论文精读3:GNN技术博客
论文题目:A Gentle Introduction to Graph Neural Networks
作者:Google
发表时间:2021年
1 引言
神经网络已适应利用图的结构和属性。我们探索构建图神经网络所需的组件——并激发它们背后的设计选择。
图就在我们身边;现实世界的对象通常是根据它们与其他事物的联系来定义的。一组对象以及它们之间的联系自然地表达为图形。十多年来,研究人员开发了对图数据进行操作的神经网络(称为图神经网络,或 GNN)。最近的发展提高了他们的能力和表达能力。我们开始看到抗菌药物发现等领域的实际应用,例如physics simulations(物理模拟)、fake news detection(假新闻检测)、traffic prediction(交通预测)和recommendation systems(推荐系统)。
本文探讨并解释了现代图神经网络。我们将这项工作分为四个部分。首先,我们看看哪种数据最自然地表达为图,以及一些常见的示例。其次,我们探讨图与其他类型数据的不同之处,以及使用图时必须做出的一些专门选择。第三,我们构建了一个现代 GNN,从该领域历史性的建模创新开始,遍历模型的每个部分。我们逐渐从简单的实现转向最先进的 GNN模型。第四,也是最后,我们提供了一个 GNN的playground,您可以在其中尝试真实的任务和数据集,以对 GNN模型的每个组件如何对其做出的预测做出贡献建立更强烈的直觉。
2 什么是图
首先,让我们先确定什么是图:图表示实体(节点)集合之间的关系(边)。
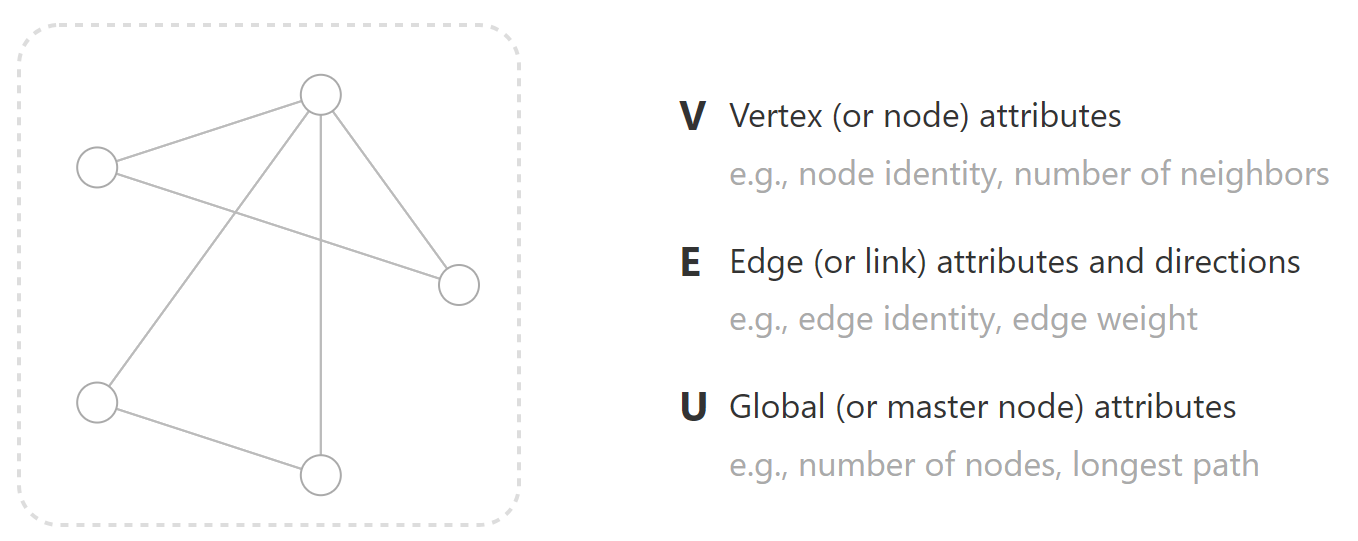
为了进一步描述每个节点、边或整个图,我们可以在图的每个部分中存储信息。
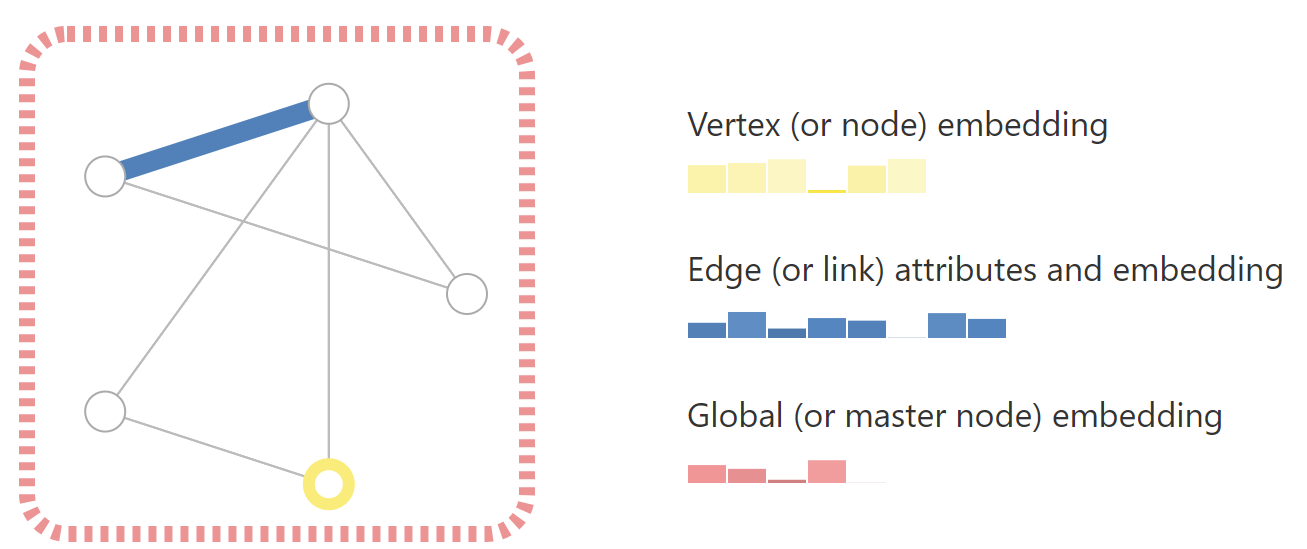
我们还可以通过将方向性与边(有向、无向)相关联来专门化图。

图是非常灵活的数据结构,如果现在这看起来很抽象,我们将在下一节中通过示例将其具体化。
3 图结构以及应用
你可能已经熟悉某些类型的图形数据,例如社交网络。然而,图表是一种极其强大且通用的数据表示形式,我们将展示两种您可能认为无法建模为图的数据类型:图像和文本。虽然违反直觉,但人们可以通过将图像和文本视为图形来更多地了解图像和文本的对称性和结构,并建立一种直觉,这将有助于理解其他不太像网格的图形数据,我们将在稍后讨论。
3.1 图片作为图
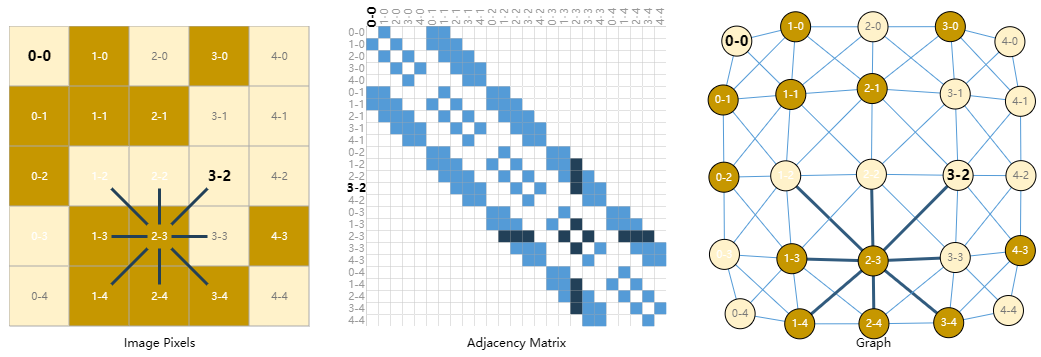
我们通常将图像视为具有图像通道的矩形网格,将它们表示为数组(例如,$244 \times 244 \times 3 $浮点数)。另一种将图像视为具有规则结构的图,其中每个像素代表一个节点,并通过边缘连接到相邻像素。每个非边界像素正好有 8 个邻居,每个节点存储的信息是表示该像素的 RGB值的 3 维向量。
可视化图的连通性的一种方法是通过其邻接矩阵。我们对节点进行排序,在本例中,每个节点是一个简单的$ 5 \times 5$笑脸图像中的 25 个像素,并填充一个矩阵$n_{nodes}×n_{nodes}$。如果两个节点共享一条边,则有一个条目。请注意,下面这三种表示形式都是同一数据的不同视图。
3.2 文本作为图
我们可以通过将索引与每个字符、单词或标记相关联,并将文本表示为这些索引的序列来数字化文本。这将创建一个简单的有向图,其中每个字符或索引都是一个节点,并通过边连接到其后面的节点。
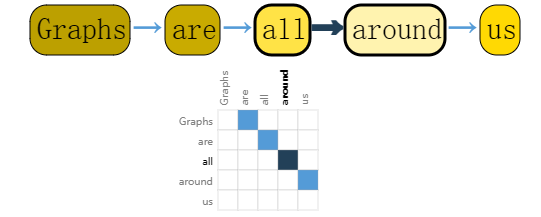
当然,在实践中,这通常不是文本和图像的编码方式:这些图形表示是多余的,因为所有图像和所有文本都将具有非常规则的结构。例如,图像的邻接矩阵具有带状结构,因为所有节点(像素)都连接在网格中。文本的邻接矩阵只是一条对角线,因为每个单词仅连接到前一个单词和下一个单词。
3.3 其他可以表示为图的数据
图是描述你可能已经熟悉的数据的有用工具。让我们继续讨论结构更加异构的数据。在这些示例中,每个节点的邻居数量是可变的(与图像和文本的固定邻居大小相反)。除了图之外,这些数据很难以任何其他方式表达。
分子作为图
分子是物质的组成部分,由 3D空间中的原子和电子构成。所有粒子都相互作用,但是当一对原子彼此保持稳定的距离时,我们说它们共享共价键。不同的原子对和键具有不同的距离(例如单键、双键)。将这个 3D对象描述为图是一个非常方便且常见的抽象,其中节点是原子,边是共价键。
以下是两种常见的分子及其相关图。

(左)香茅醛分子的
3D表示(中)分子中键的邻接矩阵(右)分子的图形表示

