
编译原理第8章:语义分析和中间代码生成

1 声明语句的翻译
主要任务:分析所声明$id$的性质、类型和地址,在符号表中为$id$建立一条记录。
1.1 类型表达式
设有C程序片段:
1 | struct stype |
和stype绑定的类型表达式:record((name × array(8, char)) × (score × integer))
和table绑定的类型表达式:array(50, stype)
和p绑定的类型表达式:pointer(stype)
1.2 局部变量的存储分配
对于声明语句,语义分析的主要任务就是收集标识符的类型等属性信息,并为每一个名字分配一个相对地址。
- 从类型表达式可以知道该类型在运行时刻所需的存储单元数量称为类型的宽度$(width)$
- 在编译时刻,可以使用类型的宽度为每一个名字分配一个相对地址
名字的类型和相对地址信息保存在相应的符号表记录中。
2 赋值语句翻译
赋值语句的基本文法:
- $S \rightarrow \mathrm{id}=E$
- $E \rightarrow E_1+E_2$
- $E\rightarrow E_1 * E_2$
- $E \rightarrow-E_{1}$
- $E \rightarrow\left(E_{1}\right)$
- $E \rightarrow id$
赋值语句翻译的主要任务:生成对表达式求值的三地址码


2.1 含有数组引用的赋值语句的翻译
将数组引用翻译成三地址码时要解决的主要问题是确定数组元素的存放地址,也就是数组元素的寻址。

3 控制流语句的翻译
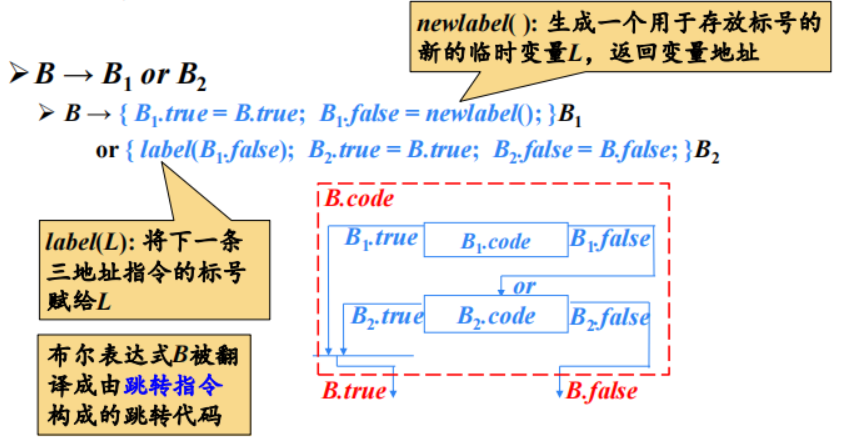
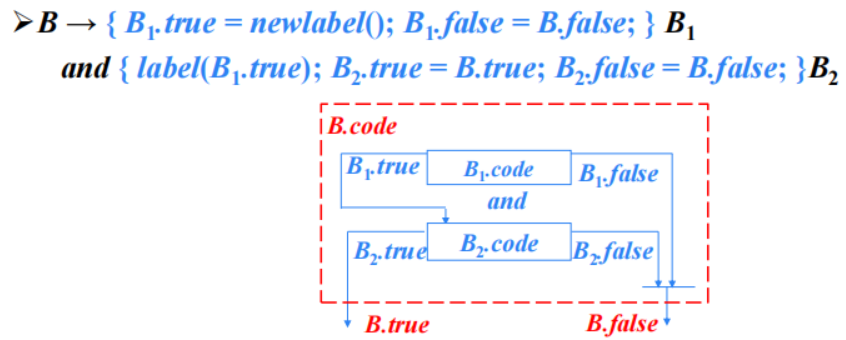
在跳转代码中,逻辑运算符&&、|| 和 ! 被翻译成跳转指令。运算符本身不出现在代码中,布尔表达式的值是通过代码序列中的位置来表示的。

3.1 布尔表达式的SDT
$$
\begin{array}{l}B \rightarrow E_{1} \text { relop } E_{2}{\text { gen(‘if’ } E_{1} \text { addr relop } E_{2} \text {.addr ‘goto’ B.true }) ; \text { gen(‘goto’ B.false); }}\end{array}
$$
$$
B \rightarrow \operatorname{true}\{ gen('goto’ B.true); \}
$$
$$
{B} \rightarrow false \{ gen('goto’ B.false ) ;\}
$$
$$
{B} \rightarrow(\{B_{1}.true = B. true ; B_{1}.false = B.false;\} {B}_{1})
$$
$$
{B} \rightarrow {not}\{B_{1}.true = B. false; B_{1}. false = B.true;\} {B}_{1}
$$
$3.1.1 B \rightarrow B_{1} or B_{2}$
$3.1.2 B \rightarrow B_{1} and B_{2}$
3.2 控制流语句的代码结构
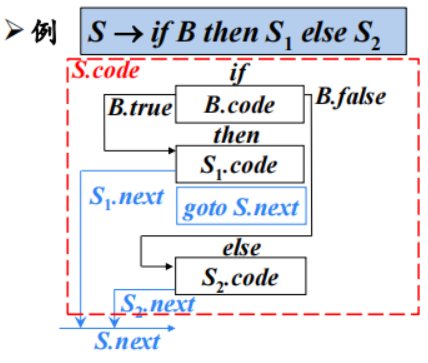
3.3 控制流语句SDT编写要点
分析每一个非终结符之前:
- 先计算继承属性
- 再观察代码结构图中该非终结符对应的方框顶部是否有导入箭头。如果有,调用label( )函数
上一个代码框执行完不顺序执行下一个代码框时,生成一条显式跳转指令。
有自下而上的箭头时,设置begin属性。且定义后直接调用label( )函数绑定地址。

控制流语句翻译的一个关键是确定跳转指令的目标标号,存在问题:生成跳转指令时,目标标号还不能确定。
解决办法:生成一些临时变量用来存放标号,将临时变量的地址作为继承属性传递到标号可以确定的地方。也就是说,当目标标号的值确定下来以后再赋给相应的变量。
缺点:需要进行两遍处理
- 第一遍生成临时的指令
- 第二遍将指令中的临时变量的地址改为具体的标号,从而得到最终的三地址指令
4 语义分析中的错误检测
错误1:变量或过程未经声明就使用 (赋值/过程调用语句翻译)

错误2:变量或过程名重复声明(声明语句翻译)
$$
{D} \rightarrow {T} {i d} ;\{ enter( id.lexeme, T.type, offset ) ; offset = offset + T.width ;\} {D}
$$
错误3:运算分量类型不匹配(赋值语句翻译)

错误4:操作符与操作数之间的类型不匹配

4.1 基本语句的语法制导翻译过程

 微信
微信 支付宝
支付宝





