概率论第7章:参数估计
1 参数估计
设有一个统计总体, 总体的分布函数为$F(x, \theta)$,其中$\theta$为未知参数。$X_{1}, X_{2}, \cdots, X_{n}$是从总体X得到的样本,要根据该样本对参数$\theta$做出估计,或估计$\theta$的某个已知函数$g(\theta)$,这类问题成为参数估计。
已知总体的分布,来估计总体的参数。本章主要讲解参数估计中的点估计和区间估计。
2 点估计
2.1 点估计的概念
设总体X的分布函数$F(x ; \theta)$的形式已知,$\theta$是待估参数,$X_{1}, X_{2}, \cdots, X_{n}$是X的一个样本,$x_{1}, x_{2}, \cdots, x_{n}$是相应的样本值,用样本值估计参数值。
定义:构造一个适当的估计量$\hat{\theta}\left(X_{1}, X_{2}, \cdots, X_{n}\right)$,用它的观察值$\hat{\theta}\left(x_{1}, x_{2}, \cdots, x_{n}\right)$来估计未知参数$\theta$,称$\hat{\theta}\left(x_{1}, x_{2}, \cdots, x_{n}\right)$为$\theta$的估计量。这样的估计称为点估计。
寻求估计量的常用方法:
- 矩估计法
- 最大似然法
- 最小二乘法
- 贝叶斯方法
2.2 矩估计法
2.2.1 定义
矩估计法是英国统计学家K.皮尔逊最早提出的。该法以大数定律为理论依据,用样本矩估计总体矩。
定义:若 X为连续型随机变量其概率密度为
$$