(左)咖啡因分子的
3D表示(中)分子中键的邻接矩阵(右)分子的图形表示
社交网络作为图表
社交网络是研究人们、机构和组织集体行为模式的工具。我们可以通过将个体建模为节点并将他们的关系建模为边来构建表示人群的图。
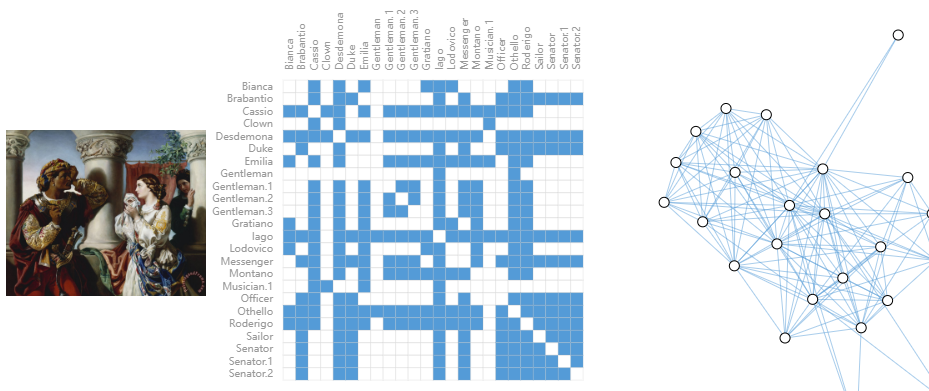
(左)戏剧《奥赛罗》中的场景图像。(中)剧中角色之间互动的邻接矩阵。(右)这些交互的图形表示。
与图像和文本数据不同,社交网络不具有相同的邻接矩阵。

(左)空手道锦标赛的图片。(中)空手道俱乐部中人与人之间互动的邻接矩阵。(右)这些交互的图形表示。
引用作为图表
科学家在发表论文时经常引用其他科学家的工作。我们可以将这些引用网络可视化为一个图,其中每篇论文都是一个节点,每个有向边是一篇论文与另一篇论文之间的引用。此外,我们可以将每篇论文的信息添加到每个节点中,例如摘要的词嵌入。
其他例子
在计算机视觉中,我们有时想要标记视觉场景中的对象。然后,我们可以通过将这些对象视为节点,并将它们的关系视为边来构建图。机器学习模型,编程代码和数学方程也可以表述为图,其中变量是节点,边是将这些变量作为输入和输出的操作。您可能会在其中一些上下文中看到术语“数据流图”。
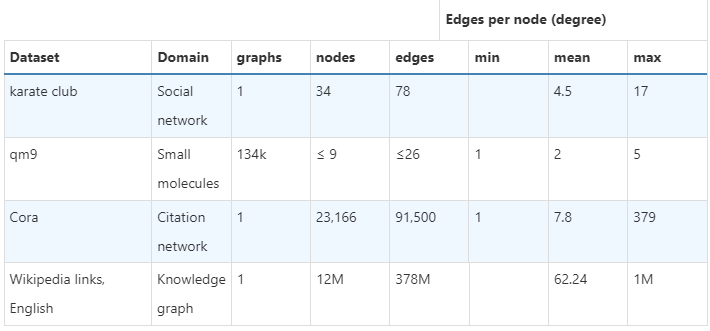
现实世界的图的结构在不同类型的数据之间可能有很大差异——有些图有很多节点,但它们之间的连接很少,反之亦然。图数据集在节点数、边数和节点连接性方面可能存在很大差异(在给定数据集内以及数据集之间)。
对现实世界中发现的图进行汇总统计。数字取决于特征化决策。更多有用的统计数据和图表可以在
KONECT中找到。
4 图结构可以解决哪些类型的问题
我们已经描述了一些自然图表的示例,但是我们想要对这些数据执行什么任务?图上的预测任务一般分为三种类型:图级、节点级和边级。
在图级任务中,我们预测整个图的单个属性。对于节点级任务,我们预测图中每个节点的一些属性。对于边级任务,我们想要预测图中边的属性或存在。
对于上述三个级别的预测问题(图级、节点级和边级),我们将证明以下所有问题都可以使用单个模型类GNN来解决。但首先,让我们更详细地浏览一下三类图预测问题,并提供每一类的具体示例。
4.1 图层面任务
在图级任务中,我们的目标是预测整个图的属性。例如,对于用图表表示的分子,我们可能想要预测该分子闻起来像什么,或者它是否会与与疾病有关的受体结合。
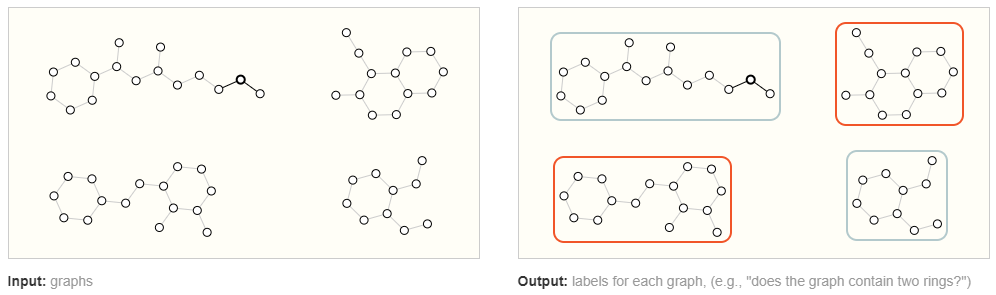
这类似于 MNIST和 CIFAR的图像分类问题,我们希望将标签与整个图像相关联。对于文本,类似的问题是情感分析,我们希望立即识别整个句子的情绪或情感。
4.2 节点层面任务
节点级任务涉及预测图中每个节点的身份或角色。
节点级预测问题的一个典型例子是扎克的空手道俱乐部。该数据集是一个单一的社交网络图,由在政治分歧后宣誓效忠两个空手道俱乐部之一的个人组成。故事是这样的,Hi 先生(教练)和 John H(管理员)之间的不和在空手道俱乐部中造成了分裂。节点代表各个空手道练习者,边代表空手道之外这些成员之间的互动。预测问题是对给定成员在不和之后是否忠诚于 Mr. Hi 或 John H 进行分类。在这种情况下,节点与讲师或管理员之间的距离与该标签高度相关。
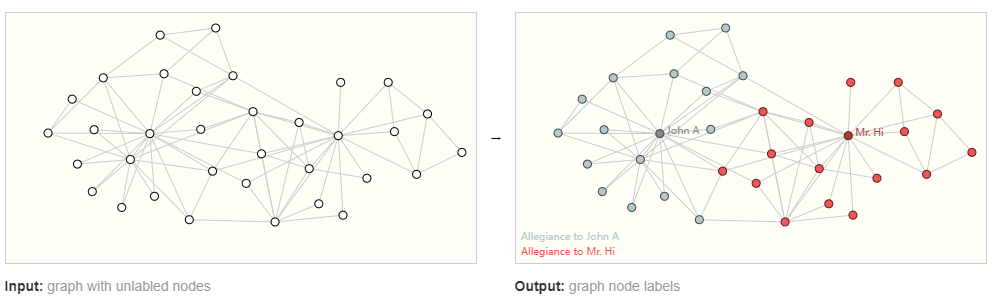
左边是问题的初始条件,右边是可能的解决方案,其中每个节点都根据联盟进行了分类。该数据集可用于其他图问题,例如无监督学习。
按照图像类比,节点级预测问题类似于图像分割,我们试图标记图像中每个像素的作用。对于文本,类似的任务是预测句子中每个单词的词性(例如名词、动词、副词等)。
4.3 边层面任务
图中剩下的预测问题是边缘预测。
边级推理的一个例子是图像场景理解。除了识别图像中的对象之外,深度学习模型还可用于预测它们之间的关系。我们可以将其表述为边缘级分类:给定代表图像中对象的节点,我们希望预测这些节点中的哪些共享边缘或该边缘的值是什么。如果我们希望发现实体之间的连接,我们可以考虑完全连接的图,并根据其预测值修剪边缘以得到稀疏图。
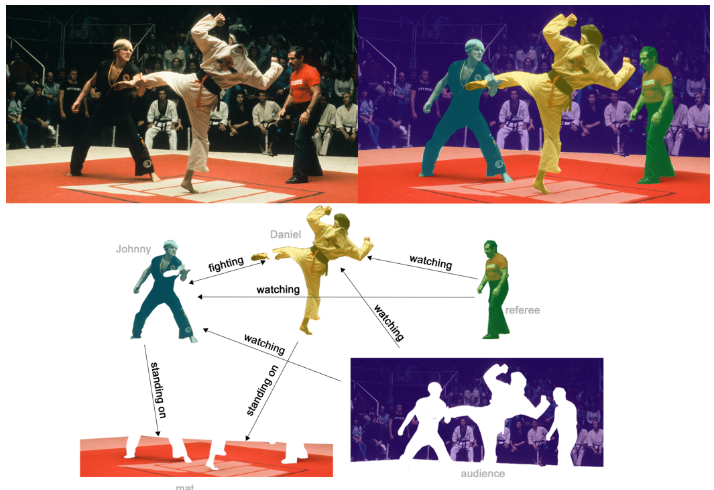
在上面的 (b) 中,原始图像 (a) 被分割为五个实体:每位拳手、裁判、观众和垫子。 (c) 显示了这些实体之间的关系。
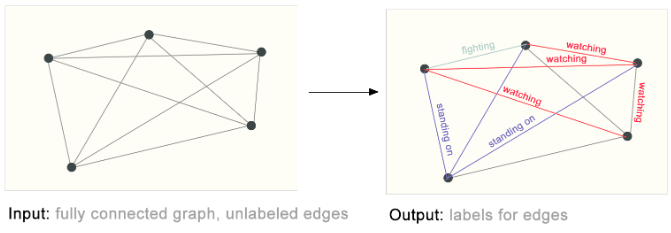
在左侧,有一个根据之前的视觉场景构建的初始图。右侧是当根据模型的输出修剪一些连接时该图可能的边缘标记。
