of the AAAI Conference on Artificial Intelligence[C]. 37. 13201-13209. 10.1609/aaai.v37i11.26550.
- WavMark: Watermarking for Audio Generation[J]. 2023.
- CRAVER S, MEMON N, YEO B L. Resolving rightful ownerships with invisible watermarking techniques: limitations, attacks and implications[J]. IEEE Journal on Selected Areas in Communications, 1998, 16(4): 573-586.
- STEINEBACH M, PETITCOLAS F A P, RAYNAL F. StirMark benchmark: audio watermarking attacks[A]. Proceedings of the International Conference on Information Technology: Coding and Computing[C]. 2001. 49-54.
- KIROVSKI D, MALVAR H S. Spread spectrum watermarking of audio signals[J]. IEEE Transactions on Signal Processing, 2003, 51(4):1020-1033.
- HARTUNG F,GIROD B. Digital Watermarking of Raw and Compressed Video[C] //Proceedings of SPIE-The International Society for Optical Engineering. 1997,205-213.
- HARTUNG F,GIROD B. Watermarking of Uncompressed and Compressed Video[J]. Signal Processing, 1998, 66(3): 283-301.
- LANCINI R, MAPELLI F, TUBARO S. A Robust Video Watermarking Technique in the Spatial Domain[C]//Zadar: International Symposium on VIPromCom Video/Image Processing and Multimedia Communications, 2002. 251-256.
- TOKAR T, KANOCZ T, LEVICKY D. Digital Watermarking of Uncompressed Video in Spatial Domain[C]// Bratislava: 2009 19th International Conference Radioelektronika,2009. 319-322.
- ZHU WW, XIONG Z X, ZHANG Y Q. Multiresolution Watermarking for Images and Video[J].IEEE Transactions on Circuits and Systems for Video Technology, 1999, 9(4): 545-550.
- SONG X G, SU Y T, LIU Y, et al. A Video Watermarking Scheme for AVS Based on Motion Vectors[C]//Beijing: Proceedings of 2008 11th IEEE International Conference on Communication Technology, 2008. 767-770.
- QIU G, MARZILIANO P, HO A T S, et al. A Hybrid Watermarking Scheme for H. 264/AVC video[C]// Cambridge: Proceedings of the 17th International Conference on Pattern Recognition, 2004. 865-868.
- ZHANG J HO A, QIU G, et al. RobustVideo Watermarking of H. 264/AVC[J]. IEEE Transactions on Circuits and Systems II: Express Briefs, 2007, 54(2): 205-209.
- Hartung F H, Su J K, Girod B∙Spread spectrum watermarking: Malicious attacks and counterattacks[A]. In: Proceedings of SPIE Security and Watermarking of Multimedia Contents, San Jose, 1999. 147-158.
- Voloshynovskiy S, Pereira S, Thierry P, et al. Attacks on digital watermarks: Classification estimation based attacks and benchmarks[J]. IEEE Communications Magazine. 2001, 39(8): 118-126.
 微信
微信 支付宝
支付宝