f\left(x ; \theta_{1}, \theta_{2}, \cdots, \theta_{k}\right)
$$
若X为离散型随机变量,其分布律为
$$
P{X=x}=p\left(x ; \theta_{1}, \theta_{2}, \cdots, \theta_{k}\right)
$$
其中$\theta_{1}, \theta_{2}, \cdots, \theta_{k}$为待估参数,$X_{1}, X_{2}, \cdots, X_{n}$是来自总体X的样本。
假设总体X的前k阶矩存在,即
$$
\mu_{l}=E\left(X^{l}\right)=\int_{-\infty}^{+\infty} x^{l} f\left(x ; \theta_{1}, \theta_{2}, \cdots, \theta_{k}\right) d x \quad X 连续型
$$
$$
\mu_{l}=E\left(X^{l}\right)=\sum x^{l} p\left(x ; \theta_{1}, \theta_{2}, \cdots, \theta_{k}\right) \quad X 离散型
$$
用样本原点矩估计相应的总体原点矩,又用样本原点矩的连续函数估计相应的总体原点矩的连续函数,这种参数点估计法称为矩估计法。
2.2.2 估计步骤
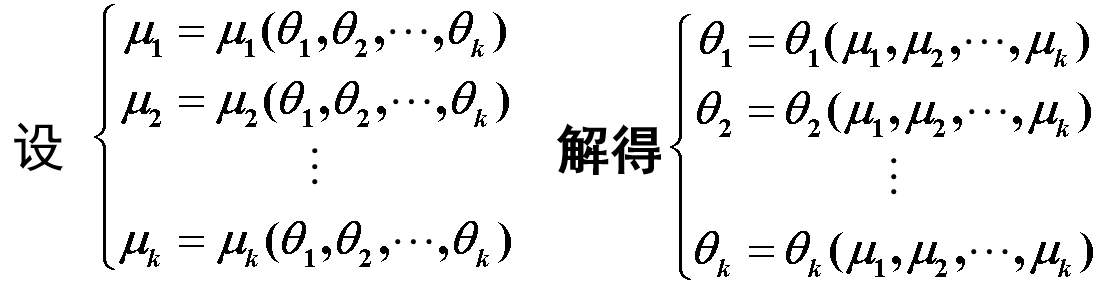
那么用各$\mu_{i}$的估计量$A_{i}$分别代替上式中的诸$\mu_{i}$,即可得到诸${\theta}_{j}$的矩估计量:
$$