5 在机器学习中使用图的挑战
那么,如何使用神经网络来解决这些不同的图形任务呢?第一步是考虑如何表示与神经网络兼容的图。
机器学习模型通常采用矩形或类似网格的数组作为输入。因此,如何以与深度学习兼容的格式表示它们并不是立即直观的。图形最多包含四种类型的信息,我们可能希望使用这些信息来进行预测:节点、边、全局上下文和连通性。前三个相对简单:例如,对于节点,我们可以通过为每个节点分配一个索引$i$并将特征存储在$node_i$中来形成结点特征矩阵$N$。虽然这些矩阵的样本数量可变,但无需任何特殊技术即可进行处理。
但是,表示图形的连通性更为复杂。也许最明显的选择是使用邻接矩阵,因为这很容易被拉伸。但是,这种表示方式有一些缺点。从示例数据集表中,我们看到图中的节点数量可能约为数百万个,并且每个节点的边数量可能变化很大。通常,这会导致非常稀疏的邻接矩阵,这在空间上效率低下。
另一个问题是,有许多邻接矩阵可以编码相同的连通性,并且不能保证这些不同的矩阵会在深度神经网络中产生相同的结果(也就是说,它们不是置换不变的)。
例如,之前的奥赛罗图可以等同于这两个邻接矩阵来描述。它也可以用节点的所有其他可能的排列来描述。

表示同一图形的两个邻接矩阵。
下面的示例显示了可以描述这个包含 4 个节点的小图的每个邻接矩阵。这已经是相当多的邻接矩阵——对于像奥赛罗这样的大例子,这个数字是站不住脚的。
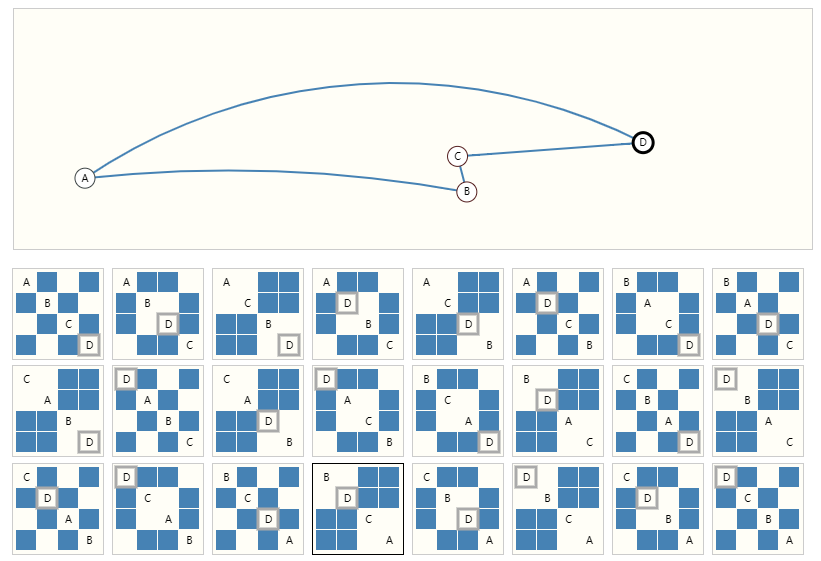
所有这些邻接矩阵都表示同一个图形。单击边以将其删除,在“虚拟边”上添加它,矩阵将相应地更新。
表示稀疏矩阵的一种优雅且节省内存的方法是一种表示邻接列表。它们将节点$n_i$和$n_j$之间的边$e_k$联通性描述为邻接列表的第$k$个条目中的元组$(i,j)$。由于我们预计边的数量远低于邻接矩阵的条目数$(n^2_{nodes})$,因此我们避免了在图形的不连贯部分进行计算和存储。
为了使这个概念具体化,我们可以看到在此规范下如何表示不同图形中的信息:
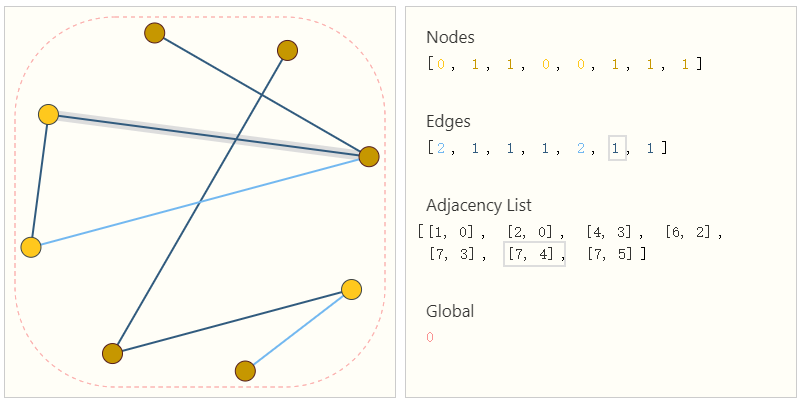
一边是小图,另一边是张量表示中的图信息。
应该注意的是,该图使用每个节点/边/全局的标量值,但大多数实际的张量表示每个图属性都有向量。我们将处理大小为$[n_{nodes},node_{dim}]$的节点张量,而不是大小为$[n_{nodes}]$的节点张量,其他图形属性也是如此。
6 图神经网络
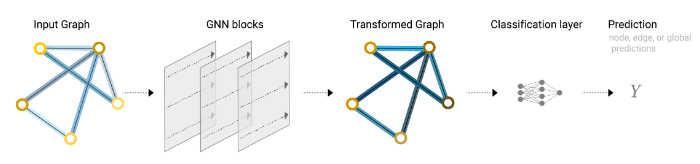
现在,图形的描述采用排列不变的矩阵格式,我们将描述使用图形神经网络 (GNN) 来解决图形预测任务。GNN 是对图的所有属性(节点、边、全局上下文)的可优化变换,它保留了图的对称性(排列不变性)。我们将使用 Gilmer 等人提出的“消息传递神经网络”框架来构建 GNN。
使用 Battaglia 等人介绍的 Graph Nets 架构原理图。GNN采用“图进图”的架构,这意味着这些模型类型接受图作为输入,将信息加载到其节点、边和全局上下文中,并逐步转换这些嵌入,而不改变输入图的连通性。
6.1 最简单的GNN
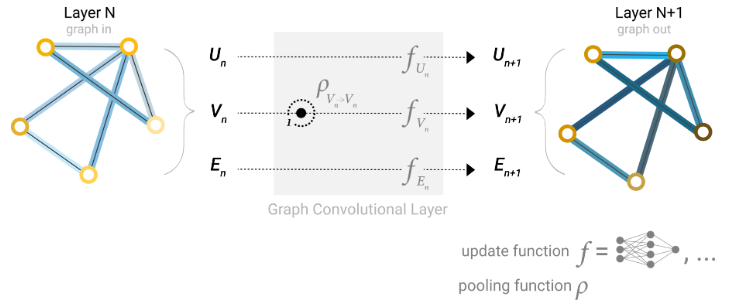
通过我们上面构建的图形的数值表示(使用向量而不是标量),我们现在已经准备好构建 GNN。我们将从最简单的 GNN架构开始,在这个架构中,我们学习所有图形属性(节点、边、全局)的新嵌入,但我们还没有使用图形的连通性。
这个GNN在图的每个分量上都使用一个单独的多层感知器(MLP)(或你最喜欢的可微模型),我们称之为GNN层。对于每个节点向量,我们应用 MLP并返回一个学习到的节点向量。我们对每条边都做同样的事情,学习每条边的嵌入,也对全局上下文向量做同样的事情,学习整个图的单个嵌入。
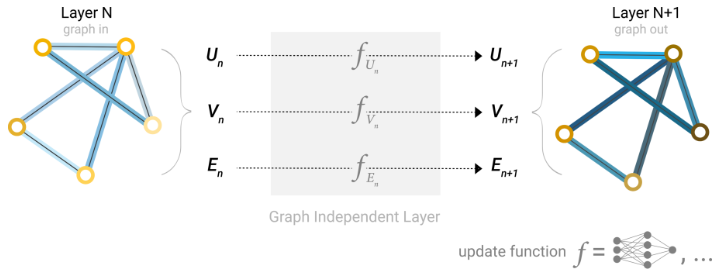
简单
GNN的单层。图形是输入,每个分量$ (V,E,U)$都由MLP更新以生成新图形。每个函数下标表示GNN模型第$ n $层的不同图形属性的单独函数。
与神经网络模块或层一样,我们可以将这些GNN层堆叠在一起。
由于 GNN 不会更新输入图的连通性,因此我们可以使用与输入图相同的邻接列表和相同数量的特征向量来描述 GNN 的输出图。但是,输出图更新了嵌入,因为 GNN 更新了每个节点、边和全局上下文表示。
6.2 通过Pooling信息进行GNN预测
我们已经构建了一个简单的GNN,但是我们如何在上面描述的任何任务中做出预测呢?
我们将考虑二元分类的情况,但这个框架可以很容易地扩展到多类或回归情况。如果任务是对节点进行二元预测,并且图形已经包含节点信息,则方法很简单:对于每个节点嵌入,应用线性分类器。
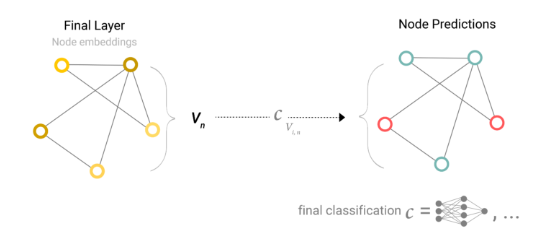
我们可以想象一个社交网络,我们希望通过不使用用户数据(节点)来匿名化用户数据(节点),只使用关系数据(边缘)。此类方案的一个实例是我们在“节点级任务”小节中指定的节点任务。在空手道俱乐部的例子中,这只是使用人们之间的交往次数来确定与Hi先生或John H的联盟。
不管有多少个顶点,这里只有一个全连接层,所有顶点都会共享这一个全连接层的参数。
然而,事情并不总是那么简单。例如,可能将图形中的信息存储在边中,但节点中没有信息,但仍需要对节点进行预测。我们需要一种方法来从边缘收集信息,并将它们提供给节点进行预测。我们可以通过池化来做到这一点。池化分两个步骤进行:
- 对于要池化的每个项目,收集它们的每个嵌入并将它们连接到一个矩阵中。
- 然后,通常通过求和运算对收集的嵌入进行聚合。
用字母$\rho$表示池化操作,并表示我们正在从边收集到节点的信息,如$p_{E_{n} \rightarrow V_{n}}$。
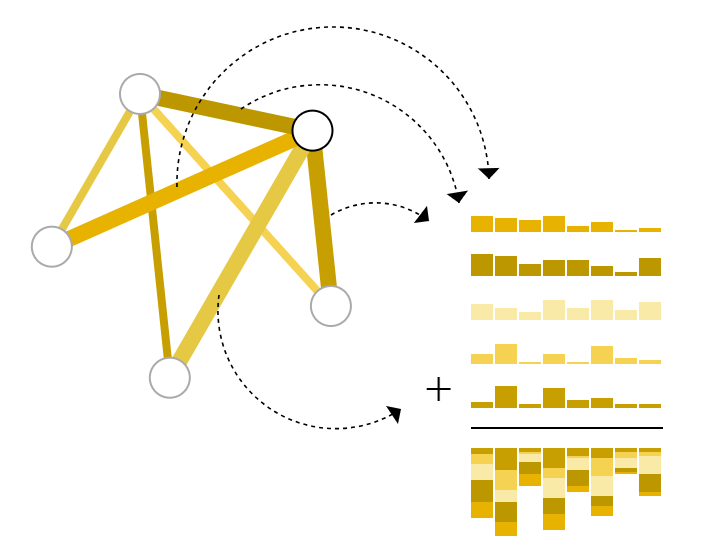
从这个点相邻的边中收集信息。
因此,如果我们只有边的特征,并且试图预测二分类节点信息,我们可以使用池化将信息路由(或传递)到它需要去的地方。该模型如下所示。
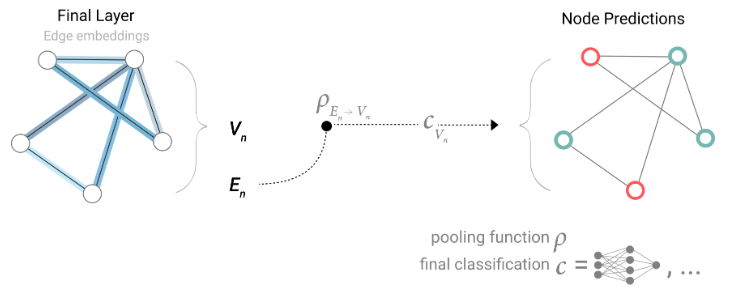
如果我们只有节点级的特征,并且试图预测二分类边信息,则模型如下所示。
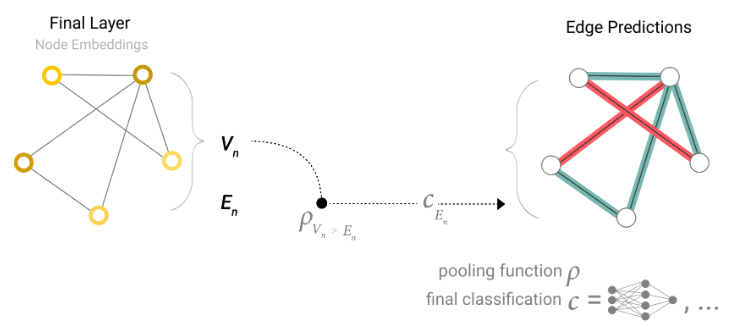
此类场景的一个示例是我们在“边级别任务”子部分中指定的边缘任务。节点可以被识别为图像实体,我们正在尝试对顶点进行二分类。
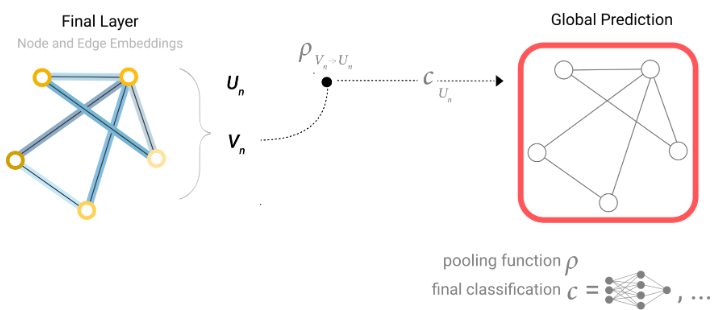
这是预测分子性质的常见情况。例如,我们有原子信息、连通性,我们想知道分子的毒性(有毒/无毒),或者它是否具有特定的气味(玫瑰/非玫瑰)。
在我们的示例中,分类模型$c$可以很容易地替换为任何可微模型,或者使用广义线性模型适应多类分类。
使用
GNN模型的端到端预测任务。
现在我们已经证明了我们可以构建一个简单的GNN模型,并通过在图形的不同部分之间路由信息来进行二元预测。这种池化技术将作为构建更复杂的GNN模型的构建块。如果我们有新的图形属性,我们只需要定义如何将信息从一个属性传递到另一个属性。
请注意,在这个最简单的 GNN公式中,我们根本没有在 GNN层内部使用图形的连通性。每个节点都是独立处理的,每个边以及全局上下文都是独立处理的。我们仅在汇集信息进行预测时才使用连通性。
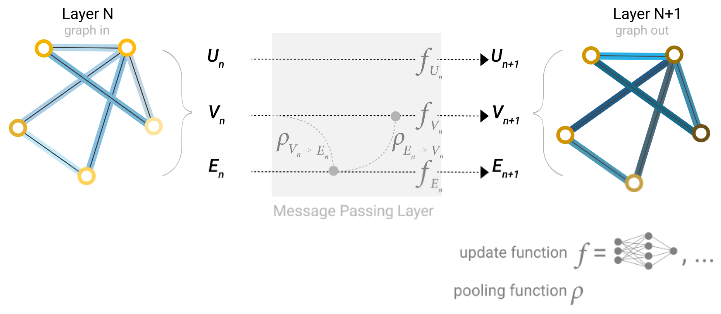
6.3 在图形的各个部分之间传递消息
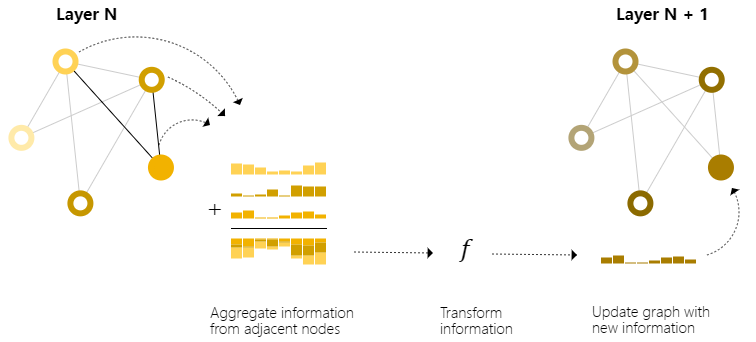
我们可以通过在GNN层中使用池化来做出更复杂的预测,以便使我们学习的嵌入意识到图的连通性。我们可以使用消息传递来做到这一点,其中相邻节点或边交换信息并影响彼此的更新嵌入。
消息传递分三个步骤进行:
- 对于图中的每个节点,收集所有相邻节点嵌入(或消息),这就是上面描述的$g$函数
- 通过聚合函数(如$sum$)聚合所有消息
- 所有池化消息都通过更新函数传递,该函数通常是学习的神经网络
正如池化可以应用于节点或边一样,消息传递也可以发生在节点或边之间。这些步骤是利用图形连通性的关键。我们将在 GNN层中构建更详细的消息传递进行改变,从而产生具有增强表现和效果的 GNN模型。
当应用一次时,此操作序列是最简单的消息传递 GNN 层类型。
这让人想起标准卷积:从本质上讲,消息传递和卷积是聚合和处理元素邻居信息以更新元素值的操作。在图结构中,元素是一个节点,而在图像中,元素是一个像素。但是,图结构中相邻节点的数量可以是可变的,这与图像中每个像素都有一定数量的相邻元素不同。
通过将传递GNN层的消息堆叠在一起,节点最终可以整合来自整个图的信息:在三层之后,一个节点拥有距离它三步远的节点的信息。
我们可以更新我们的架构图,以包含这个新的节点信息源:
GCN架构示意图,该架构通过汇集距离为 1 度的相邻节点来更新图形的节点表示。
6.3.1 学习边表示
我们的数据集并不总是包含所有类型的信息(节点、边缘和全局上下文)。当我们想对节点进行预测,但我们的数据集只有边信息时,我们在上面展示了如何使用池化将信息从边缘路由到节点,但仅限于模型的最后预测步骤。我们可以使用消息传递在 GNN 层内的节点和边之间共享信息。
我们可以采用与之前使用相邻节点信息相同的方式合并来自相邻边缘的信息,即首先汇集边缘信息,使用更新函数对其进行转换,然后存储它。