\hat{\theta}_j=\theta_j(A_1,A_2,\cdots,A_k)\quad j=1,2,\cdots,k
$$
矩估计量的观察值称为矩估计值。
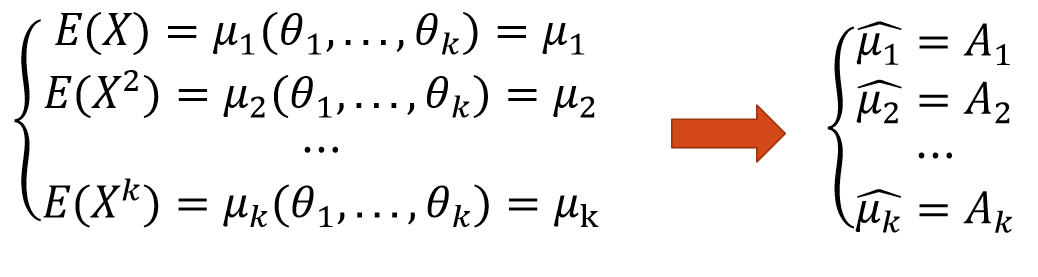
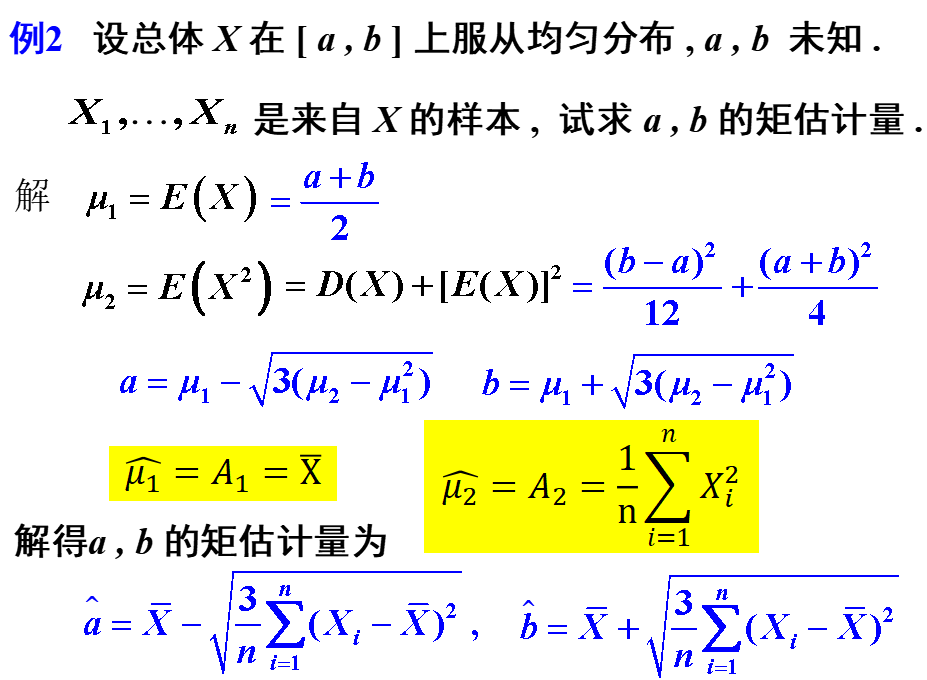
例1:设某炸药厂一天中发生着火现象的次数X,服从参数为$\lambda$的泊松分布,其中$\lambda$位置,用以下样本值,估计参数$\lambda
$。
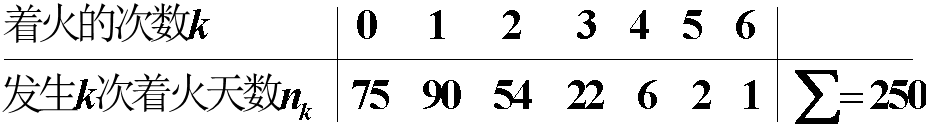
解:由于$X \sim \pi(\lambda), \quad \mu_{1}=E(X) \Longrightarrow A_{1}=\hat{\lambda}$,则$\lambda$的估计值如下:
$$
\hat{\lambda}=\bar{x}=\frac{1}{250}(0 \times 75+1 \times 90+\cdots+6 \times 1)=1.22
$$
2.3 最大似然估计法
它是在总体类型已知条件下使用的一种参数估计方法,它首先是由德国数学家高斯在1821年提出的,最大似然估计法,是建立在最大似然原理的基础上的求点估计量的方法。
2.3.1 最大似然估计原理
若X为连续型随机变量,密度函数为$f(x ; \theta), \theta \in \Theta$,当给定样本$X_{1}, X_{2}, \ldots, X_{n}$时,定义似然函数为:
$$
L(\theta)=L\left(x_{1}, x_{2}, \ldots, x_{n} ; \theta\right)=\prod_{i=1}^{n} f\left(x_{i} ; \theta \right)
$$
若$L(\hat{\theta})=\max _{\theta} L(\theta)$,则有以下:
- $\hat{\theta}\left(x_{1}, x_{2}, \ldots, x_{n}\right) 称为 \theta 的最大似然估计值$
- $\hat{\theta}\left(X_{1}, \ldots, X_{n}\right) 称为 \theta 的最大似然估计量$
最大似然原理的直观想法是:在试验中概率最大的事件最有可能出现。
2.3.2 最大似然估计量的一般步骤
(1)定义似然函数$
L(\theta)$
(2)一般地,求出$\ln L(\theta)$及似然方程
$$
\left.\frac{\partial \ln L(\theta)}{\partial \theta_{i}}\right|_{\theta=\hat{\theta}}=0 \quad(i={1 , 2}, \ldots, m)
$$
(3)解似然方程得到最大似然估计值
$$
\hat{\theta}_i=\hat{\theta}_i\left(x_1,x_2,\ldots,x_n\right)\quad(i={1},{2},\ldots,m)
$$
(4)最后得到最大似然估计量
$$
\hat{\theta}_i=\hat{\theta}_i\left(X_1,X_2,\ldots,X_n\right)\quad(i={1},{2},\ldots,m)
$$

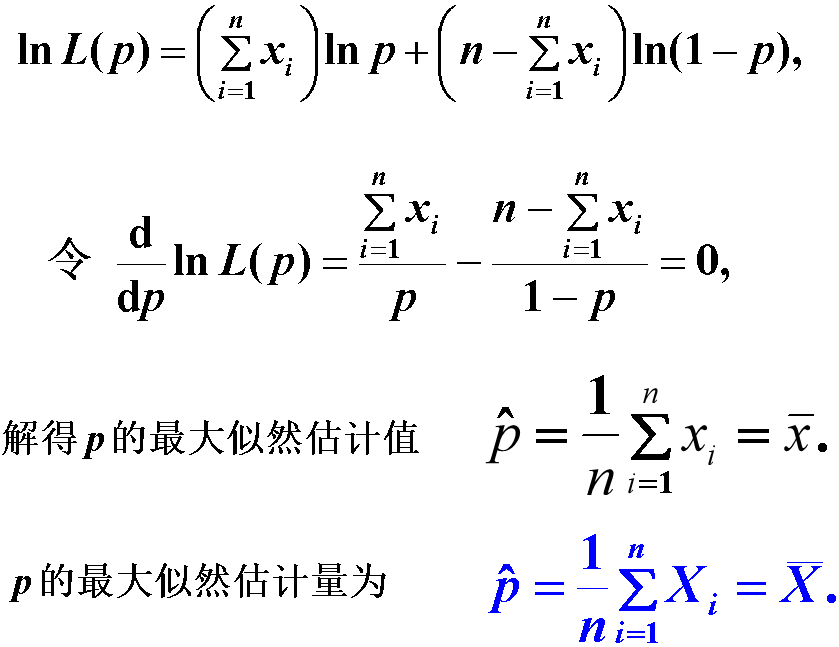