然而,存储在图中的节点和边缘信息不一定具有相同的大小或形状,因此如何将它们组合起来并不清楚。一种方法是学习从边空间到节点空间的线性映射,反之亦然。或者,可以在更新功能之前将它们连接在一起。
消息传递层的架构示意图。第一步“准备”一条消息,该消息由来自边缘及其连接节点的信息组成,然后将消息“传递”到节点。
在构建 GNN时,我们更新哪些图形属性以及以何种顺序更新它们是设计决策之一。我们可以选择是在边缘嵌入之前更新节点嵌入,还是相反。这是一个开放的研究领域,有各种各样的解决方案——例如,我们可以以“编织”的方式进行更新,其中,我们有四个更新的表示,它们被组合成新的节点和边表示:节点到节点(线性)、边到边(线性)、节点到边(边缘层)、边到节点(节点层)。
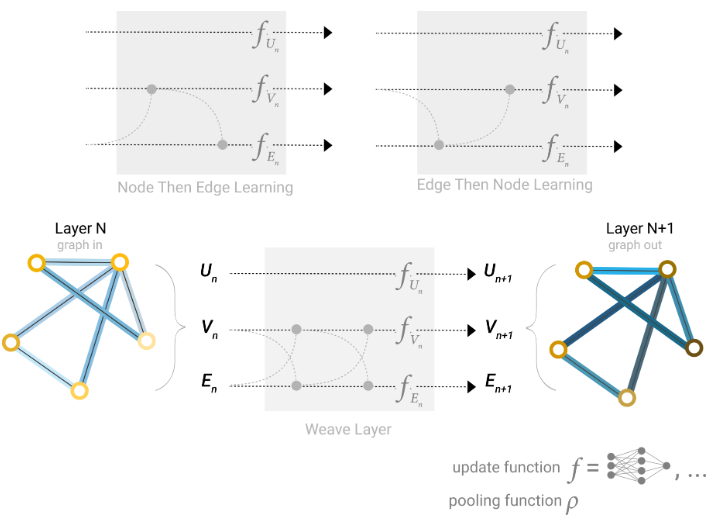
我们可以在GNN层中结合边缘和节点表示的一些不同方式。
6.3.2 添加全局表示
到目前为止,我们所描述的网络存在一个缺陷:即使我们多次应用消息传递,在图中彼此相距很远的节点可能永远无法有效地相互传输信息。对于一个节点,如果我们有 k 层,信息将在最多 k 步之外传播。如果预测任务依赖于相距很远的节点或节点组,这可能是一个问题。一种解决方案是让所有节点能够相互传递信息。不幸的是,对于大型图形来说,这很快就会变得计算成本高昂(尽管这种方法被称为“虚拟边缘”,已被用于分子等小型图形)。
此问题的一种解决方案是使用图形(U) 的全局表示,该图形有时称为主节点或上下文向量。这个全局上下文向量连接到网络中的所有其他节点和边,并且可以充当它们之间的桥梁来传递信息,从而为整个图形构建表示。这创建了比以其他方式学习的更丰富、更复杂的图形表示。
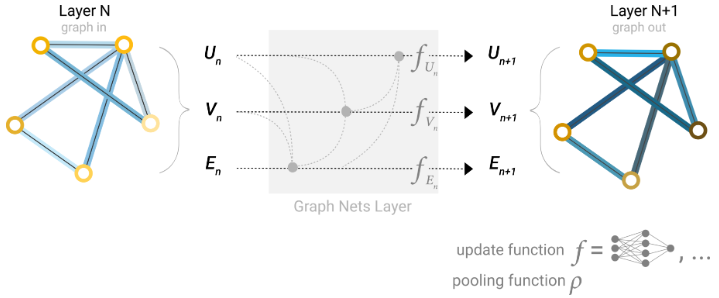
利用全局表示的图形网络架构示意图。
在这个视图中,所有图形属性都学习了表示,因此我们可以在池化过程中通过调节我们感兴趣的属性相对于其余属性的信息来利用它们。例如,对于一个节点,我们可以考虑来自相邻节点、连接边和全局信息的信息。为了在所有这些可能的信息源上调节嵌入的新节点,我们可以简单地将它们连接起来。此外,我们还可以通过线性映射将它们映射到同一空间,然后添加它们或应用特征调制层,这可以被认为是一种特殊的注意力机制。
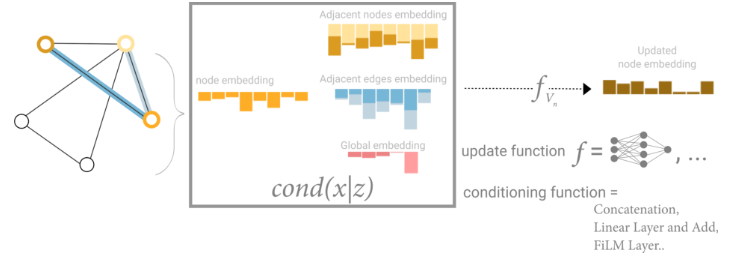
基于其他三个嵌入(相邻节点、相邻边、全局)调节一个节点信息的原理图。此步骤对应于 Graph Nets 层中的节点操作。
7 GNN实验
我们在这里描述了各种各样的 GNN 组件,但它们在实践中实际上有何不同?这个 GNN playground让你可以看到这些不同的组件和架构如何有助于 GNN 学习真实任务的能力。
我们的 Playground 展示了一个带有小分子图的图形级预测任务。我们使用 Leffingwell 气味数据集,它由具有相关气味感知(标签)的分子组成。预测分子结构(图形)与其气味的关系是一个跨越化学、物理学、神经科学和机器学习的 100 年历史的问题。
为了简化这个问题,我们只考虑每个分子一个二进制标签,根据专业调香师的标记,对分子图是否闻起来“刺鼻”进行分类。如果一个分子具有强烈、醒目的气味,我们就说它具有“刺鼻”的气味。例如,可能含有“烯丙醇”分子的大蒜和芥末就具有这种品质。分子 piperitone通常用于薄荷味糖果,也被描述为具有刺激性气味。
我们将每个分子表示为一个图形,其中原子是包含其原子身份(碳、氮、氧、氟)的独热编码的节点,键是包含一热编码其键类型(单键、双键、三键或芳香族)的边。
我们将使用顺序GNN层构建针对此问题的通用建模,然后使用带有Sigmoid激活的线性模型进行分类。我们的 GNN 的设计空间有许多可以自定义模型的组件:
- GNN 层数:也称为深度
- 更新时每个属性的维度:更新函数是一个 1 层 MLP,具有 relu 激活函数和用于激活归一化的层范数
- 池化中使用的聚合函数:最大值、平均值或总和
- 更新的图形属性:或消息传递的样式:节点、边和全局表示。我们通过布尔开关(打开或关闭)来控制它们。基线模型将是一个与图形无关的 GNN(所有消息传递),它将最后的所有数据聚合到一个单一的全局属性中。切换所有消息传递函数会产生 GraphNets 架构
为了更好地理解GNN如何学习图形的任务优化表示,我们还研究了GNN的倒数第二层激活。这些“图嵌入”是 GNN 模型在预测之前的输出。由于我们使用广义线性模型进行预测,因此线性映射足以让我们了解我们如何围绕决策边界学习表示。
由于这些是高维向量,我们通过主成分分析(PCA)将它们简化为二维。一个完美的模型可以查看单独的标记数据,但由于我们正在降低维度并且也有不完美的模型,所以这个边界可能更难看到。
尝试使用不同的模型架构来构建您的直觉。例如,查看是否可以编辑左侧的分子以增加模型预测。对于不同的模型架构,相同的编辑是否具有相同的效果?