2.3.3 最大似然估计的不变性
若$\theta$估计值为$\hat{\theta}$,则$u=u(\theta)$估计值为$\hat{u}=u(\hat{\theta})$,条件是$u=u(\theta)$具有单值反函数$\theta=\theta(u)$。
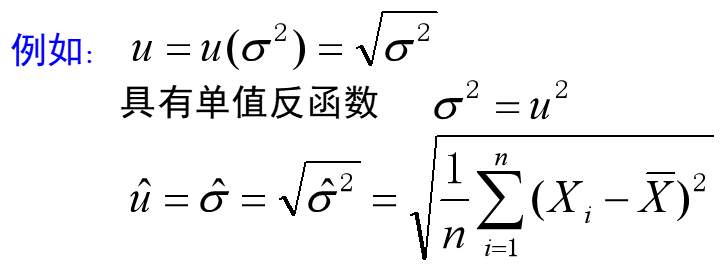
2.4 本节总结
点估计的概念
矩估计法概念及步骤
最大似然估计法概念及步骤
3 估计量的评选标准
3.1 无偏性
若估计量$\hat{\theta}=\theta\left(X_{1}, X_{2}, \cdots, X_{n}\right)$的数学期望$E(\hat{\theta})$对任意的$\theta \in \Theta$,都有$E(\hat{\theta})=\theta$,则称$\hat{\theta}$是$\theta$的无偏估计。无偏性就是求期望。
例如:$E(\bar{X})=\mu,E\left({S}^{\mathbf{2}}\right)={\sigma}^{\mathbf{2}}$。
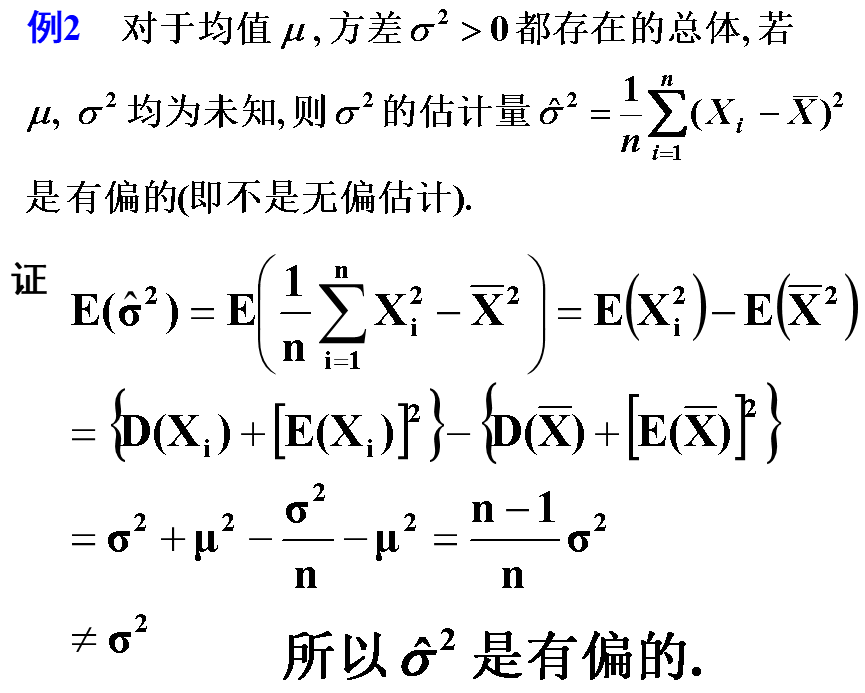



3.2 有效性
设$\hat{\boldsymbol{\theta}}_1=\hat{\boldsymbol{\theta}}_1(\boldsymbol{X}_1,\cdots,\boldsymbol{X}_n)$和$\hat{\boldsymbol{\theta}}_2=\hat{\boldsymbol{\theta}}_2(\boldsymbol{X}_1,\cdots,\boldsymbol{X}_n)$都是$\theta$的无偏估计量,若对任意$\theta \in \Theta$,有:
$$
D(\hat{\theta}_1) \leq D(\hat{\theta}_2)
$$
且至少对于某个$\theta \in \Theta$上式中的不等号成立,则称$\hat{\theta}_{1}$较$\hat{\theta}_2$有效。
- 有效性就是求方差
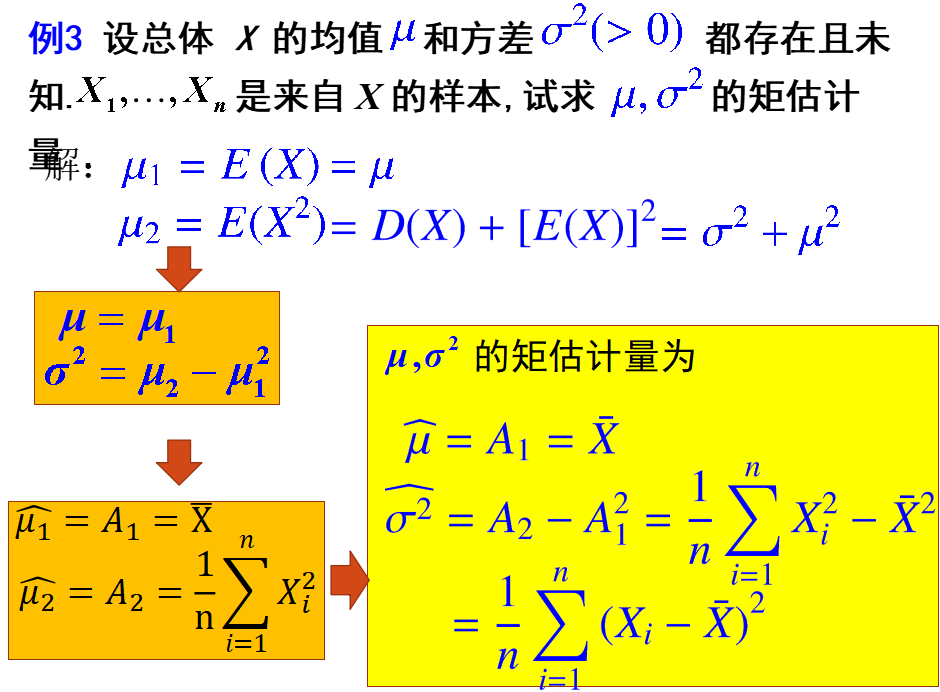
续例3:试证当n>1时,$\theta$的无偏估计量$\bar{X}$较nZ有效。

3.3 相合性
前面讲的无偏性和有效性都是在样本容量n固定的前提下提出的。希望随着样本容量的增大,一个估计量的值稳定于待估参数的真值。这样,对估计量有以下相合性的要求。
若$\hat{\theta}=\hat{\theta}\left(X_{1}, X_{2}, \cdots, X_{n}\right)$为参数$\theta$的估计量,若对于任意$\theta \in \Theta$,当$\boldsymbol{n} \rightarrow \infty$时,$\hat{\theta}=\hat{\theta}\left(X_{1}, X_{2}, \cdots, X_{n}\right)$依概率收敛于$\theta$,则称$\hat{\theta}$为$\theta$的相合估计量。
即对任意的$\varepsilon$有
$$
\lim _{n \rightarrow \infty} P{|\hat{\theta}-\theta|<\varepsilon}=1
$$