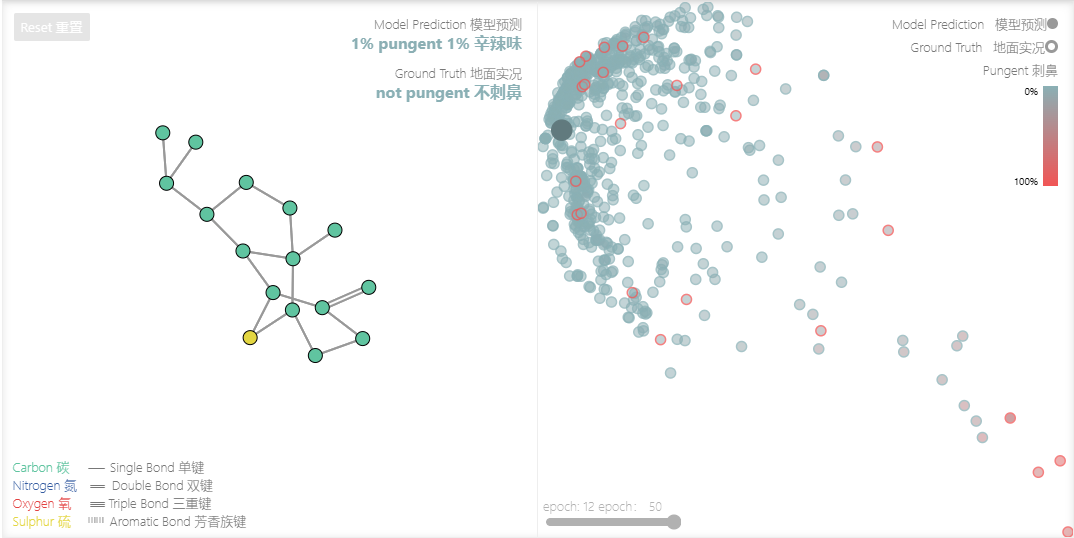
编辑分子以查看预测如何变化,或更改模型参数以加载不同的模型。在散点图中选择不同的分子。
7.1 一些经验性的GNN设计经验
在探索上述架构选择时,您可能已经发现某些模型比其他模型具有更好的性能。是否有一些明确的GNN设计选择会给我们带来更好的性能?例如,较深的GNN模型是否比较浅的GNN模型表现更好?或者在聚合函数之间是否有明确的选择?答案将取决于数据,甚至特征化和构建图形的不同方式也会给出不同的答案。
通过下面的交互式图形,我们探索了 GNN 架构的空间以及在几个主要设计选择中执行此任务的性能:消息传递的样式、嵌入的维度、层数和聚合操作类型。
散点图中的每个点都代表一个模型:$x$轴是可训练变量的数量,$y $轴是性能。将鼠标悬停在某个点上可查看 GNN 架构参数。
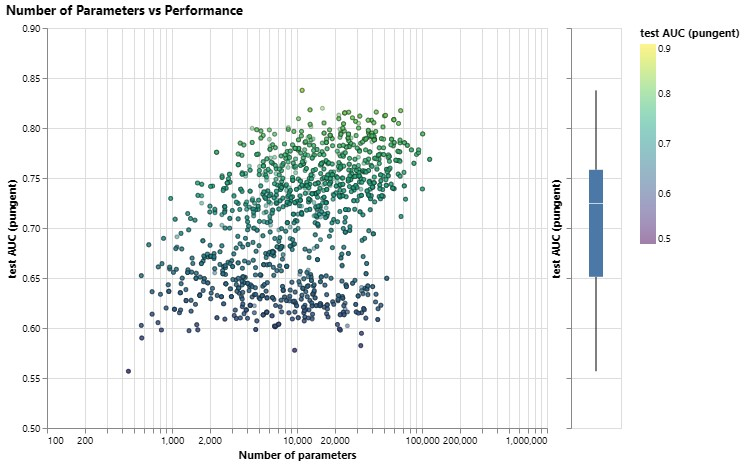
每个模型的性能与其可训练变量数量的散点图。将鼠标悬停在某个点上可查看 GNN 架构参数。
首先要注意的是,令人惊讶的是,更多的参数确实与更高的性能相关。GNN是一种参数效率非常高的模型类型:即使是少量的参数($3k$),我们已经可以找到高性能的模型。
7.1.1 不同属性嵌入
接下来,我们可以查看基于不同图形属性的学习表示的维度聚合的性能分布。
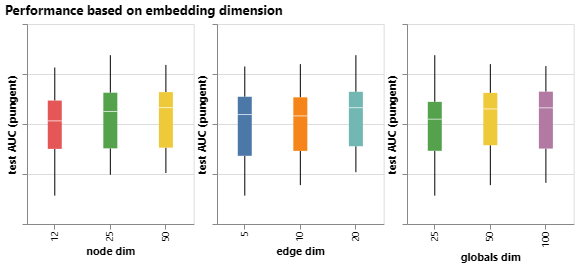
在不同的节点、边缘和全局维度上聚合模型的性能。
我们可以注意到,维数较高的模型往往具有更好的均值和下限性能,但在最大值下没有发现相同的趋势。可以找到一些性能最佳的模型用于较小的尺寸。由于维数越高,参数数量越多,因此这些观测值与上图相辅相成。
7.1.2 不同层数
接下来,我们可以看到基于 GNN 层数的性能细分。
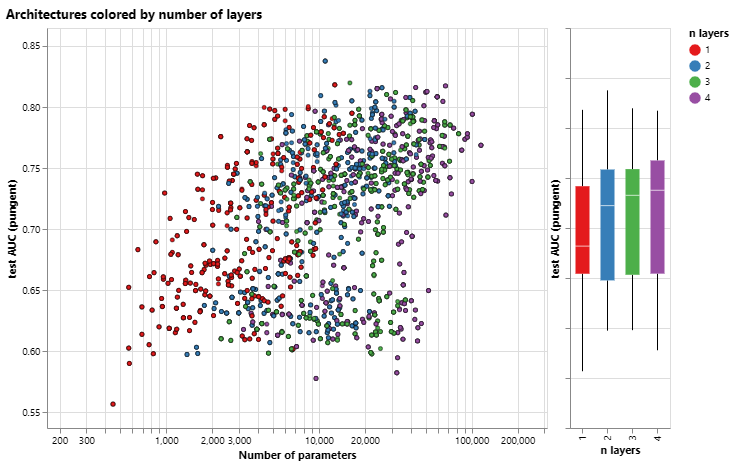
层数与模型性能的关系图,以及模型性能与参数数量的散点图。每个点都由层数着色。
箱形图显示了类似的趋势,虽然平均性能往往随着层数的增加而增加,但性能最好的模型没有三层或四层,而是两层。此外,性能的下限随着四层的增加而降低。这种效应之前已经观察到,层数更多的GNN将在更远的距离上广播信息,并且可能会冒着其节点表示在许多连续迭代中被“稀释”的风险。
7.1.3 不同汇聚操作
我们的数据集是否有首选的聚合操作?下图根据聚合类型对性能进行了细分。
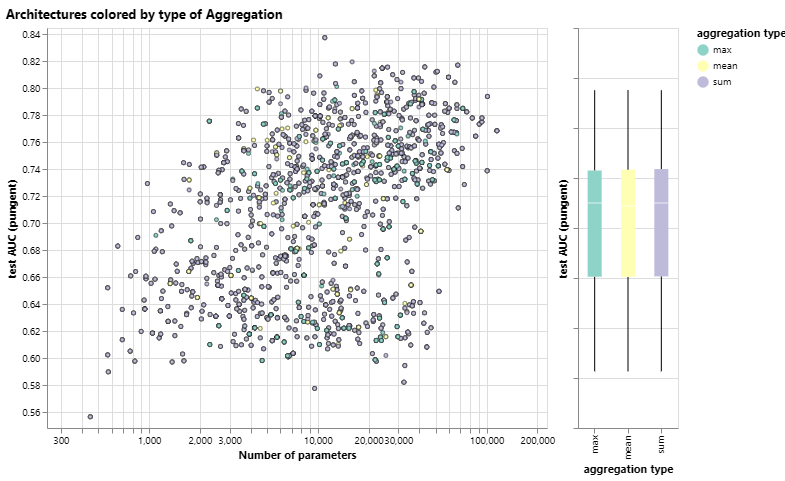
聚合类型与模型性能的图表,以及模型性能与参数数量的散点图。每个点都按聚合类型着色。
总体而言,$sum $似乎对$ mean $性能有非常轻微的改进,但$ max $或$ mean $可以给出同样好的模型。在查看 aggregation operations 的判别/表达能力时,这对于上下文很有用。
之前的探索给出了好坏参半的信息。我们可以找到平均趋势,其中复杂性越高,性能越好,但我们可以找到明显的反例,其中参数、层数或维度较少的模型表现更好。一个更明显的趋势是关于相互传递信息的属性数量。
7.1.4 不同消息传递类型
在这里,我们根据消息传递的样式对性能进行细分。在这两个极端,我们考虑了在图形实体(“none”)之间不通信的模型和在节点、边和全局变量之间传递消息的模型。
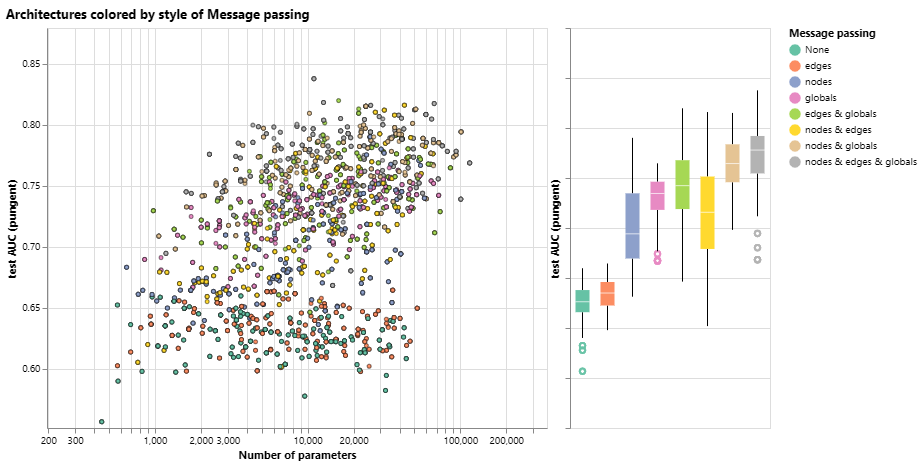
消息传递与模型性能的关系图,以及模型性能与参数数量的散点图。每个点都由消息传递着色。
总的来说,我们看到,图形属性进行通信的次数越多,平均模型的性能就越好。我们的任务以全局表示为中心,因此明确学习此属性也往往会提高性能。我们的节点表示似乎也比边表示更有用,这是有道理的,因为这些属性中加载了更多信息。
从这里开始,您可以采取许多方向来获得更好的性能。我们希望其中两个突出两个大方向,一个与更复杂的图形算法相关,另一个与图形本身有关。
到目前为止,我们的 GNN 是基于邻域的池化操作。有一些图形概念很难用这种方式表达,例如线性图形路径(连接的节点链)。设计新的机制,使图信息可以在GNN中被提取、执行和传播,这是当前的一个研究领域。
GNN研究的前沿之一不是制作新的模型和架构,而是“如何构建图形”,更准确地说,为图形注入可以利用的附加结构或关系。正如我们粗略地看到的,图形属性传达的次数越多,我们就越倾向于拥有更好的模型。在这种特殊情况下,我们可以考虑通过在节点之间添加额外的空间关系,添加不是键的边缘,或者在子图之间明确学习关系,使分子图的特征更加丰富。
8 相关技术
接下来,我们将介绍与GNN相关的无数与图结构相关的主题。
8.1 其他类型的图
虽然我们只描述了每个属性的矢量化信息的图形,但图形结构更灵活,可以容纳其他类型的信息。幸运的是,消息传递框架足够灵活,以至于将 GNN 适应更复杂的图形结构通常是为了定义新的图形属性如何传递和更新信息。
例如,我们可以考虑多边图或多重图,其中一对节点可以共享多种类型的边,当我们想要根据节点的类型以不同的方式对节点之间的交互进行建模时,就会发生这种情况。例如,对于社交网络,我们可以根据关系类型(熟人、朋友、家人)指定边缘类型。GNN 可以通过为每种边类型设置不同类型的消息传递步骤来进行调整。我们还可以考虑嵌套图,例如,节点代表一个图,也称为超节点图。嵌套图可用于表示层次结构信息。例如,我们可以考虑一个分子网络,其中节点代表一个分子,如果我们有一种将一个分子转化为另一个分子的方法(反应),那么两个分子之间共享一条边。在这种情况下,我们可以通过让一个 GNN 在分子水平上学习表示,另一个在反应网络水平上学习表示,并在训练期间在它们之间交替学习。
另一种类型的图是超图,其中边可以连接到多个节点,而不仅仅是两个节点。对于给定的图,我们可以通过识别节点社区并分配连接到社区中所有节点的超边来构建超图。
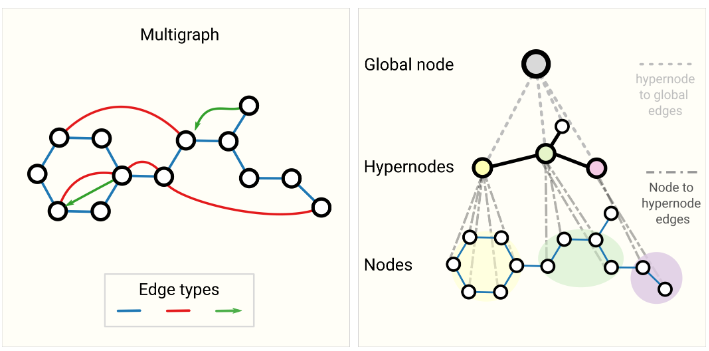
更复杂图形的示意图。在左边,我们有一个多图的例子,它有三种边类型,包括有向边。在右边,我们有一个三级层次结构图,中间级节点是超节点。
8.2 GNN 中的采样图和批处理