4 区间估计
4.1 置信区间定义
设$\theta$是一个待估参数,给定α>0,若由样本$X_{1}, X_{2}, \ldots, X_{n}$确定的两个统计量$\underline{\theta}=\underline{\theta}\left(X_{1}, X_{2}, \cdots, X_{n}\right)$和$\bar{\theta}=\bar{\theta}\left(X_{1}, X_{2}, \cdots, X_{n}\right)$,其中$\underline{\theta}<\bar{\theta}$,满足:
$$
P{\underline{\theta}<\theta<\bar{\theta}} \geq 1-\alpha
$$
则称区间$(\underline{\theta}, \bar{\theta})$是$\theta$的置信水平(置信度)为1-α的置信区间。其中,$\underline{\theta} 和 \bar{\theta} $分别称为置信下限和置信上限。

4.2 置信区间的求法
(1)寻找参数$\theta$的一个良好的点估计$T\left(X_{1}, X_{2}, \ldots X_{n}\right)$
(2)寻找一个待估参数$\theta$和估计量T的函数$U(T, \theta)$,且其分布为已知
(3)对于给定的置信水平1-α,根据$U(T, \theta)$的分布,确定常熟a, b,使得
$$
\boldsymbol{P}(\boldsymbol{a}<\boldsymbol{U}(T, \boldsymbol{\theta})<\boldsymbol{b})=1-\alpha