训练神经网络的一种常见做法是使用在训练数据的随机常数大小(批量大小)子集(小批量)上计算的梯度来更新网络参数。这种做法给图形带来了挑战,因为彼此相邻的节点和边的数量是可变的,这意味着我们不能有一个恒定的批量大小。使用图形进行批处理的主要思想是创建子图,以保留较大图形的基本属性。这种图形采样操作高度依赖于上下文,并涉及从图形中子选择节点和边。这些操作在某些情况下(引文网络)可能有意义,而在其他上下文中,这些操作可能太强了(分子,其中子图仅代表一个新的、更小的分子)。如何对图表进行采样是一个开放的研究问题。
如果我们关心在邻域级别保持结构,一种方法是随机采样统一数量的节点,即我们的节点集。然后添加与节点集相邻的距离为$ k $的相邻节点,包括它们的边。
每个邻域都可以被视为一个单独的图,GNN 可以在这些子图的批次上进行训练。可以忽略损失,只考虑节点集,因为所有相邻节点都有不完整的邻域。更有效的策略可能是首先随机抽取单个节点,将其邻域扩展到距离$ k $,然后在扩展集内选择另一个节点。一旦构造了一定数量的节点、边或子图,就可以终止这些操作。如果上下文允许,我们可以通过选择初始节点集,然后对恒定数量的节点进行子采样(例如随机,或通过随机游走或 Metropolis 算法)来构建恒定大小的邻域。
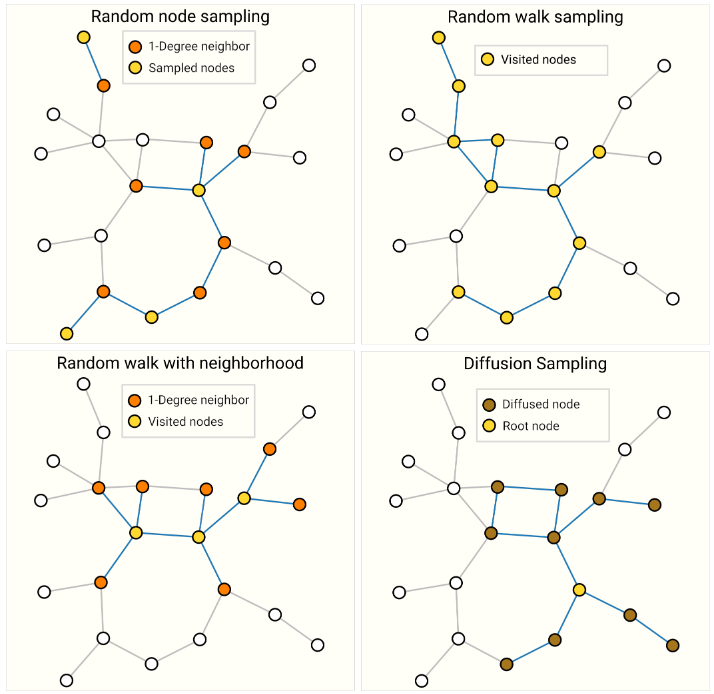
对同一图形进行采样的四种不同方法。抽样策略的选择在很大程度上取决于上下文,因为它们将生成不同的图形统计信息分布(# 节点、#edges 等)。对于高度连通的图形,还可以对边进行二次采样。
当图形足够大以至于无法放入内存中时,对图形进行采样尤为重要。激发新的架构和培训策略,例如 Cluster-GCN,我们预计图形数据集的规模将在未来继续增长。
8.3 归纳偏置
在构建模型以解决特定类型的数据上的问题时,我们希望将模型专业化以利用该数据的特征。当这成功完成时,我们通常会看到更好的预测性能、更短的训练时间、更少的参数和更好的泛化。
例如,在对图像进行标记时,我们希望利用这样一个事实,即无论它在图像的左上角还是右下角,狗仍然是狗。因此,大多数图像模型使用卷积,卷积是平移不变的。对于文本,标记的顺序非常重要,因此递归神经网络按顺序处理数据。此外,一个标记(例如“not”一词)的存在会影响句子其余部分的含义,因此我们需要能够“参与”文本其他部分的组件,而 BERT 和 GPT-3 等转换器模型可以做到这一点。这些是归纳偏差的一些例子,在这些例子中,我们正在识别数据中的对称性或规律性,并添加利用这些属性的建模组件。
在图的情况下,我们关心每个图分量(边、节点、全局)如何相互关联,因此我们寻找具有关系归纳偏差的模型。
模型应保留实体之间的显式关系(邻接矩阵)并保持图对称性(排列不变性)。我们预计实体之间交互很重要的问题将从图形结构中受益。具体来说,这意味着在集合上设计转换:节点或边上的操作顺序无关紧要,操作应该适用于可变数量的输入。
8.4 比较聚合操作
汇集来自相邻节点和边缘的信息是任何相当强大的 GNN 架构中的关键步骤。由于每个节点的邻居数目都是可变的,并且由于我们想要一种可微分的方法来聚合此信息,因此我们希望使用与节点排序和提供的节点数无关的平滑聚合操作。
选择和设计最佳聚合操作是一个开放的研究课题。聚合操作的一个理想属性是相似的输入提供相似的聚合输出,反之亦然。一些非常简单的候选排列不变运算是 sum、mean 和 max。方差等汇总统计量也有效。所有这些都采用可变数量的 inputs,并提供相同的 output,无论 input ordering如何。让我们来探讨一下这些操作之间的区别。
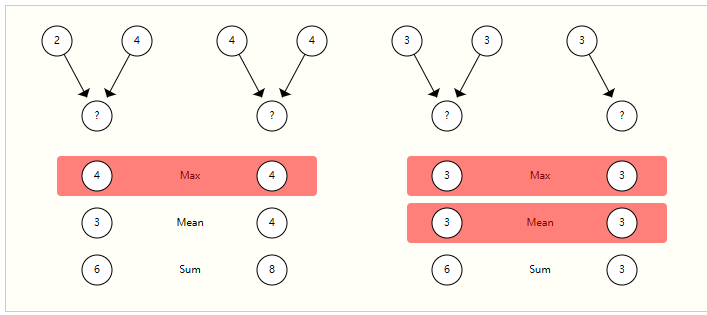
没有池化类型可以始终区分图形对,例如左侧的 max pooling 和右侧的 sum / mean pooling。
没有一个操作是绝对的最佳选择。当节点的相邻要素数量高度可变或您需要局部邻域特征的标准化视图时,均值运算可能很有用。当您想要高亮显示局部邻域中的单个突出要素时,max 操作可能非常有用。Sum 通过提供特征的局部分布的快照,在这两者之间提供平衡,但由于它未归一化,因此也可以突出显示异常值。在实践中,通常使用 sum。
设计聚合操作是一个开放的研究问题,它与集合上的机器学习相交。新方法,例如 Principal Neighborhood 聚合通过连接多个聚合操作并添加一个扩展函数来考虑这些操作,该函数取决于要聚合的实体的连接程度。同时,还可以设计特定于域的聚合操作。一个例子是 “Tetrahedral Chirality” 聚合运算符。
8.5 GCN 作为子图函数近似器
使用 1 度邻居查找查看 k 层的 GCN(和 MPNN)的另一种方法是作为神经网络,该网络对大小为 k 的子图的学习嵌入进行操作。
当关注一个节点时,在 k 层之后,更新的节点表示具有所有邻居的有限视点,直到 k 距离,本质上是子图表示。边表示也是如此。
因此,GCN 正在收集所有可能的大小为 k 的子图,并从一个节点或边的有利位置学习向量表示。可能的子图的数量可以组合增长,因此从头开始枚举这些子图与像在 GCN 中那样动态构建它们可能会令人望而却步。
8.6 边和图形对偶
需要注意的一点是,边预测和节点预测虽然看起来不同,但通常归结为同一个问题:图$G$上的边预测任务可以表述为对的对偶的$G$节点级预测。
为了获得$G$的对偶,我们可以奖节点转换为边(将边转换为节点)。图形及其对偶包含相同的信息,只是以不同的方式表示。有时,此属性使一种表示中的问题比另一种表示中的问题更容易,例如傅里叶空间中的频率。 简而言之,要解决$G$上的边分类问题,可以考虑对$G$的dual 进行图卷积(这与$G$上的学习边表示相同),这个想法是用Dual-Primal Graph Convolutional Networks 开发的。
8.7 将图卷积作为矩阵乘法,将矩阵乘法作为在图上的游走
我们已经讨论了很多关于图卷积和消息传递的内容,当然,这就提出了一个问题,即我们如何在实践中实现这些操作?在本节中,我们将探讨矩阵乘法、消息传递及其与遍历图形的一些连接。
我们要说明的第一点是,具有大小$n_{\text {nodes }} \times node {\text {dim }}$为节点特征矩阵$X$的相邻矩阵$An{\text {nodes }} \times n_{\text {nodes }}$的矩阵乘法实现了使用求和聚合的简单消息传递。设矩阵为$B=AX$,我们可以观察到任何条目$B_{ij}$都可以表示为
$$
<A_{\text {row }{i}} \dot{X}{\text {column }{j}}>=A{i, 1} X_{1, j}+A_{i, 2} X_{2, j}+\ldots+A_{i, n} X_{n, j}=\sum_{A_{i, k}>0} X_{k, j}
$$
因为$A_{i,k}$只有当和$node_k$之间存在边时$node_i$,才为1,所以内积本质上是收集维度$j$的所有节点特征值,这些值与$node_i$共享一条边。应该注意的是,此消息传递不会更新节点特征的表示,而只是池化相邻节点特征。但是这可以通过在矩阵乘法之前或之后通过$X$你最喜欢的可微变换(例如MLP)来轻松适应。
从这个角度来看,我们可以体会到使用邻接列表的好处。由于对$A$预期的稀疏性 , 我们不必对$A_{i,j}$为0的所有值求和。只要我们有基于索引收集值的操作,我们应该能够只检索正条目。此外,这种无矩阵乘法使我们无需使用求和作为聚合运算。
我们可以想象,多次应用此操作可以让我们在更远的距离传播信息。从这个意义上说,矩阵乘法是遍历图的一种形式。当我们查看邻接矩阵的幂$A^K$时,这种关系也很明显。如果我们考虑矩阵$A^2$,项$A_{ij}^2$计算从$node_i$到$node_j$的所有长度为2的路径,并且可以表示为内积:
$$
<A_{\text {rou }{i}}, A_{\text {column }_{j}}>=A{i, 1} A_{1, j}+A_{i, 2} A_{2, j}+\ldots+A_{i, n} A_{n, j}
$$
直觉是,第一项$a_{i,1}a_{1,j}$仅在两个条件下为正,一条边连接$node_i$和$node_1$,另一条边连接$node_ 1$和$node_j$。换句话说,两条边形成一条长度为 2 的路径,该路径从$node_i$经过$node_1$连接到$node_j$。由于求和,我们正在计算所有可能的中间节点。当我们考虑$A^3=AA^2$时,这种直觉会延续下来以此类推至$A^k$。
关于我们如何将矩阵视为要探索的图形,存在更深层次的联系。
8.8 注意力网络
在 graph 属性之间传递信息的另一种方式是通过 attention。例如,当我们考虑一个节点及其 1 度相邻节点的和聚合时,我们也可以考虑使用加权和。然后,挑战在于以排列不变的方式关联权重。一种方法是考虑一个标量评分函数,该函数根据节点对$f(node_i,node_j)$分配权重。在这种情况下,评分函数可以解释为测量相邻节点与中心节点的相关性的函数。权重可以标准化,例如使用 softmax 函数将大部分权重集中在与任务相关的节点最相关的邻居上。这个概念是 Graph Attention Networks (GAT) 的基础保留排列不变性,因为评分适用于成对的节点。一个常见的评分函数是内积,在评分之前,通常会通过线性映射将节点转换为查询和关键向量,以提高评分机制的表达能力。此外,为了可解释性,评分权重可以用作衡量边缘相对于任务的重要性的度量。
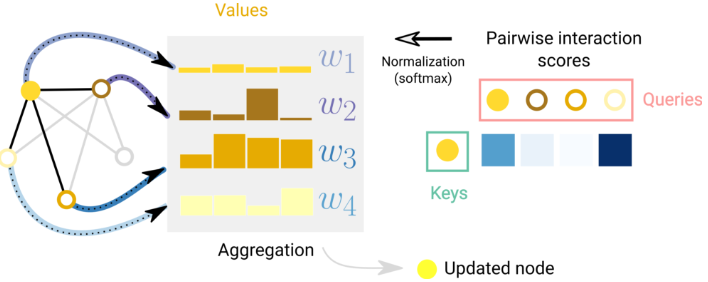
一个节点相对于其相邻节点的注意力示意图。对于每条边,都会计算、规范化交互分数,并用于对节点嵌入进行加权。
此外,Transformer可以被视为具有注意力机制的 GNN。在这个视图下,transformer 将几个元素(即字符标记)建模为全连接图中的节点,并且注意力机制为每个节点对分配边缘嵌入,用于计算注意力权重。区别在于实体之间连接的假设模式,GNN 假设稀疏模式,而 Transformer 对所有连接进行建模。
8.9 图表解释和归属
在直接部署 GNN 时,我们可能会关心模型的可解释性,以建立可信度、调试或科学发现。我们想要解释的图形概念因上下文而异。例如,对于分子,我们可能关心特定子图的存在与否,而在引文网络中,我们可能关心文章的关联程度。由于图形概念的多样性,构建解释的方法有很多种。GNNExplainer将此问题转换为提取对任务最重要的最相关的子图。归因技术将 Ranked importance 值分配给与任务相关的图表部分。由于可以综合生成现实且具有挑战性的图形问题,因此 GNN 可以作为评估归因技术的严格且可重复的测试平台。
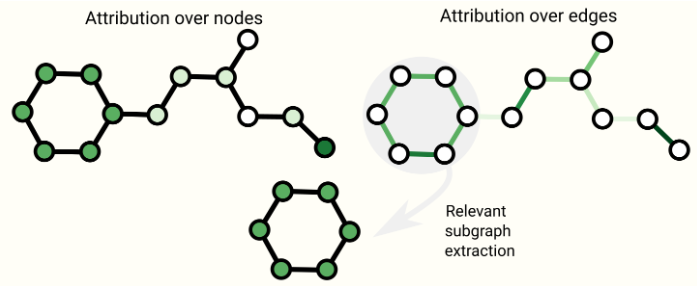
图表上的一些可解释性技术的示意图。归因将排名值分配给图表属性。排名可以用作提取可能与任务相关的连接子图的基础。
8.10 生成模型
除了学习图上的预测模型外,我们可能还关心学习图的生成模型。使用生成模型,我们可以通过从学习的分布中采样或通过完成给定起点的图形来生成新图形。一个相关的应用是新药的设计,其中需要具有特定特性的新型分子图作为治疗疾病的候选者。
图形生成模型的一个关键挑战在于对图形的拓扑进行建模,图形的大小可能会有很大差异并且有$N_{nodes}^2$项。一种解决方案是使用自动编码器框架直接对临界矩阵进行建模,就像对图像进行建模一样。对边缘是否存在的预测被视为二分类任务。可以通过仅预测已知边和不存在的边的子集来避免该$N_{nodes}^2$。graphVAE 学习对邻接矩阵中的正连接模式和一些非连接模式进行建模。
另一种方法是按顺序构建图形,从图形开始,然后迭代地应用离散操作,例如增加或减少节点和边缘。为了避免估计离散行动的梯度,我们可以使用策略梯度。这是通过自回归模型完成的,例如 RNN,或者在强化学习场景中。此外,有时可以将图形建模为仅包含语法元素的序列。
9 结论
图形是一种强大而丰富的结构化数据类型,其优势和挑战与图像和文本截然不同。在本文中,我们概述了研究人员在构建基于神经网络的图形处理模型时提出的一些里程碑。我们已经介绍了使用这些架构时必须做出的一些重要设计选择,希望 GNN playground 可以直观地了解这些设计选择的经验结果是什么。近年来 GNN 的成功为各种新问题创造了巨大的机会,我们很高兴看到该领域将带来什么。
 微信
微信 支付宝
支付宝