$$
解得$P{\underline{\theta}<\theta<\bar{\theta}}=1-\alpha$。

5 正态总体均值与方差的区间估计
设已给定置信水平为1-α,并设$X_{1}, X_{2}, \ldots, X_{n}$为总体$N\left(\mu, \sigma^{2}\right)$的样本,$\bar{X}, S^{2}$分别是样本均值和样本方差。
5.1 均值$\mu$的置信区间
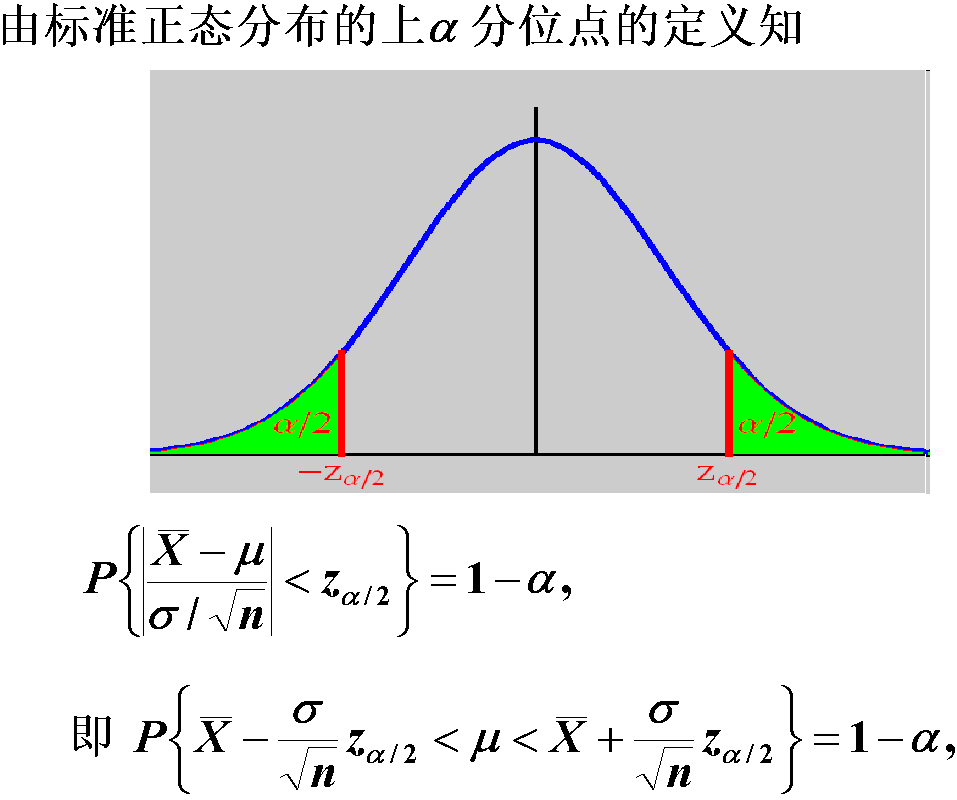
5.1.1 方差$\sigma^{2}$已知
$\mu$的置信水平为1-α的置信区间为$\left(\bar{X} \pm \frac{\sigma}{\sqrt{n}} z_{\alpha / 2}\right)$
5.1.2 方差$\sigma^{2}$未知


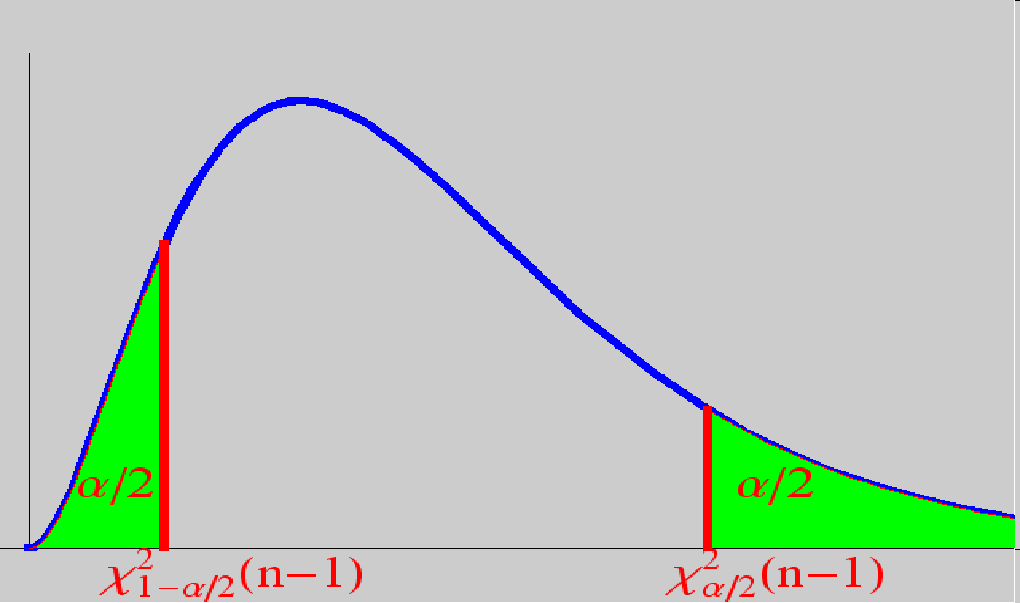
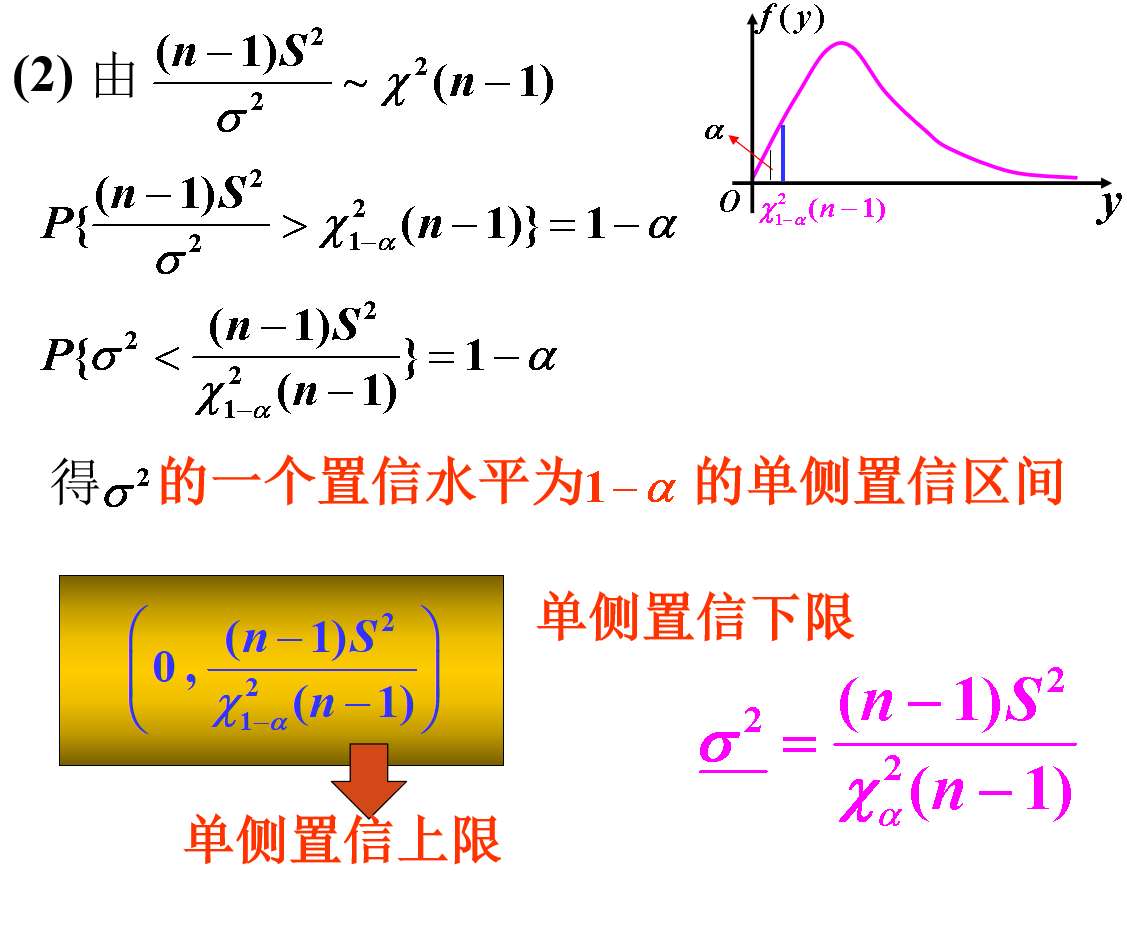
5.2 方差$\sigma^{2}$的置信区间
此处,根据实际问题的需要,只介绍$\mu$未知的情况。

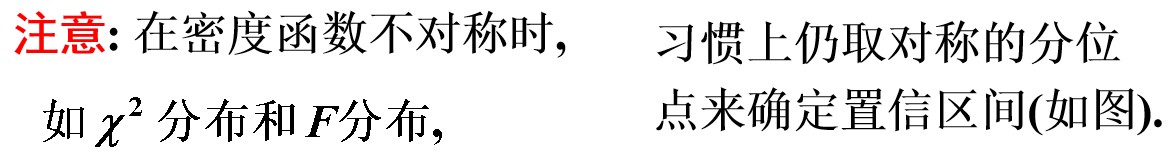
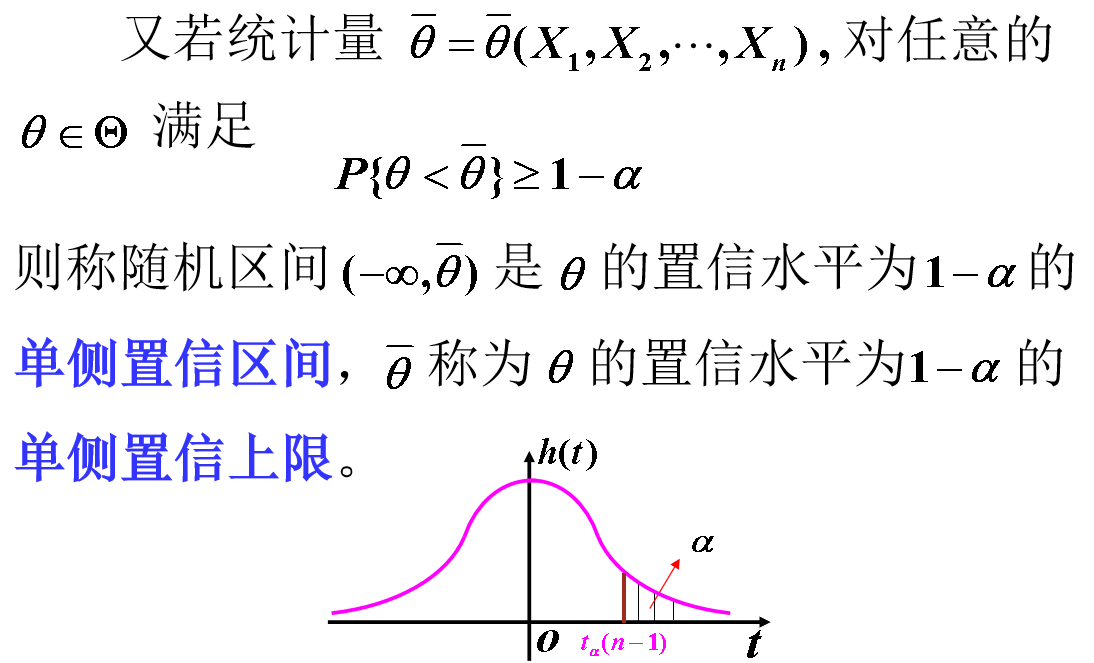
6 单侧置信区间



7 本章总结
- 点估计:熟练使用矩估计法和最大似然估计法进行参数的点估计;
- 掌握估计量的评选标准:无偏性、有效性和相合性;
- 熟练进行正态总体参数的区间估计(包括单侧和双侧)。
 微信
微信 支付宝
支付宝